Clear Sky Science · ar
MAGNet: تعزيز تعرف الأفعال عبر الدمج متعدد الوسائط والالتفاف البياني التكيفي
تعليم الحواسيب قراءة حركات الإنسان
من ألعاب الفيديو التي تتتبّع جسدك إلى الروبوتات المنزلية التي تتحرك بأمان حول الناس، تعتمد العديد من التقنيات على حواسيب قادرة على فهم الأفعال البشرية. لكن الواقع فوضوي: الإضاءة تتغير، يختبئ الأشخاص خلف الأثاث، وتتعطل بعض المستشعرات. تقدم هذه الدراسة MAGNet، نظامًا جديدًا يساعد الحواسيب على تمييز ما يفعله الأشخاص بدقة وموثوقية أكبر في ظروف الحياة اليومية.
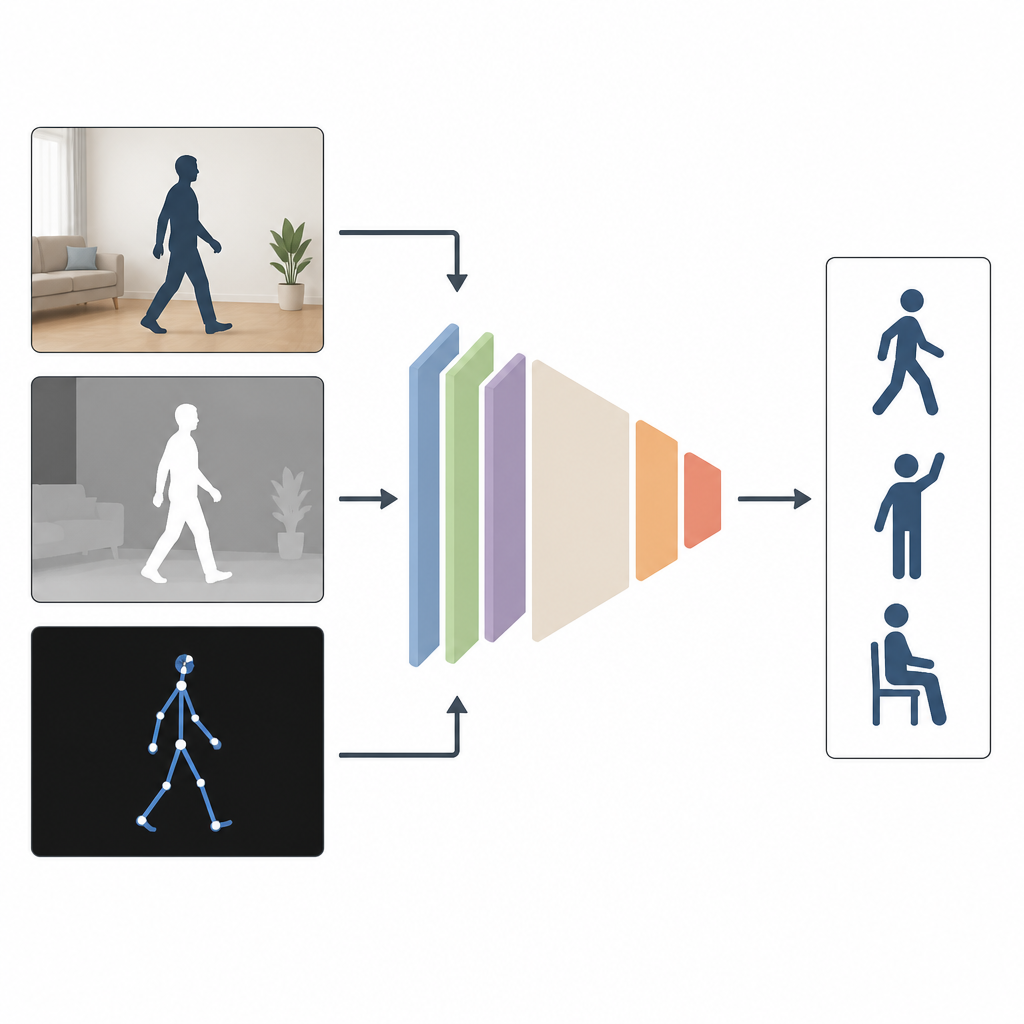
لماذا يساعد الرصد من زوايا متعددة
تعتمد معظم الأنظمة الحالية على نوع واحد من المدخلات، مثل فيديو ملون عادي. قد ينجح ذلك في المختبر، لكنه لا يعمل جيدًا عندما تكون الغرف مظلمة أو الكاميرات بزاوية جانبية أو جزء من الجسم مخفي. يجادل المؤلفون بأن الجمع بين عدة أنواع من المعلومات أفضل. يمزج MAGNet بين ثلاث صور لنفس الحركة: صورة ملونة عادية تعرض المظهر، وصورة عمقية تقيس بعد الأشياء عن الكاميرا، وتمثيل هيكلي لمفاصل الجسم الثلاثية الأبعاد. معًا، تمنح هذه النوافذ صورة أغنى وأكثر اكتمالًا لحركة الشخص.
