Clear Sky Science · it
SVRS: rete di ricostruzione voxel 3D auto-supervisionata dalla visione stereo
Vedere il mondo in 3D per robot più sicuri
Le auto a guida autonoma e i robot di servizio devono comprendere la forma del mondo circostante in tre dimensioni per evitare collisioni e muoversi in sicurezza. Questo studio introduce un modo più veloce e accurato per convertire coppie di immagini da normali telecamere in una mappa 3D dettagliata a griglia degli oggetti vicini, potenzialmente rendendo i robot futuri più affidabili senza la necessità di costosi sensori laser.
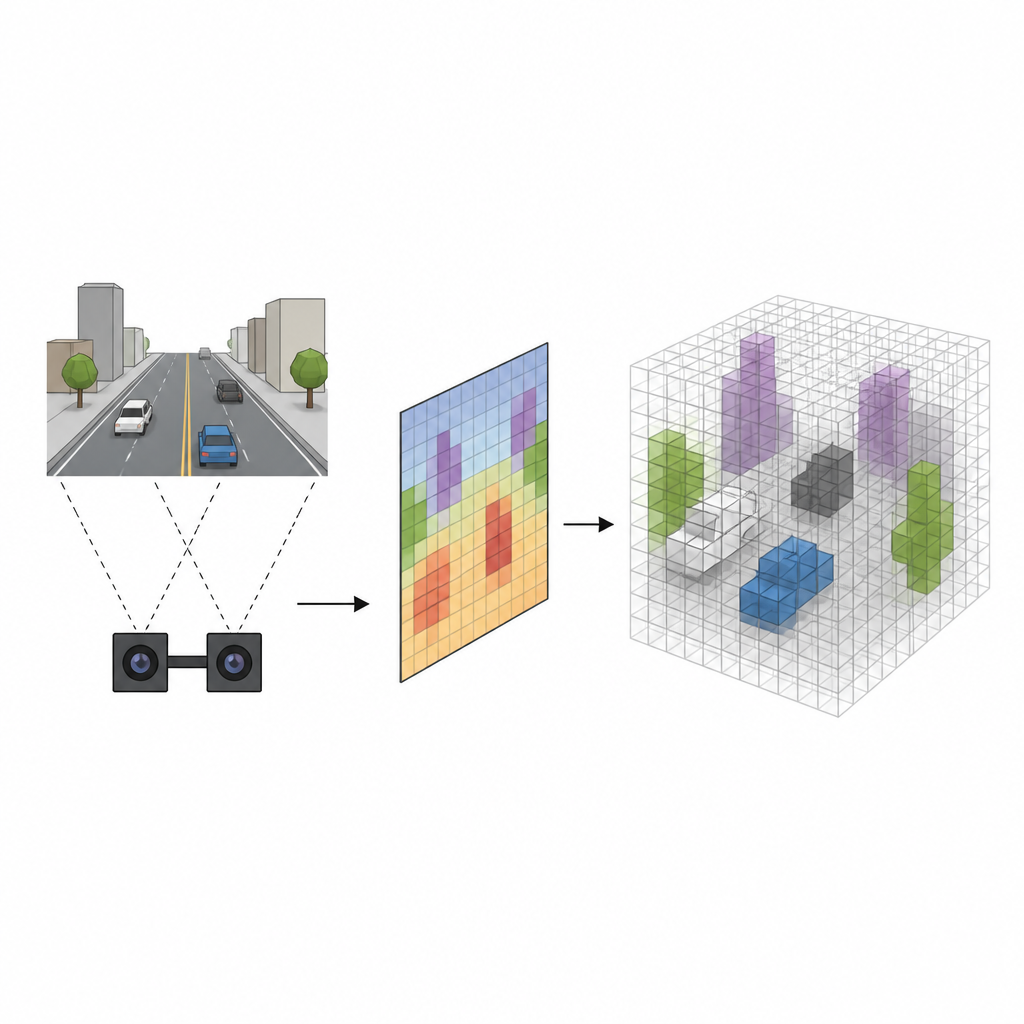
Dalle immagini piatte allo spazio solido
Molti robot usano telecamere stereo, che osservano una scena da due punti di vista leggermente diversi, proprio come i nostri occhi. I sistemi tradizionali stimano prima la distanza di ogni pixel dalla camera e poi proiettano ogni pixel nello spazio 3D, riempiendo una griglia di minuscoli cubi chiamati voxel che segnalano dove gli oggetti potrebbero trovarsi. Sebbene questo metodo funzioni, è lento e tende a sfumare i contorni degli oggetti, creando falsi allarmi dove lo spazio vuoto è erroneamente marcato come occupato. Il nuovo approccio, chiamato SVRS, salta questa pesante proiezione pixel per pixel e impara invece una connessione più diretta tra ciò che le camere vedono e quali cubi nello spazio sono effettivamente pieni.
