Clear Sky Science · de
SVRS: selbstüberwachtes 3D-Voxel-Rekonstruktionsnetzwerk aus Stereo-Vision
Die Welt in 3D sehen für sicherere Roboter
Autonome Fahrzeuge und Serviceroboter müssen die Form ihrer Umgebung in drei Dimensionen erfassen, um Kollisionen zu vermeiden und sicher zu navigieren. Diese Studie stellt einen schnelleren und genaueren Weg vor, wie Paare gewöhnlicher Kamerabilder in eine detaillierte 3D-Gitterkarte naher Objekte umgewandelt werden können — ein Ansatz, der künftige Roboter zuverlässiger machen könnte, ohne teure Lasersensoren zu benötigen.
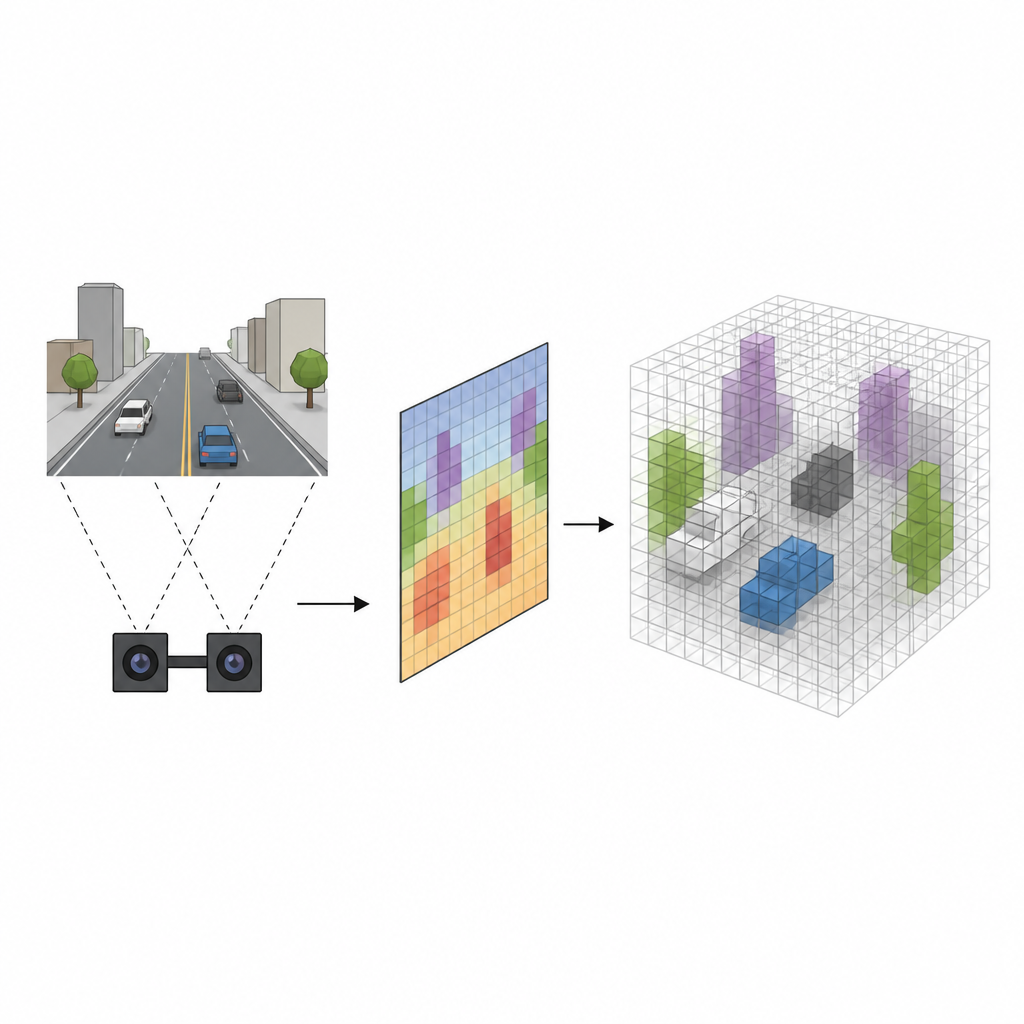
Von flachen Bildern zu solidem Raum
Viele Roboter verwenden Stereo-Kameras, die eine Szene aus zwei leicht unterschiedlichen Blickwinkeln betrachten, ähnlich wie unsere Augen. Traditionelle Systeme schätzen zunächst die Entfernung jedes Pixels zur Kamera und projizieren dann jedes Pixel in den 3D‑Raum, um ein Gitter aus winzigen Würfeln, sogenannten Voxeln, zu füllen, die markieren, wo sich Objekte befinden könnten. Obwohl diese Methode funktioniert, ist sie langsam und neigt dazu, Kanten zu verwischen, wodurch leere Bereiche fälschlich als belegt angezeigt werden. Der neue Ansatz, SVRS genannt, überspringt diese aufwändige Pixel-für-Pixel-Projektion und lernt stattdessen eine direktere Verbindung zwischen dem, was die Kameras sehen, und welchen Würfeln im Raum tatsächlich gefüllt sind.
