Clear Sky Science · pl
SVRS: samoucąca sieć rekonstrukcji 3D w wokselach ze stereowizji
Postrzeganie świata w 3D dla bezpieczniejszych robotów
Samochody autonomiczne i roboty usługowe muszą rozumieć kształt otoczenia w trzech wymiarach, aby unikać kolizji i poruszać się bezpiecznie. W tym badaniu przedstawiono szybszy i dokładniejszy sposób przekształcania par zwykłych obrazów kamerowych w szczegółową trójwymiarową siatkę wokseli przedstawiającą pobliskie obiekty, co może sprawić, że przyszłe roboty będą bardziej niezawodne bez konieczności używania drogich czujników laserowych.
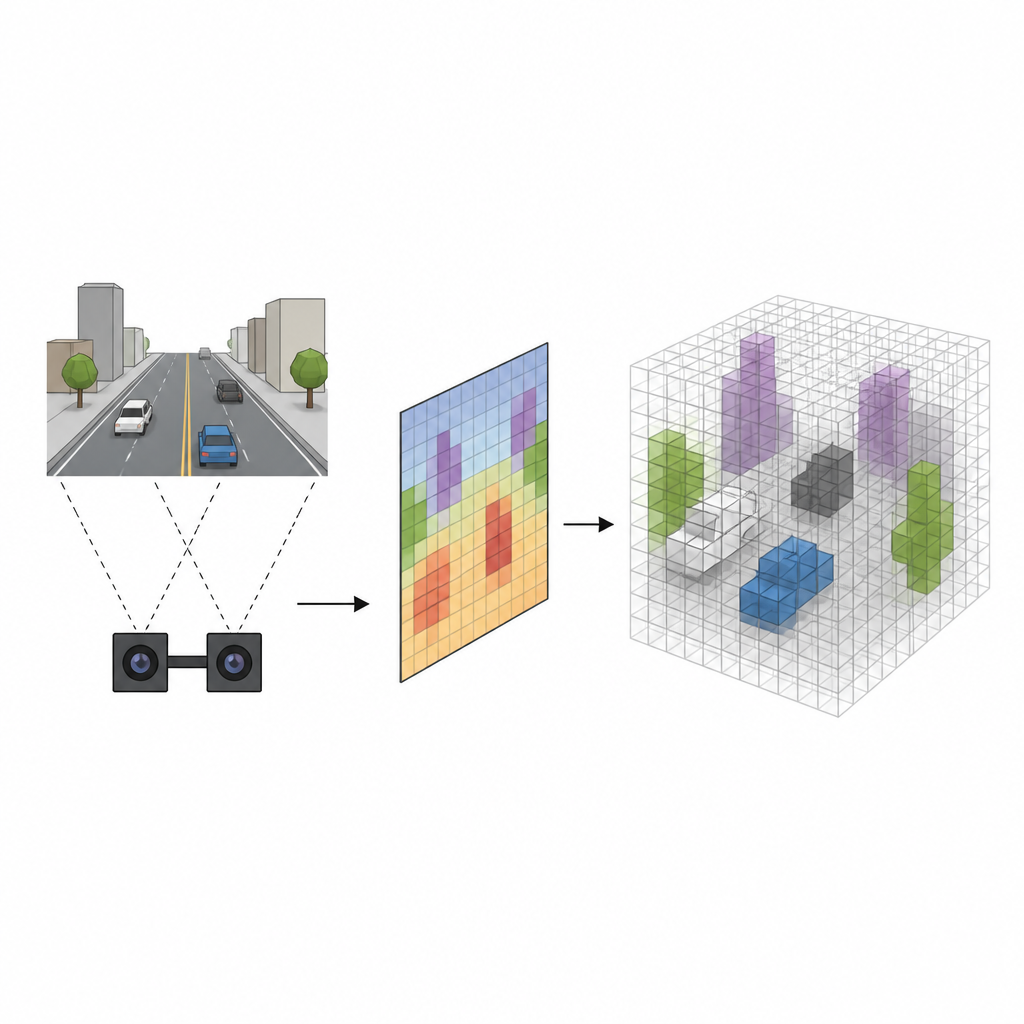
Z płaskich obrazów do zwartej przestrzeni
Wiele robotów korzysta z kamer stereoskopowych, które oglądają scenę z dwóch nieco różnych punktów widzenia, podobnie jak nasze oczy. Tradycyjne systemy najpierw szacują odległość każdego piksela od kamery, a następnie projekcją odwzorowują piksele w przestrzeni 3D, wypełniając siatkę małych sześcianów zwanych wokselami, które oznaczają możliwe położenie obiektów. Chociaż ta metoda działa, jest wolna i ma tendencję do rozmywania krawędzi obiektów, wywołując fałszywe alarmy tam, gdzie pusta przestrzeń zostaje błędnie oznaczona jako zajęta. Nowe podejście, nazwane SVRS, pomija tę kosztowną projekcję piksel po pikselu i zamiast tego uczy się bardziej bezpośredniego powiązania między tym, co widzą kamery, a tym, które komórki przestrzeni są rzeczywiście wypełnione.
