Clear Sky Science · ru
MAGNet: повышение точности распознавания действий с помощью мультимодального слияния и адаптивной графовой свёртки
Обучая машины «читать» движения людей
От видеоигр, отслеживающих движения тела, до домашних роботов, безопасно перемещающихся рядом с людьми, многие технологии зависят от того, что компьютеры понимают человеческие действия. Реальная жизнь сложна: освещение меняется, люди могут заходить за мебель, а некоторые датчики выходят из строя. В этом исследовании представлен MAGNet — новая система, которая помогает компьютерам точнее и надёжнее распознавать, что делают люди в повседневных условиях.
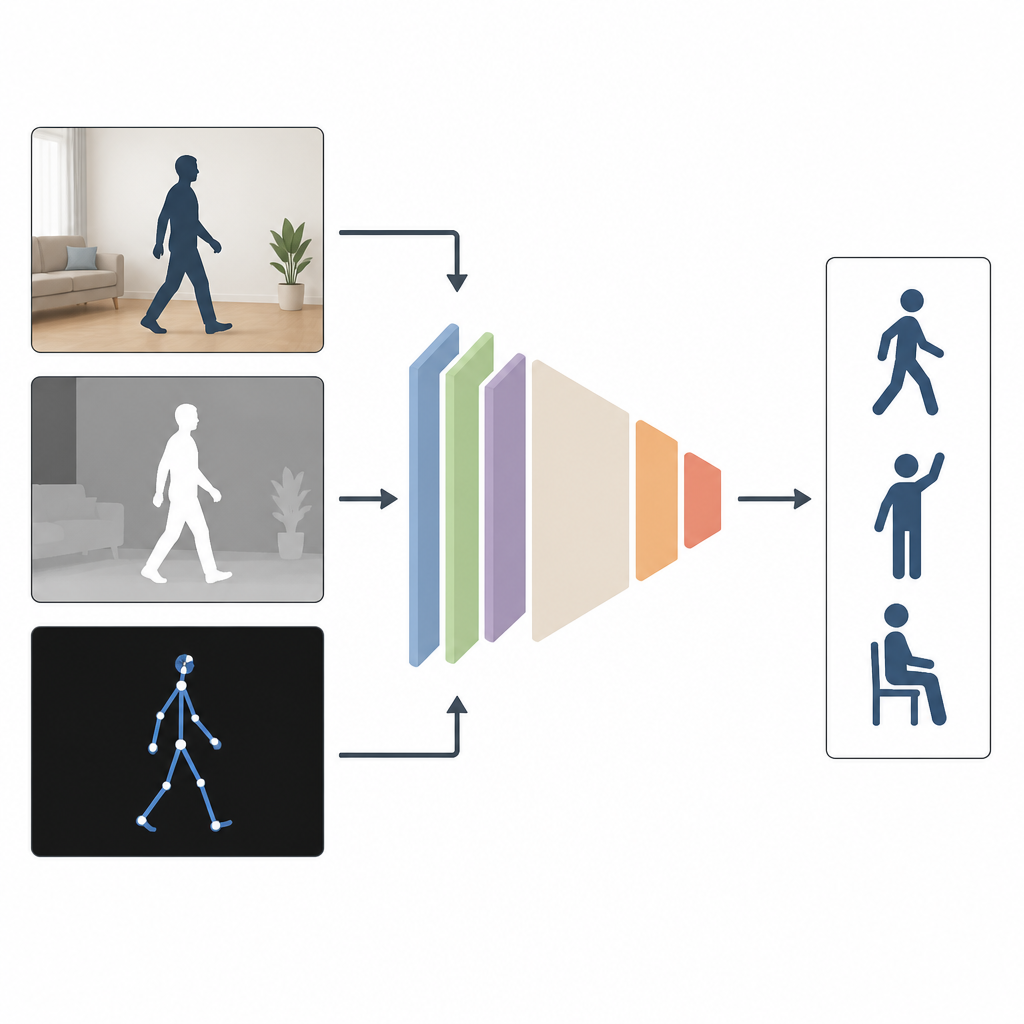
Почему важно смотреть с разных точек
Большинство современных систем используют только один тип входных данных, например обычное цветное видео. Это работает в лаборатории, но даёт сбои, когда в комнате темно, камера стоит сбоку или часть тела скрыта. Авторы утверждают, что сочетание нескольких типов информации даёт лучший результат. MAGNet объединяет три представления одного и того же действия: обычное цветное изображение, показывающее внешний вид; глубинное изображение, измеряющее расстояния до объектов; и моделировку тела в виде «палочной» схемы суставов в 3D. Вместе эти представления дают более полную и богатую картину движений человека.
Позволяя сети подстраиваться под тело
В основе MAGNet лежит структура, которая рассматривает человеческое тело как граф взаимосвязанных точек — например, плечи, локти и колени. Этот «граф» сообщает системе, какие суставы влияют друг на друга. MAGNet не фиксирует эту структуру жёстко — он настраивает силу связей в зависимости от того, что видят разные датчики. Если глубинная камера явно показывает согнутое колено, а цветное изображение шумит, система тихо доверит эту часть тела глубинному сигналу сильнее. Такая адаптивная схема помогает MAGNet отслеживать изменения позы во времени и решать, какому датчику на каждом суставе доверять больше.
