Clear Sky Science · pt
MAGNet: aprimorando o reconhecimento de ações com fusão multimodal e convolução gráfica adaptativa
Ensinando computadores a ler movimentos humanos
De jogos que rastreiam seu corpo a robôs domésticos que se deslocam com segurança ao redor de pessoas, muitas tecnologias dependem de computadores capazes de entender ações humanas. Mas a vida real é desordenada: a iluminação varia, pessoas passam atrás de móveis e alguns sensores falham. Este estudo apresenta o MAGNet, um novo sistema que ajuda computadores a reconhecer o que as pessoas estão fazendo com maior precisão e confiabilidade em condições cotidianas.
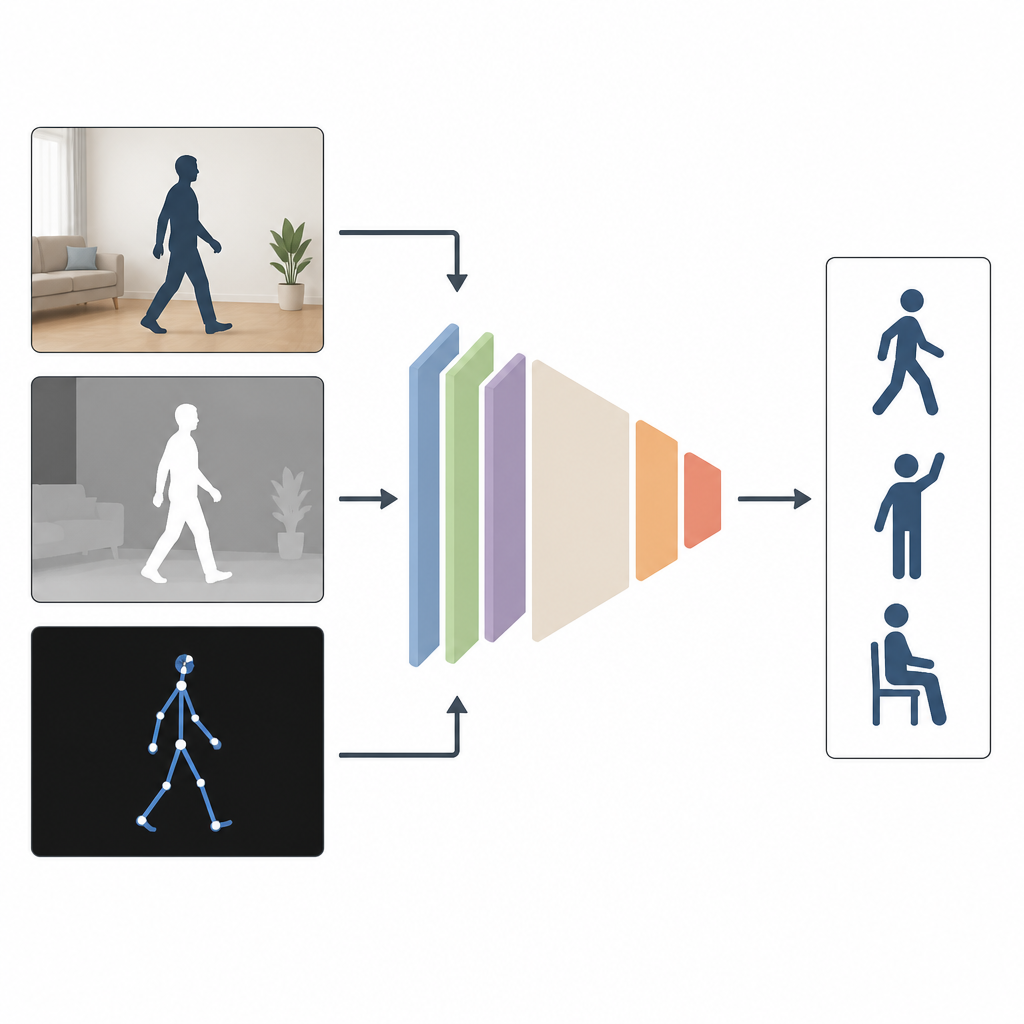
Por que observar de muitos ângulos ajuda
A maioria dos sistemas atuais observa pessoas usando apenas um tipo de entrada, como um vídeo colorido comum. Isso funciona bem em laboratório, mas não quando os ambientes estão escuros, as câmeras ficam de lado ou parte do corpo está ocultada. Os autores defendem que combinar vários tipos de informação é mais eficaz. O MAGNet mistura três visões da mesma ação: uma imagem colorida convencional que mostra a aparência, uma imagem de profundidade que mede quão distantes os objetos estão da câmera, e uma descrição em “stick figure” das articulações do corpo em 3D. Juntas, essas visões fornecem uma imagem mais rica e completa de como alguém está se movendo.
