Clear Sky Science · ar
SVRS: شبكة إعادة بناء فوكسل ثلاثية الأبعاد بالتعلم الذاتي من الرؤية المُزدوجة
رؤية العالم ثلاثي الأبعاد من أجل روبوتات أكثر أمانًا
يجب أن تفهم السيارات ذاتية القيادة والروبوتات الخدمية شكل العالم المحيط بها في ثلاثة أبعاد لتجنب التصادمات والتنقل بأمان. تقدم هذه الدراسة طريقة أسرع وأكثر دقة لتحويل زوجي صور كاميرا عادية إلى خريطة شبكة ثلاثية الأبعاد مفصّلة للأجسام القريبة، مما قد يجعل الروبوتات المستقبلية أكثر موثوقية دون الحاجة إلى حسّاسات ليزر باهظة الثمن.
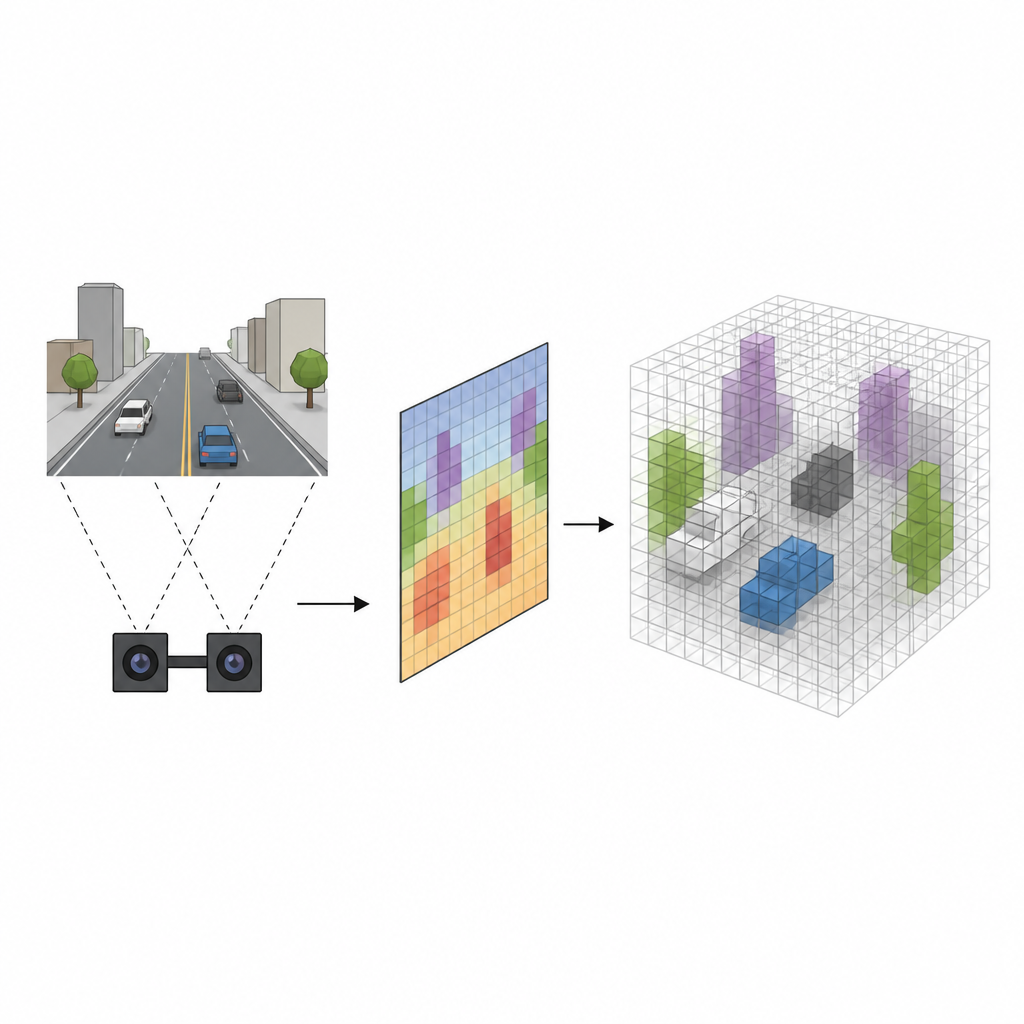
من صور مسطحة إلى مساحة صلبة
تستخدم العديد من الروبوتات كاميرات ستيريو، التي تُراقب المشهد من نقطتين منفصلتين قليلًا، تمامًا مثل أعيننا. تقليديًا، تقوم الأنظمة أولًا بتقدير مدى كل بكسل من الكاميرا ثم تُسقط كل بكسل إلى الفضاء الثلاثي الأبعاد، مُمتلئة شبكة من المكعبات الصغيرة تُدعى فوكسلات تُشير إلى أماكن وجود الأجسام المحتملة. رغم أن هذه الطريقة تعمل، إلا أنها بطيئة وتميل إلى طمس حواف الأجسام، ما يخلق تنبيهات كاذبة عندما تُوسَم فراغات فارغة على أنها مشغولة. تتجاوز المقاربة الجديدة، المسماة SVRS، هذه الإسقاطات المكثفة بكسلًا بكسل وتتعلم بدلًا من ذلك اتصالًا أكثر مباشرة بين ما تراه الكاميرات وأي مكعبات في الفضاء ممتلئة فعلًا.
