Clear Sky Science · nl
MAGNet: verbeteren van actieherkenning met multimodale fusie en adaptieve grafconvolutie
Computers leren menselijke bewegingen "lezen"
Van videogames die je lichaam volgen tot huishoudrobots die zich veilig om mensen heen bewegen: veel technologieën zijn afhankelijk van computers die menselijke handelingen begrijpen. De echte wereld is echter rommelig: de verlichting verandert, mensen lopen achter meubels langs en sensoren falen soms. Deze studie presenteert MAGNet, een nieuw systeem dat computers helpt om te herkennen wat mensen doen, nauwkeuriger en betrouwbaarder onder alledaagse omstandigheden.
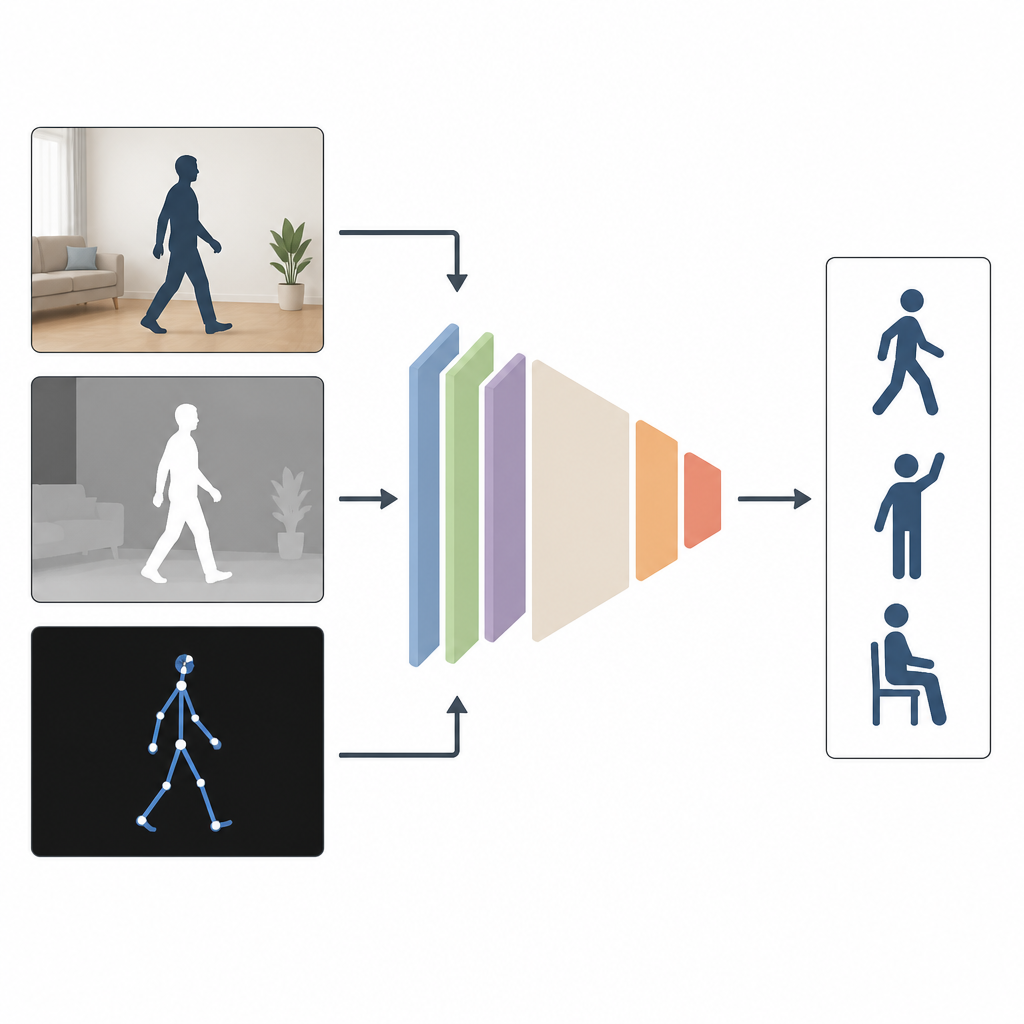
Waarom meerdere invalshoeken helpen
De meeste huidige systemen bekijken mensen met slechts één soort invoer, bijvoorbeeld een gewone kleurvideo. Dat werkt goed in een laboratorium, maar niet wanneer kamers schemerig zijn, camera’s schuin staan of een deel van het lichaam verborgen is. De auteurs betogen dat het combineren van verschillende soorten informatie beter werkt. MAGNet mengt drie gezichtspunten van dezelfde handeling: een gewone kleurenafbeelding die uiterlijk toont, een dieptebeeld dat meet hoe ver objecten van de camera afstaan, en een stokkenfiguurbeschrijving van de lichaamsskeletten in 3D. Samen geven deze weergaven een rijker, vollediger beeld van hoe iemand beweegt.