Nauczanie sieci myślenia w sześcianach
Naukowcy reprezentują obszar przed pojazdem jako stos równych sześcianów tworzących trójwymiarową siatkę. Zamiast zaczynać od pikseli i rozpraszać je w przestrzeni, ich moduł Pixel Voxel Projecting zaczyna od każdego sześcianu i pyta, gdzie pojawiłby się on na obrazach kamer. Wykorzystując znaną geometrię kamer stereoskopowych, moduł projektuje każdy sześcian z powrotem na oba obrazy i próbuje wewnętrznych, bogatych cech, które obliczają nowoczesne sieci stereowizyjne. To przekształca gęstą informację z obrazu w rzadki sygnał 3D powiązany bezpośrednio z każdym sześcianem, eliminując zbędną pracę w pustych obszarach i zmniejszając rozmycie krawędzi, które powoduje fałszywe pozytywy.
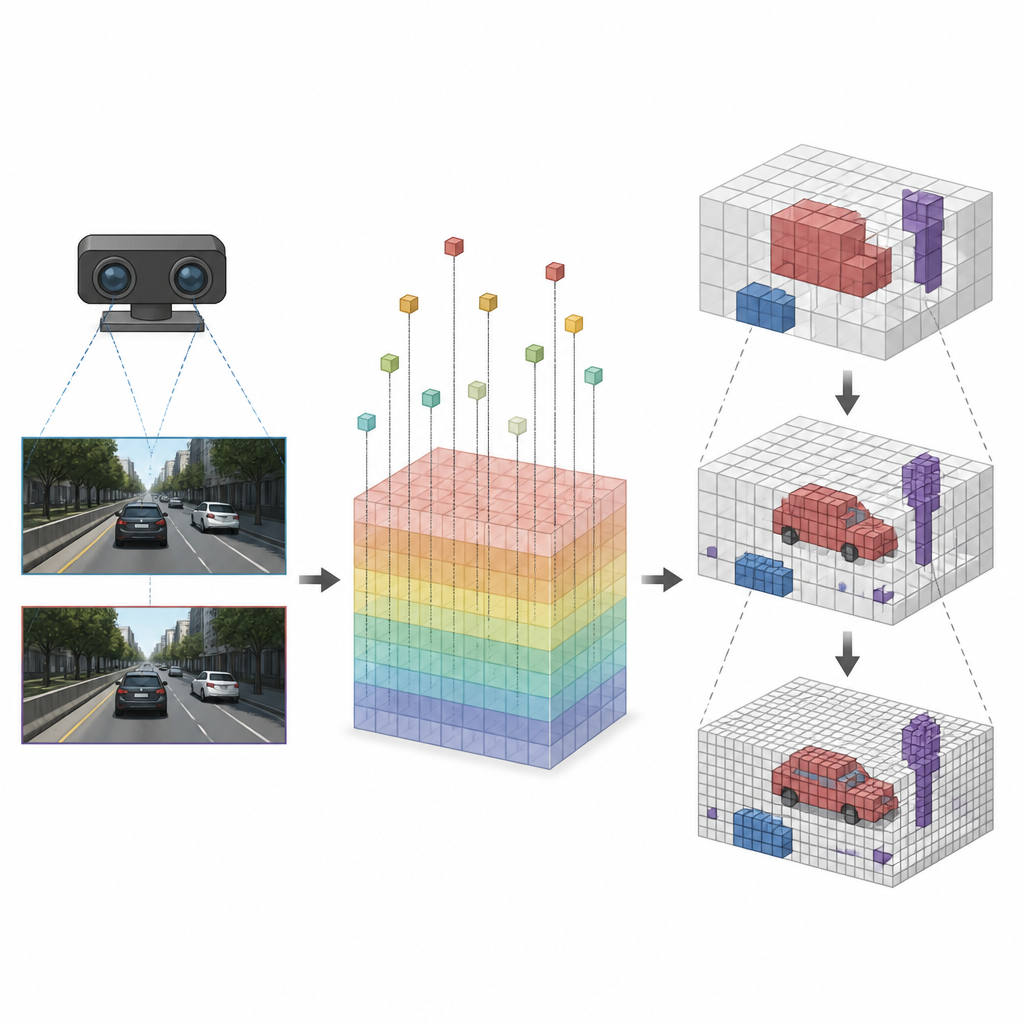
Skupianie szczegółów tam, gdzie to ważne
Gdy każdy sześcian zostanie powiązany z odpowiednimi cechami obrazu, SVRS stosuje architekturę enkodera-dekodera opartą na oktree, aby zdecydować, które sześciany są zajęte. Idea polega na rozpoczęciu od grubego obrazu sceny, a następnie stopniowym jego doprecyzowywaniu. Na każdym poziomie sieć przewiduje, które duże bloki zawierają coś i wykorzystuje tę informację do pokierowania kolejnym, bardziej szczegółowym poziomem, gdzie tylko obiecujące regiony są dokładnie analizowane. Puste obszary są tłumione wcześnie, aby nie przytłaczały sieci podczas zagłębiania się w szczegóły. Ta strategia od ogółu do szczegółu utrzymuje obliczenia skoncentrowane na samochodach, krawędziach drogi i innych ważnych obiektach, zamiast marnować wysiłek na pustą przestrzeń.
Nauka z istniejących czujników bez ręcznych etykiet
