Clear Sky Science · zh
MAGNet:通过多模态融合与自适应图卷积增强动作识别
教计算机“读懂”人体动作
从追踪你身体动作的视频游戏到在有人周围安全移动的家用机器人,许多技术都依赖于能够理解人体动作的计算机。然而现实环境很复杂:光线变化、人物遮挡家具以及传感器故障等都会影响表现。本研究提出了 MAGNet,一种新系统,能在日常环境中更准确、更可靠地帮助计算机识别人们的动作。
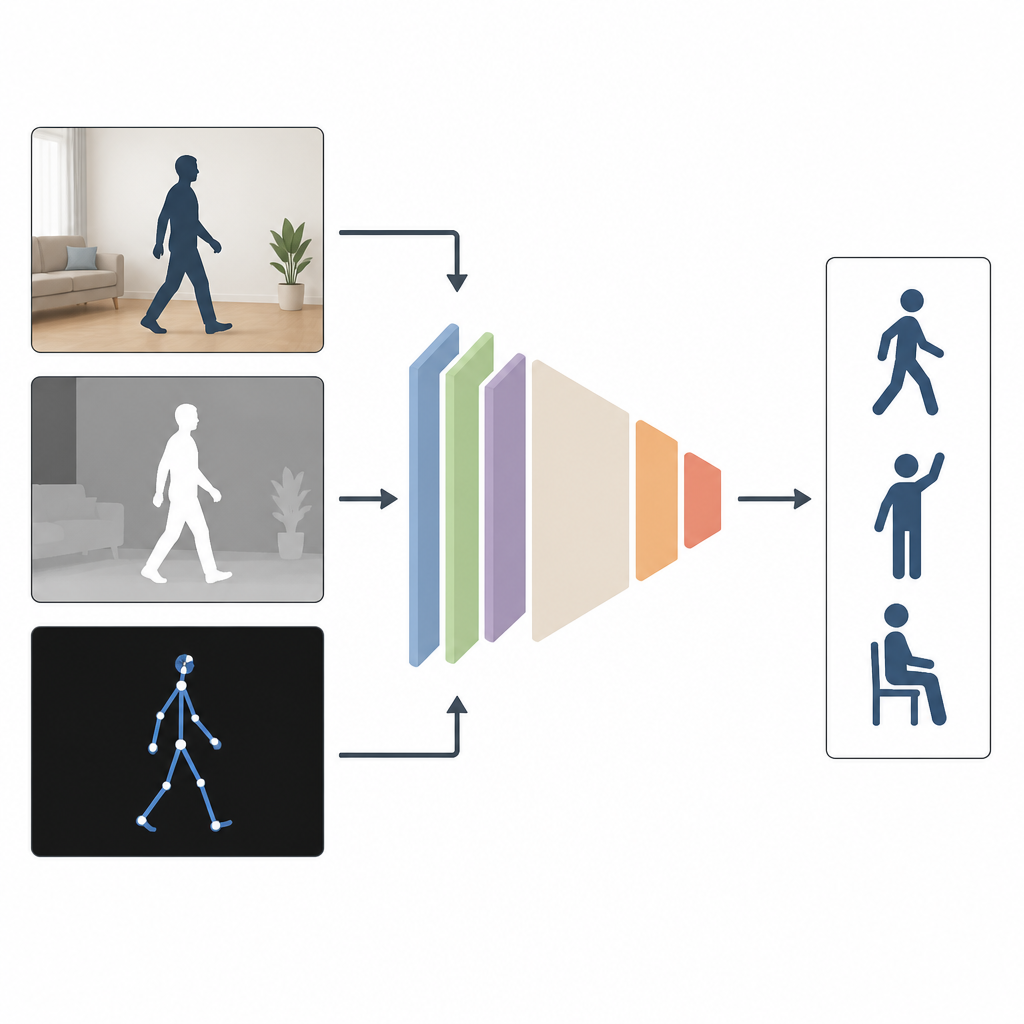
为何多角度观察更有助于识别
目前大多数系统只使用一种输入类型来观察人,例如普通彩色视频。在实验室里这种方法表现良好,但在室内光线昏暗、摄像头角度偏侧或身体部分被遮挡时就会失效。作者认为,结合多种信息源效果更佳。MAGNet 融合了对同一动作的三种视角:反映外观的普通彩色图像、测量物体到相机距离的深度图像,以及表示人体三维关节点的骨架描述。三者合在一起,能更全面地描绘一个人在移动时的细节。
让网络根据身体自适应
MAGNet 的核心结构将人体视为由肩膀、肘部和膝盖等连接点组成的网络。这张“图”告诉系统哪些关节点会相互影响。MAGNet 不将该结构固定不变,而是根据不同传感器所见动态调整连接强度。如果深度摄像头清楚地显示出弯曲的膝盖而彩色视频很嘈杂,系统会在该部位更信任深度信号。该自适应图设计有助于 MAGNet 跟踪姿态随时间的变化,并在每个关节处判断应优先采纳哪个传感器的信息。
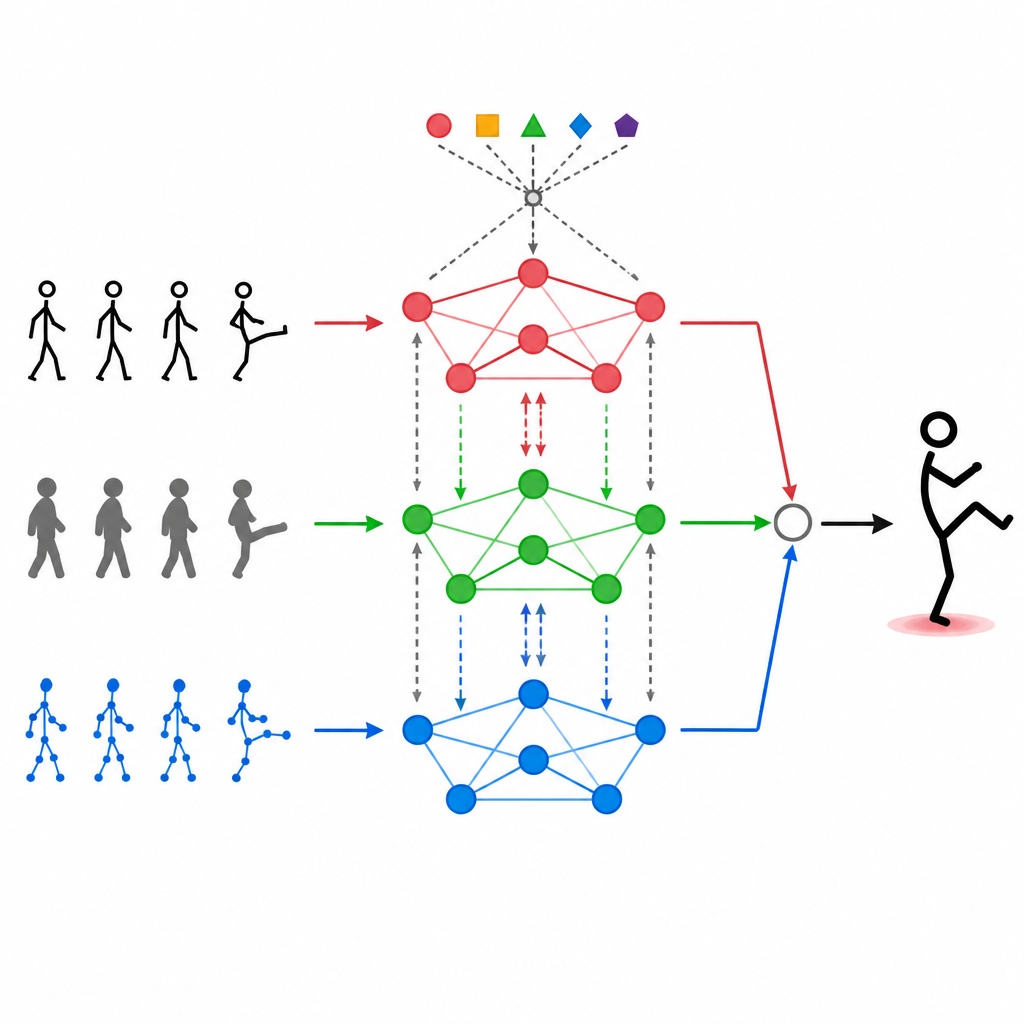
让各模态相互“交流”
简单地将不同数据流堆叠在一起并不足够。MAGNet 使用自注意力机制,使每种输入能够“观察”其它输入并决定它们应有多大影响力。实际上,这意味着系统可以学习诸如“当手部关节点以这种方式移动且深度图呈现出该形状时,极有可能是挥手”这样的模式,并增强这些组合信号。该注意力过程重复进行,逐步精炼三种模态的融合方式,使最终特征更贴合真实的人体动作,同时更不易受噪声或丢帧影响。