Het netwerk laten aanpassen aan het lichaam
In het hart van MAGNet ligt een structuur die het menselijk lichaam behandelt als een netwerk van verbonden punten, zoals schouders, ellebogen en knieën. Deze "graf" vertelt het systeem welke gewrichten elkaar beïnvloeden. MAGNet houdt deze structuur niet vast; in plaats daarvan past het de sterkte van de verbindingen aan op basis van wat de verschillende sensoren waarnemen. Als een dieptecamera duidelijk een gebogen knie laat zien terwijl het kleurbeeld ruisig is, vertrouwt het systeem stilletjes meer op het dieptesignaal voor dat deel van het lichaam. Dit adaptieve grafontwerp helpt MAGNet veranderingen in pose over de tijd te volgen en te bepalen welke sensor bij elk gewricht het meest leidend moet zijn.
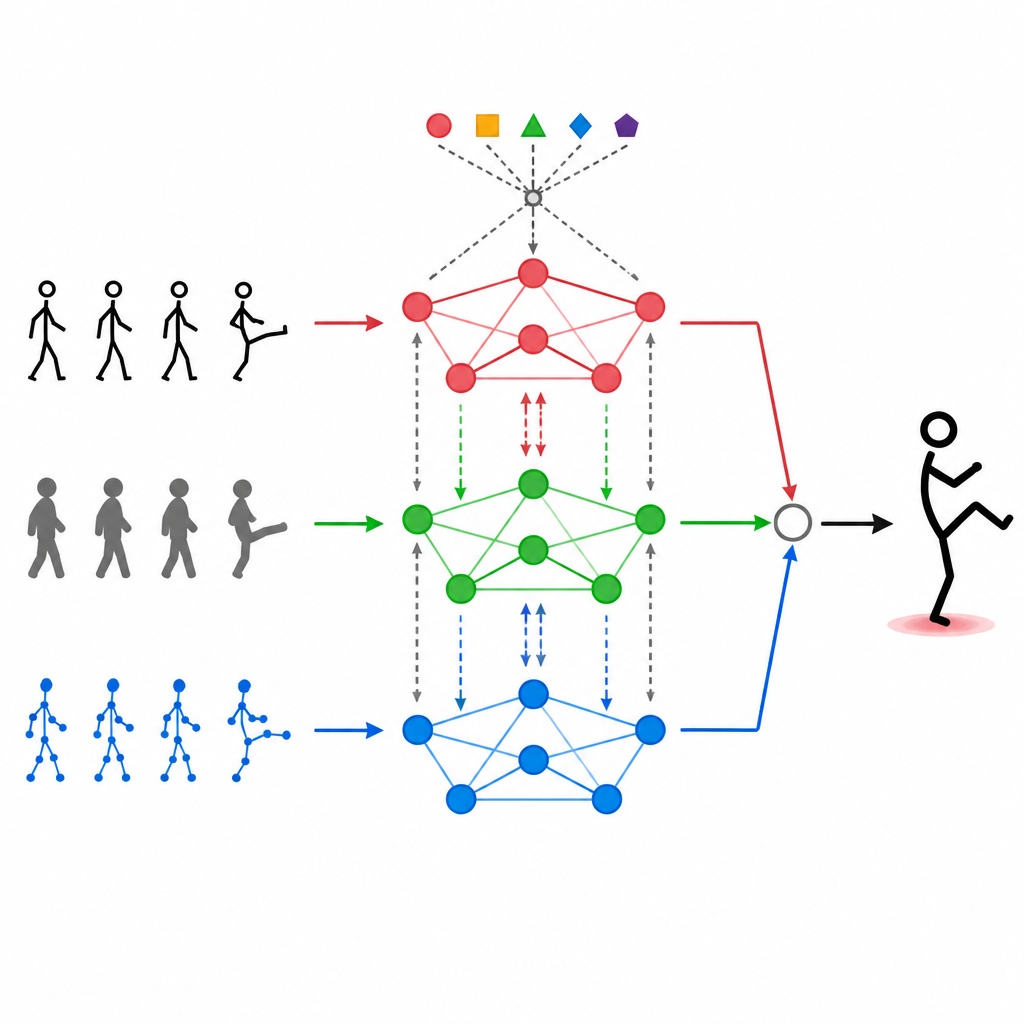
Modaliteiten elkaar laten beïnvloeden
Het simpel stapelen van verschillende datastromen bovenop elkaar is niet voldoende. MAGNet gebruikt een zelf-aandachtsmechanisme waarmee elk type invoer naar de anderen kan "kijken" en bepalen hoeveel deze moeten meewegen. In de praktijk betekent dit dat het systeem patronen kan leren zoals: "wanneer de handgewrichten op deze manier bewegen en het dieptebeeld deze vorm toont, is het waarschijnlijk een wuifbeweging" en die gecombineerde signalen vervolgens versterken. Dit aandachtproces gebeurt herhaaldelijk, waardoor de drie modaliteiten steeds beter worden samengevoegd zodat de uiteindelijke kenmerken dichter aansluiten bij echte menselijke acties en minder worden aangetast door ruis of ontbrekende frames.
De gaten opvullen wanneer gegevens ontbreken
Sensoren in de praktijk falen, worden geblokkeerd of raken niet gesynchroniseerd. Om hiermee om te gaan voegen de auteurs een generatief module toe gebaseerd op een methode genaamd VQ-VAE die typische lichaamsbewegingen leert. Wanneer een type data ontbreekt of sterk verstoord is, kan deze component een plausibele versie van de ontbrekende informatie synthetiseren, zoals een geschat skelet of lokale posekenmerken, die consistent is met wat de resterende sensoren laten zien. Belangrijk is dat het model zo wordt getraind dat deze gegenereerde poses anatomisch zinvol blijven en dicht bij de waarschijnlijke actiecategorie blijven, waardoor het risico op wilde gokjes die het systeem zouden kunnen misleiden, wordt verminderd.
