Clear Sky Science · en
SVRS: self-supervised 3D voxel reconstruction network from stereo vision
Seeing the World in 3D for Safer Robots
Self-driving cars and service robots must understand the shape of the world around them in three dimensions to avoid collisions and navigate safely. This study introduces a faster and more accurate way to convert pairs of ordinary camera images into a detailed 3D grid map of nearby objects, potentially making future robots more reliable without needing expensive laser sensors.
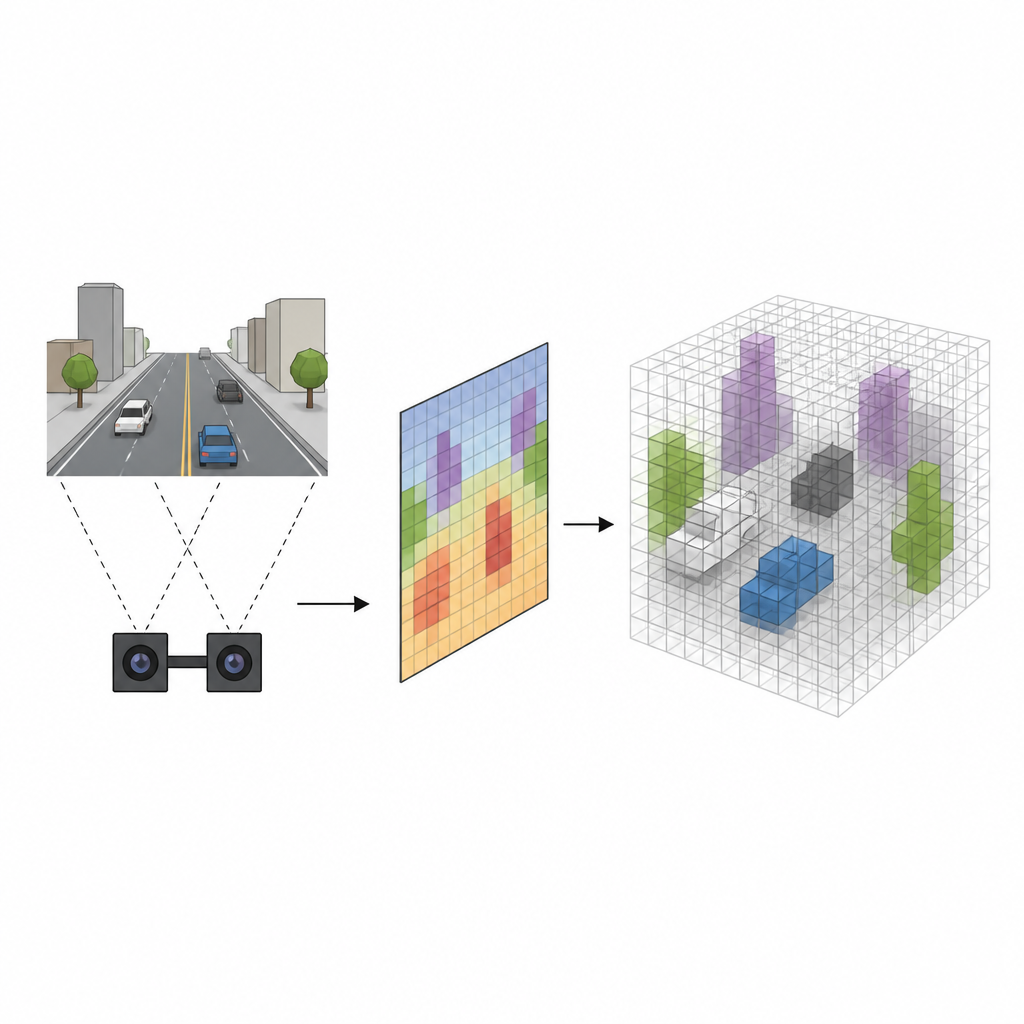
From Flat Pictures to Solid Space
Many robots use stereo cameras, which look at a scene from two slightly different viewpoints, much like our eyes. Traditional systems first estimate how far every pixel is from the camera and then project each pixel into 3D space, filling a grid of tiny cubes called voxels that mark where objects might be. While this method works, it is slow and tends to blur the edges of objects, creating false alarms where empty space is wrongly marked as occupied. The new approach, called SVRS, skips this heavy pixel by pixel projection and instead learns a more direct connection between what the cameras see and which cubes in space are actually filled.
Teaching the Network to Think in Cubes
The researchers represent the area in front of a vehicle as a stack of uniform cubes that together form a 3D grid. Rather than starting from pixels and pushing them outward into space, their Pixel Voxel Projecting Module starts from each cube and asks where it would appear in the camera images. Using the known geometry of the stereo cameras, the module projects each cube back into the two images and samples the rich internal features that modern stereo networks compute. This turns dense picture information into a sparse 3D signal tied directly to each cube, cutting away useless work in empty regions and reducing the edge blurring that causes false positives.