السماح للشبكة بالتكيف مع الجسم
في قلب MAGNet بنية تتعامل مع الجسم البشري كشبكة من النقاط المترابطة، مثل الكتفين والمرفقين والركبتين. يحدد هذا «الرسم البياني» الأعضاء التي تؤثر في بعضها البعض. لا يحافظ MAGNet على هذه البنية ثابتة؛ بل يضبط قوة الاتصالات بناءً على ما تراه المستشعرات المختلفة. إذا أوضحت كاميرا عمق انثناء ركبة بينما كانت الصورة الملونة مضطربة، فإن النظام يعطي ثقة أكبر لإشارة العمق في ذلك الجزء من الجسم. يساعد هذا التصميم التكيفي الرسم البياني MAGNet على متابعة تغير الوضعية عبر الزمن وتحديد أي مستشعر ينبغي أن يكون له الصوت الأعلى عند كل مفصل.
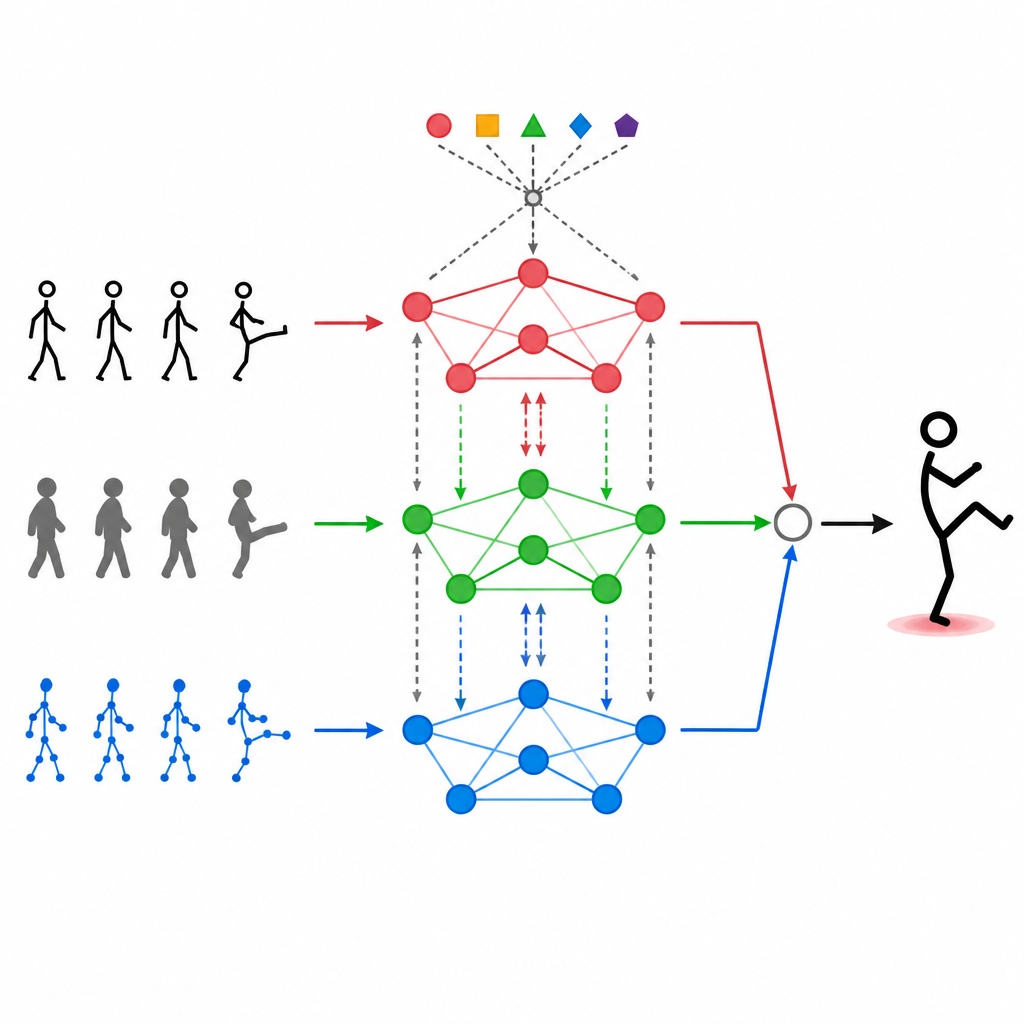
تمكين الوسائط من التواصل مع بعضها
تكديس تدفقات البيانات المختلفة فوق بعضها لا يكفي. يستخدم MAGNet آلية انتباه ذاتي تسمح لكل نوع من المدخلات «بالنظر» إلى الأنواع الأخرى وتقرير مدى تأثيرها. عمليًا، يعني هذا أن النظام يمكنه تعلم أنماط مثل «عندما تتحرك مفاصل اليد بهذه الطريقة وتظهر صورة العمق بهذا الشكل، فمن المحتمل أن تكون حركة تلوّح» ثم يعزز تلك الإشارات المجمعة. تتكرر عملية الانتباه هذه عدة مرات، مصقِلة كيفية دمج الوسائط الثلاث بحيث تتوافق الميزات النهائية بشكل أفضل مع الأفعال البشرية الحقيقية وتكون أقل تأثرًا بالضوضاء أو الإطارات المفقودة.
ملء الفجوات عند غياب البيانات
المستشعرات الواقعية تتعطل أو تُحجب أو تخرج عن المزامنة. لمواجهة ذلك، يضيف المؤلفون وحدة توليدية مبنية على طريقة تُسمى VQ-VAE تتعلم أنماط الحركة النموذجية للجسد. عندما يكون نوع واحد من البيانات مفقودًا أو تالفًا بشدة، يمكن لهذا المكون توليد نسخة معقولة من المعلومة المفقودة، مثل هيكل عظمي مُقدّر أو ميزات وضعية محلية، تتسق مع ما تراه المستشعرات المتبقية. والأهم من ذلك، يتم تدريب النموذج بحيث تظل هذه الوضعيات المولدة منطقية تشريحيًا وقريبة من فئة الفعل المحتملة، مما يقلل خطر التخمينات الشاذة التي قد تضلل النظام.