Das Netzwerk dazu bringen, in Würfeln zu denken
Die Forschenden stellen den Bereich vor einem Fahrzeug als Stapel gleichförmiger Würfel dar, die zusammen ein 3D‑Gitter bilden. Anstatt von Pixeln auszugehen und diese in den Raum zu schieben, beginnt ihr Pixel‑Voxel‑Projecting‑Modul bei jedem Würfel und fragt, wo er in den Kamerabildern erscheinen würde. Unter Verwendung der bekannten Geometrie der Stereo‑Kameras projiziert das Modul jeden Würfel zurück in die beiden Bilder und sampelt die reichhaltigen internen Merkmale, die moderne Stereo‑Netzwerke berechnen. Das verwandelt dichte Bildinformationen in ein sparsames 3D‑Signal, das direkt an jeden Würfel gebunden ist, wodurch nutzlose Arbeit in leeren Regionen entfällt und die Kantenverwischung, die zu Fehlalarmen führt, reduziert wird.
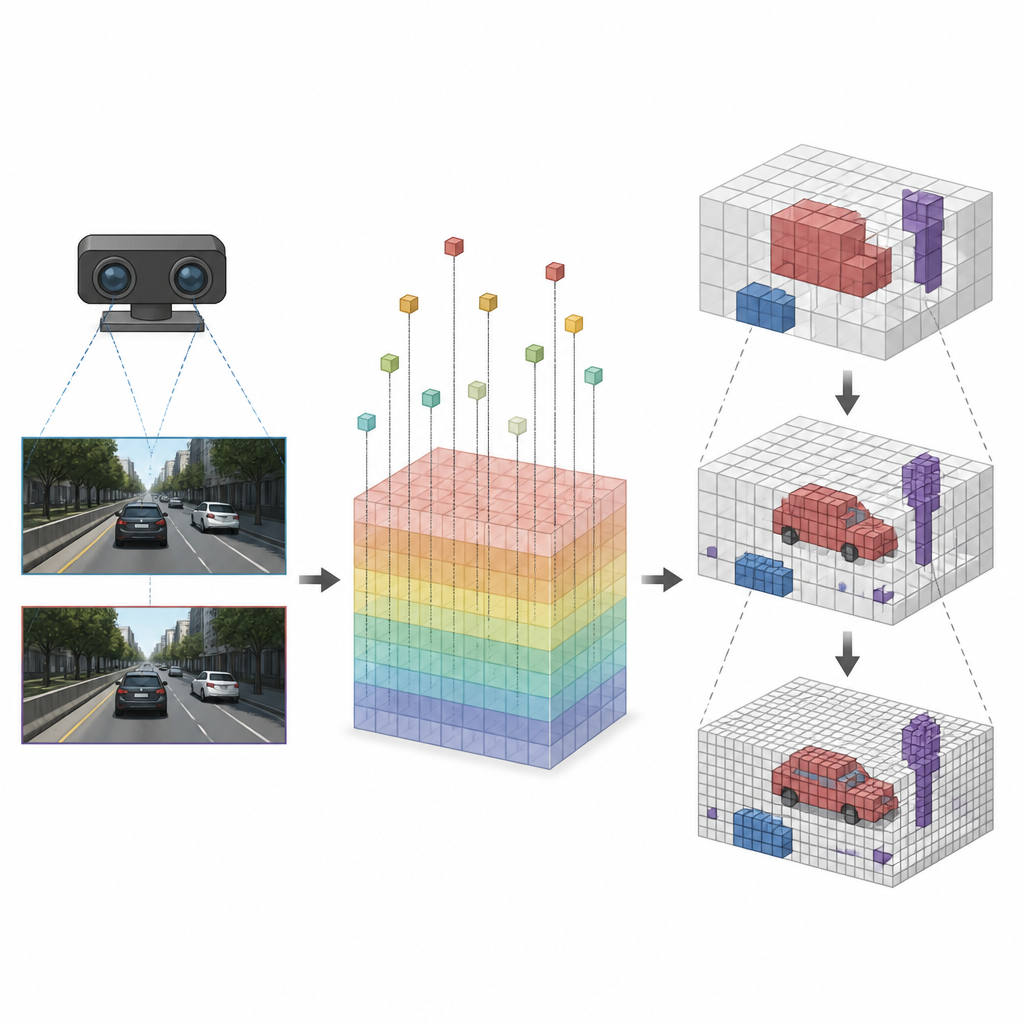
Details dort fokussieren, wo sie zählen
Sobald jeder Würfel mit den passenden Bildmerkmalen verknüpft ist, wendet SVRS eine auf Oktalbäumen basierende Encoder‑Decoder‑Architektur an, um zu entscheiden, welche Würfel belegt sind. Die Idee ist, mit einer groben Ansicht der Szene zu beginnen und diese dann Schritt für Schritt zu verfeinern. Auf jeder Ebene sagt das Netzwerk voraus, welche großen Würfel etwas enthalten, und nutzt diese Information, um die nächste, feinere Ebene zu leiten, wobei nur vielversprechende Regionen im Detail untersucht werden. Leere Bereiche werden früh unterdrückt, damit sie das Netzwerk beim Hereinzoomen nicht überwältigen. Diese Grob‑zu‑Fein‑Strategie hält die Berechnungen auf Autos, Straßenkanten und andere wichtige Objekte fokussiert, anstatt Rechenaufwand auf freie Luft zu verschwenden.
Vom bestehenden Sensorprompt lernen, ohne manuelle Labels