Aby wytrenować system, autorzy unikają kosztownego zadania ręcznego oznaczania scen 3D. Zamiast tego używają map głębi i chmur punktów generowanych przez solidne istniejące metody stereowizyjne i laserowe jako sygnałów uczących. Oczyszczają głębię stereowizyjną za pomocą prostego detektora krawędzi, zanim przekształcą ją w siatkę 3D, a także eksperymentują z bezpośrednim treningiem względem pomiarów laserowych. To samonadzorowane ustawienie pozwala sieci naśladować wysokiej jakości dane 3D, pozostając jednocześnie znacznie lżejszą i szybszą w czasie działania, co czyni ją praktyczną dla wbudowanych komputerów w pojazdach.
Szybsze i czyściejsze widoki 3D dla poruszających się maszyn
Testy na dużym zbiorze danych z jazdy pokazują, że SVRS rekonstruuje siatki 3D z taką samą dokładnością jak wiodące metody stereowizyjne, jednocześnie działając do czternastu razy szybciej niż niektóre mocne punkty odniesienia i około trzykrotnie szybciej niż inne systemy czasu rzeczywistego. Generuje mniej błędnych oznaczeń pustej przestrzeni jako zajętej, choć może pominąć niektóre małe obiekty, co odzwierciedla kompromis między ostrożnością a kompletnością. Dla czytelnika popularnonaukowego kluczowym przesłaniem jest to, że metoda pomaga maszynom przekształcać obrazy kamerowe w jaśniejszy, bardziej efektywny obraz 3D drogi przed nimi, co jest ważnym krokiem w kierunku bezpieczniejszych i bardziej zdolnych pojazdów autonomicznych oraz robotów.
Cytowanie: Zou, Z., Wu, Y., Zhang, H. et al. SVRS: self-supervised 3D voxel reconstruction network from stereo vision. Sci Rep 16, 15548 (2026). https://doi.org/10.1038/s41598-026-45924-0
Słowa kluczowe: stereowizja, rekonstrukcja 3D, siatka wokseli, autonomiczna jazda, percepcja robotów