Wat de experimenten laten zien
Het team testte MAGNet op twee bekende datasets van menselijke actievideo’s met lopen, wuiven, zitten en vele andere bewegingen, opgenomen onder uiteenlopende gezichtspunten en verlichting. MAGNet behaalde hogere nauwkeurigheid dan een reeks sterke eerdere methoden, inclusief diegenen die alleen op skeletten vertrouwen of die starre manieren gebruiken om invoer te combineren. Het systeem ging ook beter om met uitdagende gevallen, zoals wanneer de data van één sensor gedeeltelijk of geheel ontbrak, en draaide nog steeds snel genoeg om praktisch te zijn voor bijna realtime gebruik. Zorgvuldig uitgevoerde ablatietests bevestigden dat elk onderdeel van het ontwerp — van het adaptieve lichaamsgraf tot het aandachtmechanisme en de generatieve module — bijdroeg aan deze verbeteringen.
Heldere, betrouwbaardere actieinterpretatie
Voor niet-experts is de belangrijkste conclusie dat MAGNet computers helpt menselijke bewegingen te begrijpen als een oplettende waarnemer die zicht, diepte en een mentaal lichaamsmodel samen gebruikt, in plaats van te vertrouwen op één onbetrouwbaar teken. Door meerdere sensorbeelden flexibel te combineren en gaten intelligent op te vullen, houdt het systeem zijn herkenningsnauwkeurigheid hoog, zelfs wanneer de omstandigheden verre van perfect zijn. Dit maakt het een veelbelovend blauwdruk voor actieherkenning in alledaagse omgevingen zoals slimme huizen, sportanalyse en assistieve robots.
Bronvermelding: Dong, H., Zhang, F., Liu, C. et al. MAGNet: enhancing action recognition with multimodal fusion and adaptive graph convolution. Sci Rep 16, 15100 (2026). https://doi.org/10.1038/s41598-026-45601-2
Trefwoorden: herkenning van menselijke acties, multimodale fusie, graf-neuraal netwerk, computervisie, pose-schatting