Clear Sky Science · ru
SVRS: самообучающаяся сеть для 3D-воксельной реконструкции из стереозрения
Видеть мир в 3D для более безопасных роботов
Автомобили с автопилотом и сервисные роботы должны понимать форму окружающего их мира в трёх измерениях, чтобы избегать столкновений и безопасно ориентироваться. В этом исследовании предложен более быстрый и точный способ преобразования пар обычных изображений камеры в детализированную 3D-сетку ближайших объектов, что может сделать будущих роботов надёжнее без необходимости в дорогих лазерных датчиках.
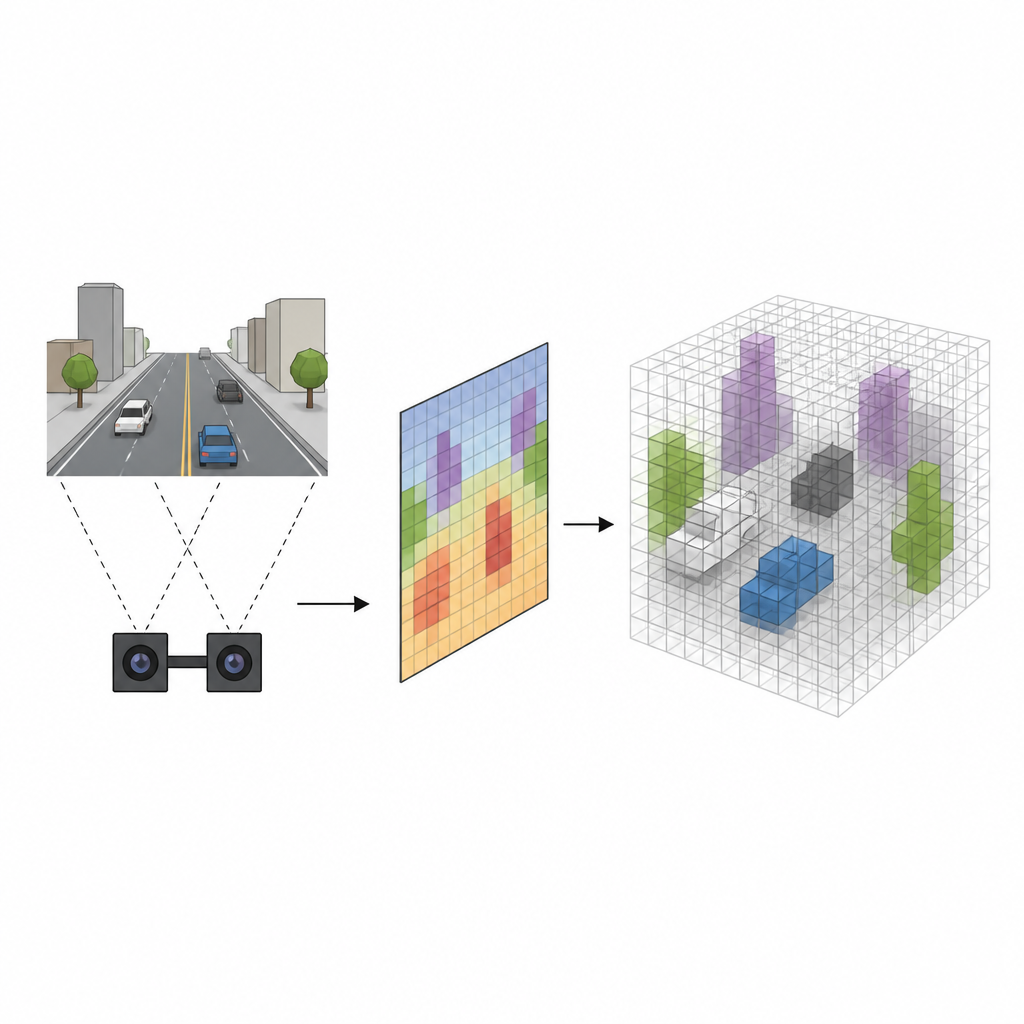
От плоских снимков к объёмному пространству
Многие роботы используют стереокамеры, которые смотрят на сцену с двух слегка разных точек зрения, как наши глаза. Традиционные системы сначала оценивают расстояние до каждого пикселя, а затем проецируют каждый пиксель в 3D-пространство, заполняя сетку маленьких кубов — вокселей — чтобы пометить, где могут находиться объекты. Хотя этот метод работает, он медленный и склонен размывать границы объектов, создавая ложные тревоги, где пустое пространство ошибочно помечено как занятое. Новый подход, называемый SVRS, пропускает эту тяжёлую по-пиксельную проекцию и вместо этого обучается более прямой связи между тем, что видят камеры, и тем, какие кубы в пространстве действительно заполнены.
Обучение сети мыслить кубами
Исследователи представляют область перед транспортным средством в виде слоя одинаковых кубов, которые вместе образуют 3D-сетку. Вместо того чтобы начинать с пикселей и выталкивать их в пространство, их модуль Pixel Voxel Projecting начинает с каждого куба и спрашивает, где он будет отображён на изображениях камер. Используя известную геометрию стереокамер, модуль проецирует каждый куб обратно в два изображения и выбирает богатые внутренние признаки, которые вычисляют современные стереосети. Это превращает плотную информацию изображения в разреженный 3D-сигнал, привязанный напрямую к каждому кубу, сокращая бесполезную работу в пустых областях и уменьшая размывание краёв, которое вызывает ложные срабатывания.
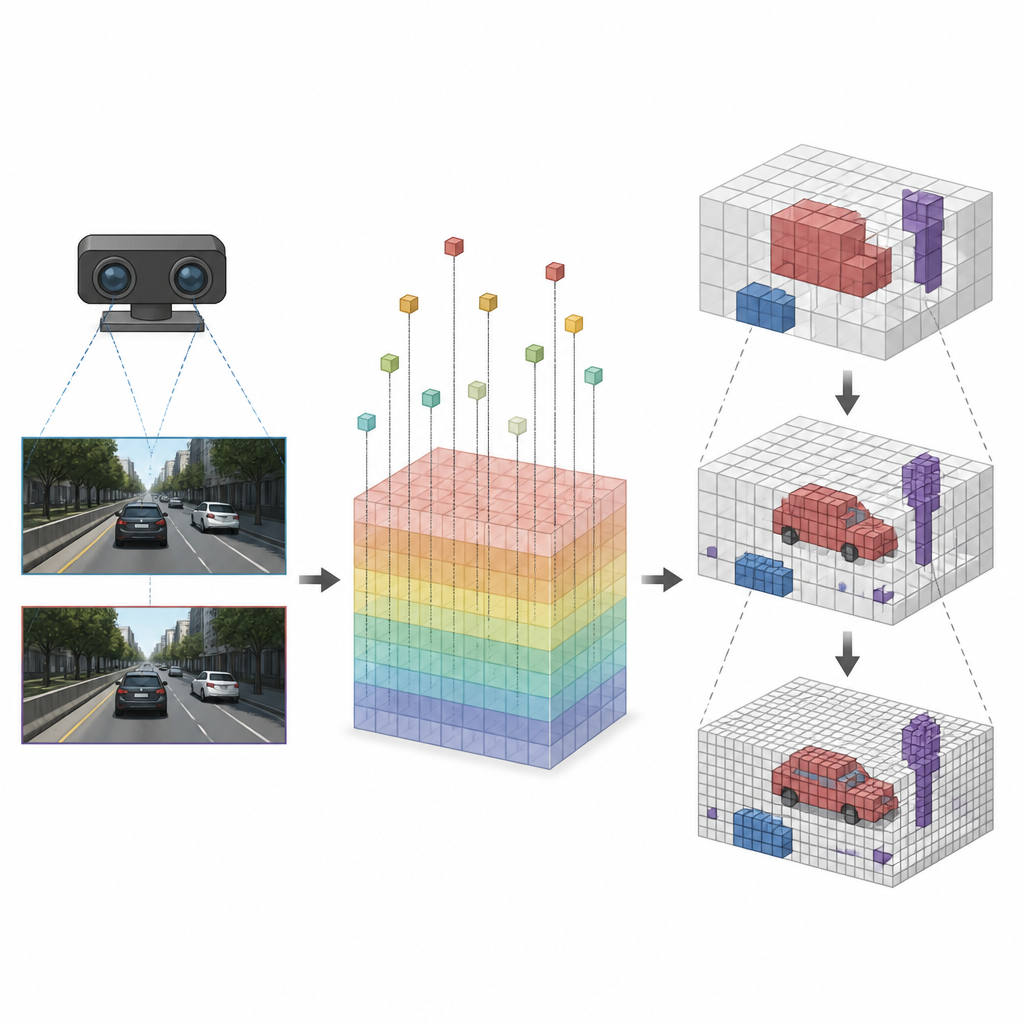
Фокусировка детализации там, где это важно
После того как каждый куб связали с соответствующими признаками изображения, SVRS применяет архитектуру кодировщика-декодировщика на основе октодерева, чтобы решить, какие кубы заняты. Идея состоит в том, чтобы начать с грубого представления сцены и затем уточнять его шаг за шагом. На каждом уровне сеть предсказывает, какие крупные кубы содержат что-то, и использует эту информацию для управления следующим, более мелким уровнем, где в деталях исследуются только перспективные области. Пустые зоны подавляются уже на ранних этапах, чтобы они не перегружали сеть по мере её приближения. Эта стратегия от грубого к тонкому удерживает вычисления сфокусированными на автомобилях, краях дороги и других важных объектах, вместо того чтобы тратить усилия на открытый воздух.
Обучение на данных существующих датчиков без ручной разметки
Для обучения системы авторы избегают дорогой задачи ручной разметки 3D-сцен. Вместо этого они используют карты глубины и облака точек, полученные надёжными существующими методами на основе стерео и лазерных сканеров, в качестве обучающих сигналов. Они очищают стерео-глубину с помощью простого детектора границ перед преобразованием в 3D-сетку, а также экспериментируют с обучением напрямую по лазерным измерениям. Такая самообучающаяся настройка позволяет сети имитировать высококачественные 3D-данные, оставаясь при этом гораздо легче и быстрее во время работы, что делает её практичной для встроенных компьютеров в транспортных средствах.
Более быстрые и чистые 3D-виды для движущихся машин
Тесты на крупном датасете вождения показывают, что SVRS восстанавливает 3D-сетки с точностью, сопоставимой с ведущими методами на основе стерео, при этом работает до четырнадцати раз быстрее, чем некоторые сильные базовые решения, и примерно в три раза быстрее других систем в реальном времени. Она делает меньше ложных заявлений о занятости пустого пространства, хотя может пропустить некоторые мелкие объекты, что отражает компромисс между осторожностью и полнотой. Для непрофессионального читателя ключевая мысль в том, что метод помогает машинам превращать изображения камер в более ясную и эффективную 3D-картину дороги впереди — важный шаг к более безопасным и способным автономным транспортным средствам и роботам.
Цитирование: Zou, Z., Wu, Y., Zhang, H. et al. SVRS: self-supervised 3D voxel reconstruction network from stereo vision. Sci Rep 16, 15548 (2026). https://doi.org/10.1038/s41598-026-45924-0
Ключевые слова: стереозрение, 3D-реконструкция, воксельная сетка, автономное вождение, восприятие робота