تدريب الشبكة على التفكير بالمكعبات
يمثل الباحثون المنطقة أمام المركبة كركام من المكعبات المتساوية التي تشكل معًا شبكة ثلاثية الأبعاد. وبدلًا من البدء من البكسلات ودفعها إلى الخارج في الفضاء، يبدأ مُكوِّن إسقاط البكسل إلى الفوكسل من كل مكعب ويسأل أين سيظهر في صور الكاميرا. مستخدمًا الهندسة المعروفة لكاميرات الستيريو، يسقط المكوِّن كل مكعب مرة أخرى إلى الصورتين ويأخذ عينات من السمات الداخليّة الغنية التي تحسبها شبكات الستيريو الحديثة. يحول هذا معلومات الصورة الكثيفة إلى إشارة ثلاثية الأبعاد متناثرة مرتبطة مباشرة بكل مكعب، مما يقلّل العمل غير المفيد في المناطق الفارغة ويخفّف طمس الحواف الذي يسبب الإيجابيات الكاذبة.
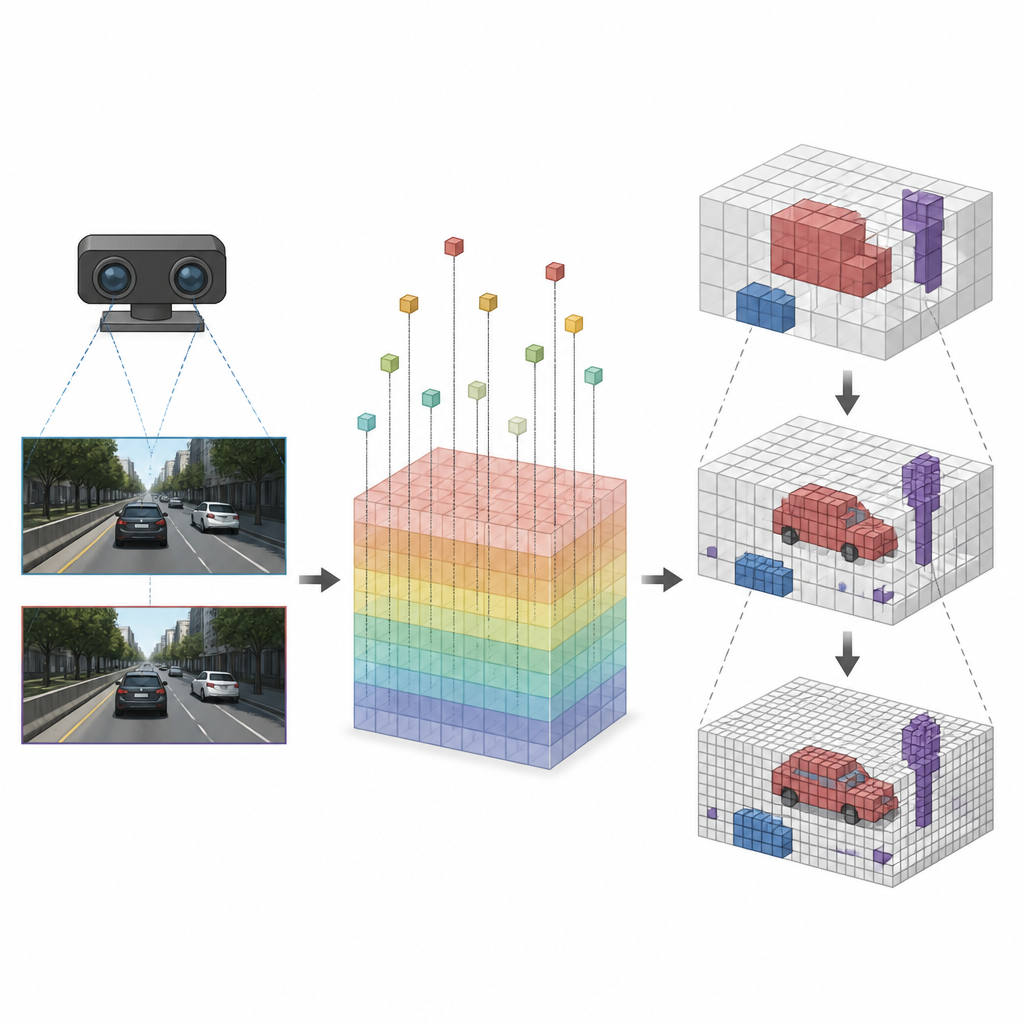
تركيز التفاصيل حيث تُهمّ
بعد ربط كل مكعب بسمات الصورة الصحيحة، تطبق SVRS بنية مشفّر-فكّ مشفّر مبنية على شجرة ثمانية (Octree) لتقرير أي المكعبات مشغولة. الفكرة هي البدء بنظرة خامة للمشهد ثم تحسينها خطوة بخطوة. عند كل مستوى، تتنبأ الشبكة أي المكعبات الكبيرة تحتوي شيئًا وتستخدم تلك المعلومة لتوجيه المستوى التالي الأشد دقّة، حيث تُفحص المناطق الواعدة بالتفصيل فقط. تُقمع المناطق الفارغة مبكرًا حتى لا تُطغى على الشبكة أثناء التكبير. تحافظ هذه الاستراتيجيّة من الخشن إلى الدقيق على الحسابات مركّزة على السيارات وحواف الطريق والأجسام المهمة بدلًا من إهدار الجهد على الفراغ.
التعلّم من الحساسات الموجودة دون تسميات يدوية