Zum Training des Systems vermeiden die Autoren die kostspielige Aufgabe, 3D‑Szenen händisch zu beschriften. Stattdessen nutzen sie Tiefenkarten und Punktwolken, die von leistungsfähigen bestehenden Stereo‑ und Laser‑basierten Methoden erzeugt werden, als Lehrsignale. Sie bereinigen Stereo‑Tiefen mit einem einfachen Kantendetektor, bevor sie diese in ein 3D‑Gitter umwandeln, und experimentieren zudem damit, direkt gegen Laser‑Messungen zu trainieren. Dieses selbstüberwachte Setup erlaubt es dem Netzwerk, hochwertige 3D‑Daten zu imitieren, während es zur Laufzeit deutlich leichter und schneller bleibt — praktisch für eingebettete Rechner in Fahrzeugen.
Schnellere und sauberere 3D‑Ansichten für fahrende Maschinen
Tests an einem großen Fahrdatensatz zeigen, dass SVRS 3D‑Gitter genauso präzise rekonstruiert wie führende stereo‑basierte Methoden, dabei aber gegenüber einigen starken Baselines bis zu vierzehnmal schneller und gegenüber anderen Echtzeitsystemen etwa dreimal schneller läuft. Es meldet seltener fälschlich belegten Raum, kann allerdings einige kleine Objekte übersehen — ein Trade‑off zwischen Vorsicht und Vollständigkeit. Für den Laien ist die Kernbotschaft: Die Methode hilft Maschinen, Kamerabilder in ein klareres, effizienteres 3D‑Bild der Straße vor ihnen zu verwandeln, ein wichtiger Schritt zu sichereren und leistungsfähigeren autonomen Fahrzeugen und Robotern.
Zitation: Zou, Z., Wu, Y., Zhang, H. et al. SVRS: self-supervised 3D voxel reconstruction network from stereo vision. Sci Rep 16, 15548 (2026). https://doi.org/10.1038/s41598-026-45924-0
Schlüsselwörter: Stereo‑Vision, 3D‑Rekonstruktion, Voxel‑Gitter, Autonomes Fahren, Roboterwahrnehmung