Deixar a rede se adaptar ao corpo
No coração do MAGNet está uma estrutura que trata o corpo humano como uma rede de pontos conectados, como ombros, cotovelos e joelhos. Esse “grafo” informa ao sistema quais articulações influenciam umas às outras. O MAGNet não mantém essa estrutura fixa. Em vez disso, ajusta a intensidade das conexões com base no que os diferentes sensores estão captando. Se uma câmera de profundidade mostra claramente um joelho dobrado enquanto a imagem colorida está ruidosa, o sistema confia discretamente mais no sinal de profundidade para aquela parte do corpo. Esse desenho de grafo adaptativo ajuda o MAGNet a acompanhar as mudanças de pose ao longo do tempo e a decidir qual sensor deve “falar” mais alto em cada articulação.
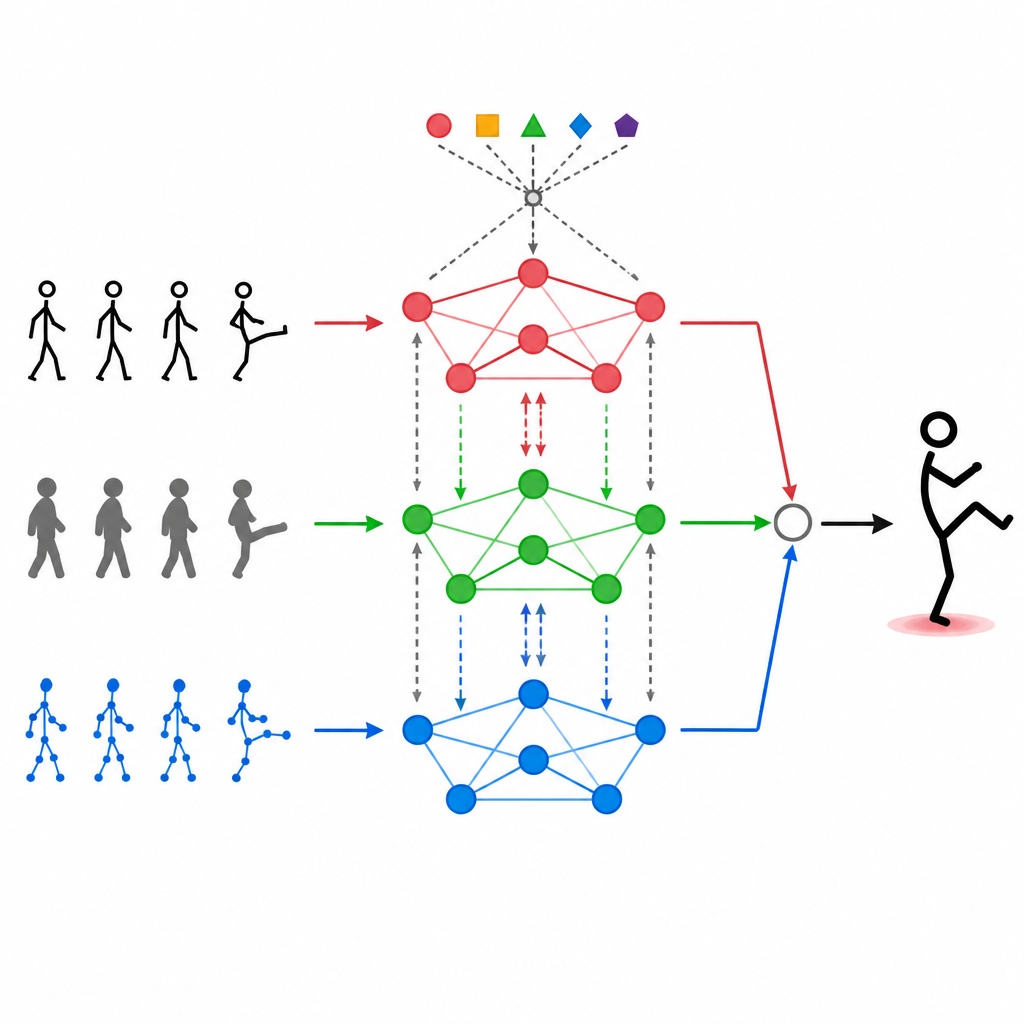
Fazer as modalidades conversarem entre si
Empilhar diferentes fluxos de dados não é suficiente. O MAGNet usa um mecanismo de autoatenção que permite que cada tipo de entrada “observe” as outras e decida quanto elas devem influenciá‑la. Na prática, isso significa que o sistema pode aprender padrões como “quando as articulações da mão se movem assim e a imagem de profundidade mostra essa forma, provavelmente é um aceno” e então reforçar esses sinais combinados. Esse processo de atenção acontece repetidamente, refinando como as três modalidades são mescladas para que as características finais fiquem melhor alinhadas às ações humanas reais e menos afetadas por ruído ou quadros ausentes.
Preenchendo lacunas quando faltam dados
Sensores do mundo real falham, são bloqueados ou ficam fora de sincronia. Para lidar com isso, os autores adicionam um módulo generativo baseado em um método chamado VQ‑VAE que aprende os modos típicos de movimento do corpo. Quando um tipo de dado está ausente ou muito corrompido, esse componente pode sintetizar uma versão plausível da informação faltante, como um esqueleto estimado ou características locais de pose, consistente com o que os sensores remanescentes mostram. Importante: o modelo é treinado para que essas poses geradas permaneçam anatomicamente coerentes e próximas à categoria de ação provável, reduzindo o risco de suposições erráticas que poderiam enganar o sistema.