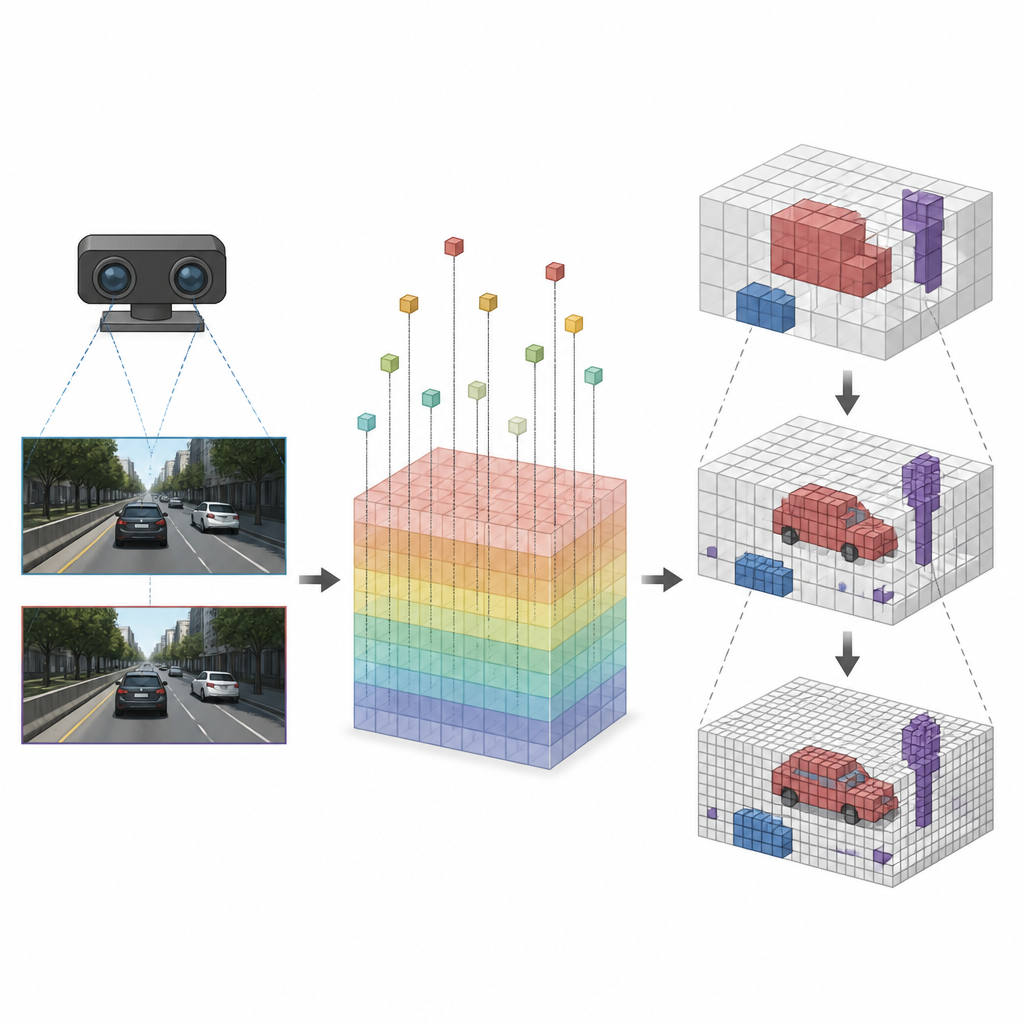
Focusing Detail Where It Matters
Once every cube has been linked to the right image features, SVRS applies an Octree based Encoder Decoder Architecture to decide which cubes are occupied. The idea is to start with a coarse view of the scene and then refine it step by step. At each level, the network predicts which large cubes contain something and uses that information to guide the next, finer level, where only promising regions are examined in detail. Empty areas are suppressed early so they do not overwhelm the network as it zooms in. This coarse to fine strategy keeps the calculations focused on cars, road edges, and other important objects instead of wasting effort on open air.
Learning from Existing Sensors Without Manual Labels
To train the system, the authors avoid the costly task of hand labeling 3D scenes. Instead, they use depth maps and point clouds produced by strong existing stereo and laser based methods as teaching signals. They clean up stereo depth with a simple edge detector before turning it into a 3D grid, and they also experiment with training directly against laser measurements. This self supervised setup lets the network imitate high quality 3D data while still being much lighter and faster at run time, making it practical for embedded computers in vehicles.
Faster and Cleaner 3D Views for Moving Machines
Tests on a large driving dataset show that SVRS reconstructs 3D grids as accurately as leading stereo based methods while running up to fourteen times faster than some strong baselines and about three times faster than other real time systems. It makes fewer false claims that empty space is occupied, though it can miss some small objects, reflecting a balance between caution and completeness. For a lay reader, the key message is that the method helps machines turn camera images into a clearer, more efficient 3D picture of the road ahead, which is an important step toward safer and more capable autonomous vehicles and robots.
Citation: Zou, Z., Wu, Y., Zhang, H. et al. SVRS: self-supervised 3D voxel reconstruction network from stereo vision. Sci Rep 16, 15548 (2026). https://doi.org/10.1038/s41598-026-45924-0
Keywords: stereo vision, 3D reconstruction, voxel grid, autonomous driving, robot perception