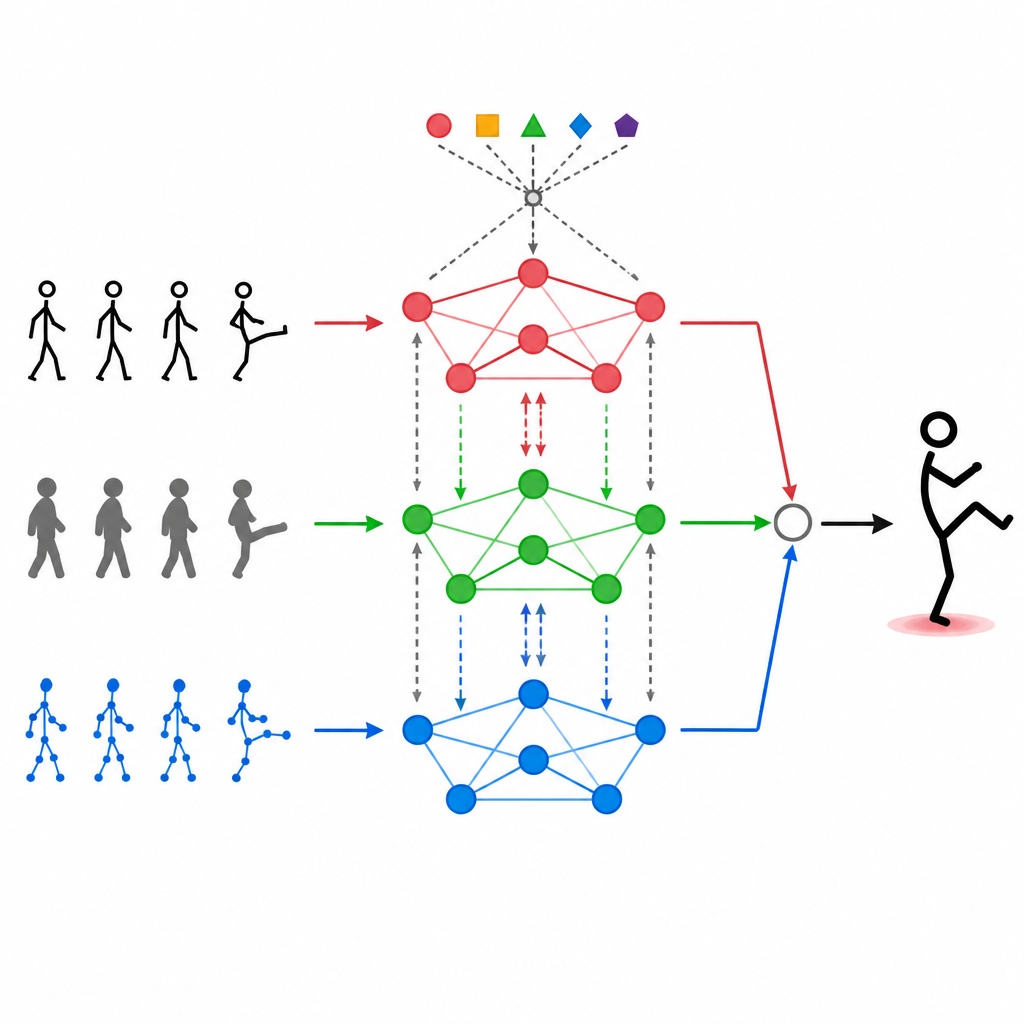
Давая модальностям возможность общаться
Простого сложения разных потоков данных недостаточно. MAGNet использует механизм самовнимания, который позволяет каждому типу входных данных «смотреть» на другие и решать, насколько они должны на него влиять. На практике это означает, что система может усвоить такие шаблоны: «когда суставы руки движутся так, а глубинное изображение имеет эту форму, скорее всего это приветствие», и усилить соответствующие совместные сигналы. Процесс внимания повторяется многократно, уточняя, как именно смешиваются три модальности, чтобы итоговые признаки лучше соответствовали реальным человеческим действиям и меньше страдали от шума или пропавших кадров.
Заполнение пробелов при отсутствии данных
Датчики в реальном мире могут выходить из строя, закрываться или терять синхронизацию. Чтобы справиться с этим, авторы добавили генеративный модуль на базе VQ-VAE, который учится типичным способам движения тела. Когда какой-то тип данных отсутствует или сильно искажен, этот компонент может синтезировать правдоподобную версию недостающей информации — например, оценённый скелет или локальные признаки позы — согласованную с тем, что видно по оставшимся датчикам. Важно, что модель обучают так, чтобы сгенерированные позы оставались анатомически правдоподобными и соответствовали вероятной категории действия, снижая риск неверных догадок, которые могли бы ввести систему в заблуждение.
Что показали эксперименты
Команда протестировала MAGNet на двух хорошо известных наборах видео с действиями человека — ходьбой, приветствиями, сидением и множеством других движений, снятых с разных ракурсов и при разном освещении. MAGNet достиг более высокой точности по сравнению с рядом сильных ранних методов, включая подходы, опирающиеся только на скелетные данные или на более жёсткие способы объединения входов. Он также лучше справлялся со сложными случаями, например при частичной или полной пропаже данных одного датчика, и при этом работал достаточно быстро для практического использования почти в реальном времени. Тщательные абляционные тесты подтвердили, что каждая часть конструкции — от адаптивного графа тела до механизма внимания и генеративного модуля — вносит вклад в эти улучшения.
Более ясное и надёжное понимание действий
Для неспециалиста основной вывод таков: MAGNet помогает компьютерам понимать движения человека подобно внимательному наблюдателю, который использует зрение, глубину и модель тела вместе, а не полагается на один ненадёжный сигнал. Гибко объединяя несколько видов сенсорных данных и интеллектуально заполняя пробелы, система сохраняет высокую точность распознавания даже в далеко не идеальных условиях. Это делает её перспективной основой для распознавания действий в повседневных сценариях — умных домах, анализе спорта и помощниках-роботах.
Цитирование: Dong, H., Zhang, F., