Clear Sky Science · fr
SVRS : réseau de reconstruction voxel 3D auto-supervisé à partir de la vision stéréo
Voir le monde en 3D pour des robots plus sûrs
Les voitures autonomes et les robots de service doivent comprendre la forme du monde qui les entoure en trois dimensions pour éviter les collisions et naviguer en sécurité. Cette étude introduit une manière plus rapide et plus précise de convertir des paires d’images prises par des caméras ordinaires en une carte 3D détaillée en grille des objets proches, ce qui pourrait rendre les futurs robots plus fiables sans recourir à des capteurs laser coûteux.
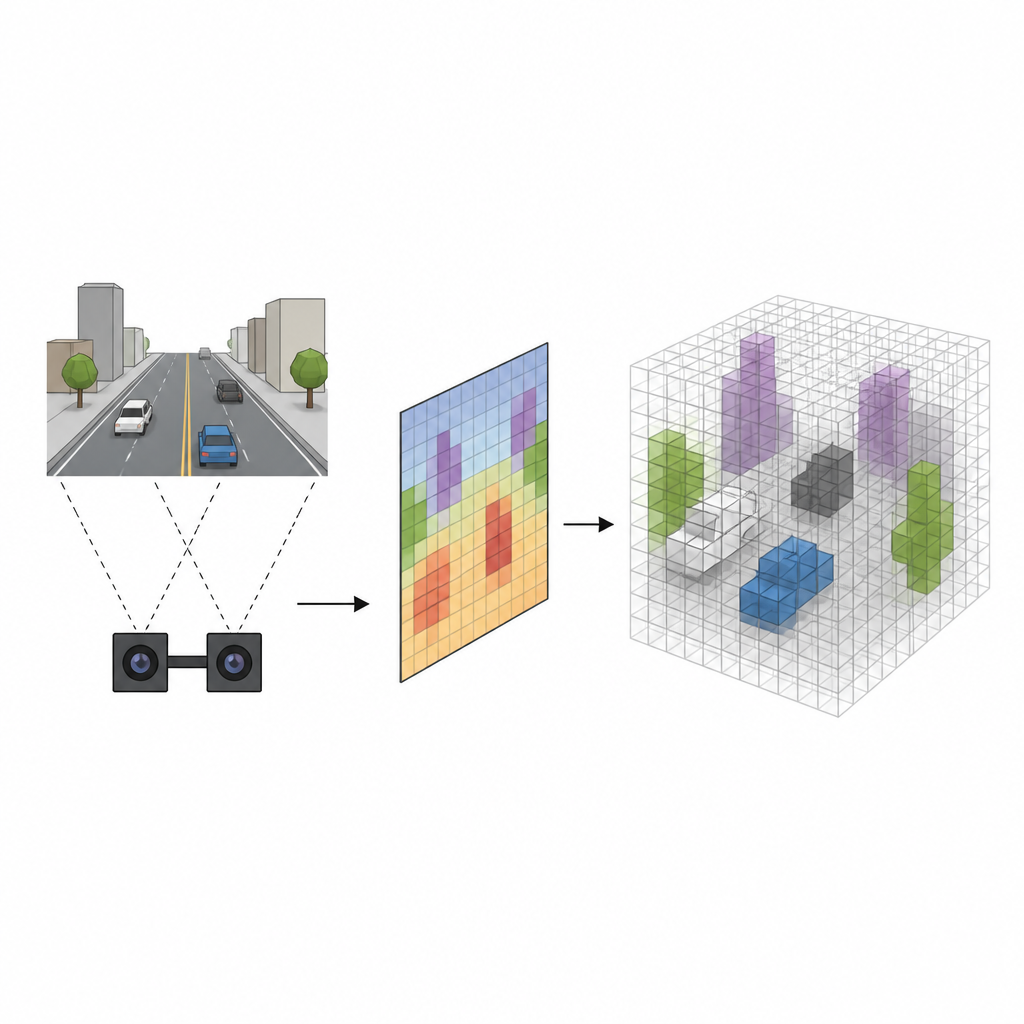
Des images plates à l’espace solide
Beaucoup de robots utilisent des caméras stéréo, qui regardent une scène depuis deux points de vue légèrement différents, un peu comme nos yeux. Les systèmes traditionnels estiment d’abord la distance de chaque pixel à la caméra puis projettent chaque pixel dans l’espace 3D, remplissant une grille de petits cubes appelés voxels qui indiquent où des objets pourraient se trouver. Si cette méthode fonctionne, elle est lente et tend à estomper les bords des objets, créant des déclenchements erronés où des espaces vides sont marqués à tort comme occupés. La nouvelle approche, nommée SVRS, évite cette projection lourde pixel par pixel et apprend plutôt une connexion plus directe entre ce que voient les caméras et quels cubes de l’espace sont effectivement remplis.
Apprendre au réseau à raisonner en cubes
Les chercheurs représentent la zone devant un véhicule comme une pile de cubes uniformes qui forment ensemble une grille 3D. Plutôt que de partir des pixels et de les pousser dans l’espace, leur module Pixel Voxel Projecting part de chaque cube et se demande où il apparaîtrait dans les images caméra. En utilisant la géométrie connue des caméras stéréo, le module projette chaque cube dans les deux images et échantillonne les riches caractéristiques internes que calculent les réseaux stéréo modernes. Cela transforme l’information dense de l’image en un signal 3D parcimonieux directement lié à chaque cube, éliminant le travail inutile dans les régions vides et réduisant le flou des bords qui cause des faux positifs.
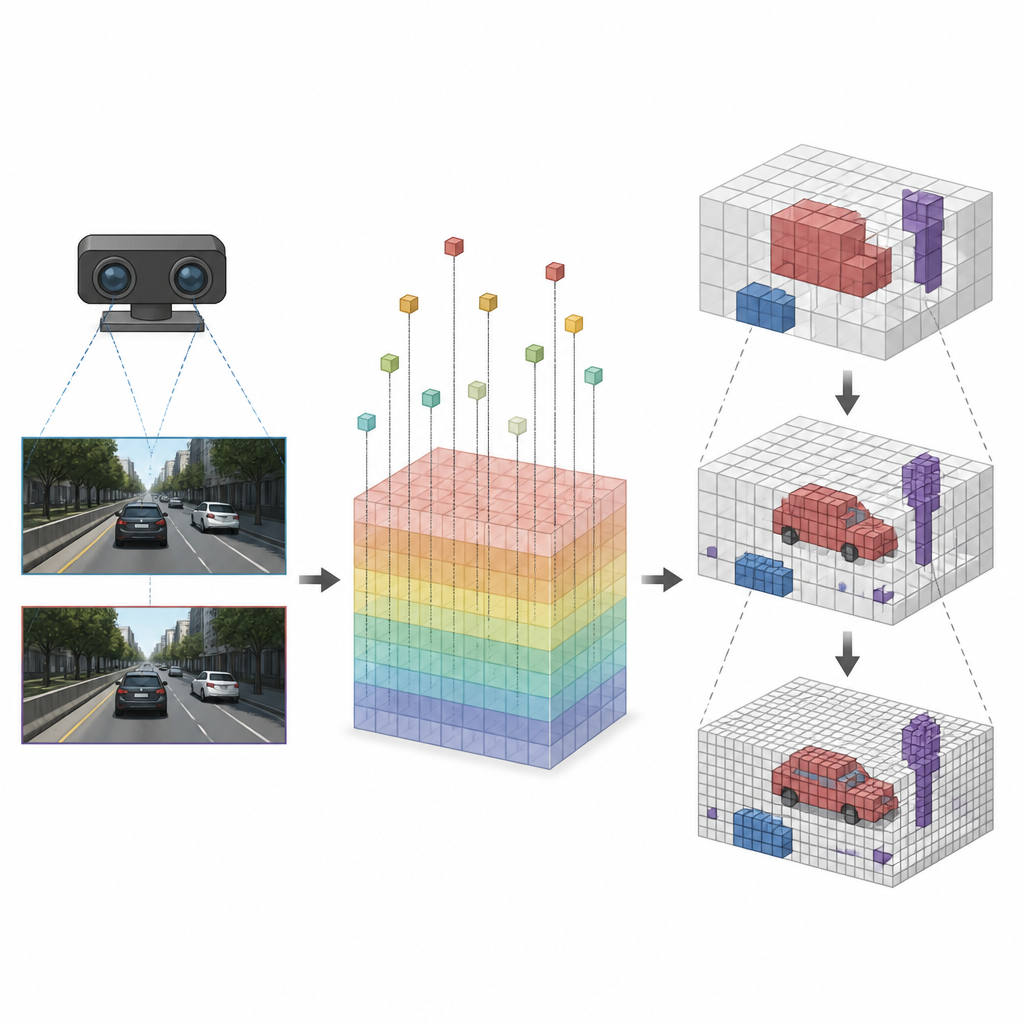
Concentrer le détail là où cela compte
Une fois que chaque cube est relié aux bonnes caractéristiques d’image, SVRS applique une architecture Encodeur-Décodeur basée sur un octree pour décider quels cubes sont occupés. L’idée est de commencer par une vue grossière de la scène puis de l’affiner étape par étape. À chaque niveau, le réseau prédit quels grands cubes contiennent quelque chose et utilise cette information pour guider le niveau suivant, plus fin, où seules les régions prometteuses sont examinées en détail. Les zones vides sont supprimées tôt pour ne pas submerger le réseau lors du zoom. Cette stratégie du grossier au fin concentre les calculs sur les voitures, les bords de route et autres objets importants au lieu de gaspiller des efforts sur l’air libre.
Apprendre à partir de capteurs existants sans étiquettes manuelles