لتدريب النظام، يتجنّب المؤلفون مهمة وسم المشاهد الثلاثية الأبعاد يدويًا والمكلّفة. بدلًا من ذلك، يستخدمون خرائط العُمق والسحب النقطية الناتجة عن طرق ستيريو قوية وأساليب قائمة على الليزر كإشارات تعلّم. يقومون بتنقية عمق الستيريو باستخدام كاشف حواف بسيط قبل تحويله إلى شبكة ثلاثية الأبعاد، ويجرّبون أيضًا التدريب مباشرة مقابل قياسات الليزر. يتيح هذا الإعداد بالتعلّم الذاتي للشبكة تقليد بيانات ثلاثية الأبعاد عالية الجودة بينما تظل أخف بكثير وأسرع عند التشغيل، مما يجعلها عملية لأجهزة الحوسبة المدمجة في المركبات.
رؤى ثلاثية الأبعاد أسرع وأنظف للآلات المتحركة
تُظهر الاختبارات على مجموعة بيانات قيادة كبيرة أن SVRS تعيد بناء شبكات ثلاثية الأبعاد بدقّة مُعادِلة لطرق الستيريو الرائدة بينما تعمل أسرع بما يصل إلى أربعة عشر مرة من بعض الأساسيات القوية وحوالي ثلاث مرات أسرع من أنظمة الوقت الحقيقي الأخرى. تُصدر عددًا أقل من الادعاءات الخاطئة بأن الفراغ مشغول، رغم أنها قد تفوّت بعض الأجسام الصغيرة، مما يعكس توازنًا بين الحذر والشمولية. للقراء العامين، الرسالة الأساسية هي أن هذه الطريقة تساعد الآلات على تحويل صور الكاميرا إلى صورة ثلاثية الأبعاد أوضح وأكثر كفاءة للطريق الأمامي، وهو خطوة مهمة نحو مركبات وروبوتات مستقلة أكثر أمانًا وقدرة.
الاستشهاد: Zou, Z., Wu, Y., Zhang, H. et al. SVRS: self-supervised 3D voxel reconstruction network from stereo vision. Sci Rep 16, 15548 (2026). https://doi.org/10.1038/s41598-026-45924-0
الكلمات المفتاحية: الرؤية المُزدوجة, إعادة بناء ثلاثية الأبعاد, شبكة فوكسل, القيادة الذاتية, إدراك الروبوت