在数据缺失时填补空白
现实世界中的传感器会失效、被遮挡或不同步。为应对这些情况,作者加入了一个基于 VQ-VAE 方法的生成模块,该模块学习身体运动的典型方式。当某种类型的数据缺失或严重损坏时,该组件可以合成一个合理的缺失信息版本,例如估计的骨架或局部姿态特征,这与剩余传感器看到的内容一致。重要的是,模型在训练时被约束使得这些生成的姿态在解剖学上保持合理并贴近可能的动作类别,从而降低生成错误信息误导系统的风险。
实验结果说明了什么
团队在两组著名的人体动作视频集上测试了 MAGNet,这些数据包含行走、挥手、坐下等多种动作,并在不同视角与光照条件下录制。与多种强基线方法相比,MAGNet 达到了更高的准确率——包括那些仅依赖骨架或使用更刚性融合方式的方法。它在处理传感器数据部分或完全缺失的困难情况下表现更佳,同时运行速度足够快,可用于近实时场景。严格的消融实验也证实了从自适应人体图到注意力机制再到生成模块的每个设计部分,均对性能提升起到了作用。
更清晰、更可靠的动作理解
对非专家而言,关键结论是:MAGNet 让计算机以更接近细心观察者的方式理解人体动作——将视觉、深度和身体模型共同运用,而不是仅依赖单一、易出错的线索。通过灵活地组合多传感器视角并智能填补缺口,该系统即便在条件不理想时也能保持较高的识别精度。这使得 MAGNet 成为智能家居、体育分析与辅助机器人等日常应用中动作识别的有前景蓝图。
引用: Dong, H., Zhang, F., Liu, C. et al. MAGNet: enhancing action recognition with multimodal fusion and adaptive graph convolution. Sci Rep 16, 15100 (2026). https://doi.org/10.1038/s41598-026-45601-2
关键词: 人体动作识别, 多模态融合, 图神经网络, 计算机视觉, 姿态估计