Pour entraîner le système, les auteurs évitent la tâche coûteuse d’annoter manuellement des scènes 3D. Ils utilisent plutôt des cartes de profondeur et des nuages de points produits par des méthodes stéréo et laser performantes comme signaux d’apprentissage. Ils nettoient la profondeur stéréo avec un simple détecteur de contours avant de la transformer en grille 3D, et ils expérimentent aussi l’entraînement directement contre des mesures laser. Cette configuration auto-supervisée permet au réseau d’imiter des données 3D de haute qualité tout en restant beaucoup plus léger et plus rapide à l’exécution, ce qui le rend pratique pour des ordinateurs embarqués dans des véhicules.
Des vues 3D plus rapides et plus nettes pour les machines en mouvement
Des tests sur un large jeu de données de conduite montrent que SVRS reconstruit des grilles 3D avec une précision comparable aux meilleures méthodes basées sur la stéréo tout en s’exécutant jusqu’à quatorze fois plus rapidement que certains forts baselines et environ trois fois plus vite que d’autres systèmes temps réel. Il génère moins d’erreurs signalant à tort qu’un espace vide est occupé, bien qu’il puisse manquer quelques petits objets, traduisant un compromis entre prudence et exhaustivité. Pour un lecteur non spécialiste, le message clé est que la méthode aide les machines à transformer les images caméra en une image 3D de la route plus claire et plus efficace, ce qui constitue une étape importante vers des véhicules et robots autonomes plus sûrs et plus performants.
Citation: Zou, Z., Wu, Y., Zhang, H. et al. SVRS: self-supervised 3D voxel reconstruction network from stereo vision. Sci Rep 16, 15548 (2026). https://doi.org/10.1038/s41598-026-45924-0
Mots-clés: vision stéréo, reconstruction 3D, grille de voxels, conduite autonome, perception robotique