Insegnare alla rete a pensare per cubi
I ricercatori rappresentano l’area davanti a un veicolo come una pila di cubi uniformi che insieme formano una griglia 3D. Anziché partire dai pixel e spingerli nello spazio, il loro Modulo di Proiezione Pixel-Voxel parte da ogni cubo e chiede dove apparirebbe nelle immagini delle camere. Utilizzando la geometria nota delle camere stereo, il modulo proietta ogni cubo indietro nelle due immagini e campiona le ricche caratteristiche interne che le moderne reti stereo calcolano. Questo trasforma l’informazione densa dell’immagine in un segnale 3D sparso legato direttamente a ciascun cubo, eliminando lavoro inutile nelle regioni vuote e riducendo la sfocatura dei bordi che causa falsi positivi.
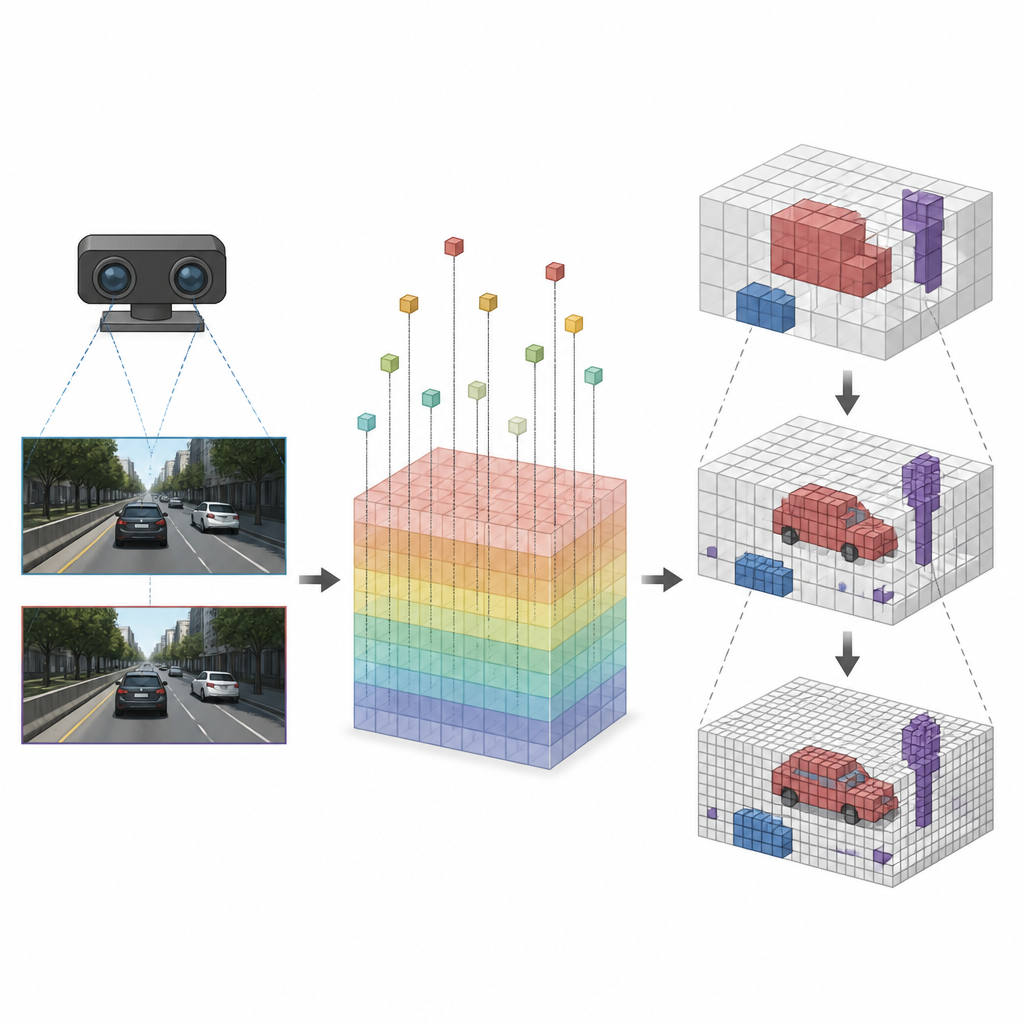
Concentrare i dettagli dove conta
Una volta che ogni cubo è stato collegato alle giuste caratteristiche d’immagine, SVRS applica un’architettura encoder-decoder basata su Octree per decidere quali cubi sono occupati. L’idea è partire da una visione grossolana della scena e poi raffinarla passo dopo passo. A ogni livello, la rete predice quali grandi cubi contengono qualcosa e usa quell’informazione per guidare il livello successivo, più fine, dove vengono esaminate in dettaglio solo le regioni promettenti. Le aree vuote vengono soppresse precocemente in modo da non sovraccaricare la rete mentre ingrandisce. Questa strategia dal grosso al fine mantiene i calcoli concentrati su automobili, bordi della strada e altri oggetti importanti invece di sprecare risorse sull’aria aperta.
Imparare dai sensori esistenti senza etichette manuali