O que os experimentos mostram
A equipe testou o MAGNet em dois conjuntos bem conhecidos de vídeos de ações humanas que incluem andar, acenar, sentar e muitos outros movimentos, gravados sob diferentes pontos de vista e condições de iluminação. O MAGNet atingiu maior precisão do que uma série de métodos fortes anteriores, incluindo aqueles que dependem apenas de esqueletos ou que usam formas mais rígidas de combinar entradas. Também lidou melhor com casos desafiadores, como quando os dados de um sensor estavam parcial ou completamente ausentes, e ainda rodou rápido o suficiente para ser prático em uso quase em tempo real. Testes de ablação cuidadosos confirmaram que cada parte do projeto, desde o grafo corporal adaptativo até o mecanismo de atenção e o módulo generativo, contribuiu para esses ganhos.
Compreensão de ações mais clara e confiável
Para um leitor não especialista, a principal conclusão é que o MAGNet ajuda computadores a entenderem movimentos humanos de forma mais semelhante a um observador atento que usa visão, profundidade e um modelo mental do corpo em conjunto, em vez de depender de um único indício pouco confiável. Ao combinar flexivelmente múltiplas visões de sensores e preencher inteligentemente as lacunas, o sistema mantém sua precisão de reconhecimento alta mesmo quando as condições estão longe do ideal. Isso o torna um roteiro promissor para reconhecimento de ações em cenários cotidianos, como casas inteligentes, análise esportiva e robôs assistivos.
Citação: Dong, H., Zhang, F., Liu, C. et al. MAGNet: enhancing action recognition with multimodal fusion and adaptive graph convolution. Sci Rep 16, 15100 (2026). https://doi.org/10.1038/s41598-026-45601-2
Palavras-chave: reconhecimento de ações humanas, fusão multimodal, rede neural gráfica, visão computacional, estimativa de pose