ما أظهرته التجارب
اختبر الفريق MAGNet على مجموعتين معروفتين من فيديوهات أفعال بشرية تتضمن المشي والتحية والجلوس والعديد من الحركات الأخرى، مسجلة من زوايا وإضاءات متنوعة. حقق MAGNet دقة أعلى من مجموعة من الأساليب السابقة القوية، بما في ذلك تلك المعتمدة فقط على الهياكل العظمية أو التي تستخدم طرقًا أكثر صلابة لدمج المدخلات. كما تعامل بشكل أفضل مع الحالات الصعبة، مثل جزئية أو انعدام بيانات أحد المستشعرات، واستمر في العمل بسرعة كافية ليكون عمليًا في الوقت شبه الحقيقي. أكدت اختبارات الإزالة المتأنية أن كل جزء من التصميم — من الرسم البياني التكيفي للجسم إلى آلية الانتباه والوحدة التوليدية — ساهم في هذه التحسينات.
فهم أوضح وأكثر موثوقية للحركة
لغير المتخصص، الخلاصة الأساسية هي أن MAGNet يساعد الحواسيب على فهم حركات البشر بطريقة أشبه بالمراقب المتأنّي الذي يستخدم الرؤية والعمق ونموذجًا ذهنيًا للجسم معًا، بدل الاعتماد على إشارة وحيدة غير موثوقة. من خلال الدمج المرن لوجهات نظر مستشعرية متعددة وملء الفجوات بذكاء، يحافظ النظام على دقة التعرف مرتفعة حتى عندما تكون الظروف بعيدة عن المثالية. هذا يجعله مخططًا واعدًا لتطبيقات تعرف الأفعال في بيئات يومية مثل المنازل الذكية، وتحليل الرياضة، والروبوتات المساعدة.
الاستشهاد: Dong, H., Zhang, F., Liu, C. et al. MAGNet: enhancing action recognition with multimodal fusion and adaptive graph convolution. Sci Rep 16, 15100 (2026). https://doi.org/10.1038/s41598-026-45601-2
الكلمات المفتاحية: تعرف الأفعال البشرية, الدمج متعدد الوسائط, الشبكة العصبية البيانية, رؤية الحاسوب, تقدير الوضعية