Per addestrare il sistema, gli autori evitano il compito costoso di etichettare manualmente scene 3D. Invece, usano mappe di profondità e nuvole di punti prodotte da forti metodi esistenti basati su stereo e laser come segnali di insegnamento. Puliscano la profondità stereo con un semplice rilevatore di bordi prima di trasformarla in una griglia 3D, e sperimentano anche l’addestramento direttamente contro misure laser. Questo setup auto-supervisionato permette alla rete di imitare dati 3D di alta qualità pur rimanendo molto più leggera e veloce in esecuzione, rendendola pratica per computer embedded sui veicoli.
Visioni 3D più veloci e più pulite per macchine in movimento
I test su un ampio dataset di guida mostrano che SVRS ricostruisce griglie 3D con accuratezza paragonabile ai migliori metodi basati su stereo, funzionando fino a quattordici volte più velocemente rispetto ad alcuni forti baseline e circa tre volte più veloce rispetto ad altri sistemi in tempo reale. Fa meno affermazioni erronee che lo spazio vuoto sia occupato, anche se può perdere alcuni oggetti piccoli, riflettendo un bilanciamento tra cautela e completezza. Per un lettore non tecnico, il messaggio chiave è che il metodo aiuta le macchine a trasformare le immagini delle camere in un quadro 3D della strada più chiaro ed efficiente, un passo importante verso veicoli e robot autonomi più sicuri e capaci.
Citazione: Zou, Z., Wu, Y., Zhang, H. et al. SVRS: self-supervised 3D voxel reconstruction network from stereo vision. Sci Rep 16, 15548 (2026). https://doi.org/10.1038/s41598-026-45924-0
Parole chiave: visione stereo, ricostruzione 3D, griglia di voxel, guida autonoma, percezione robotica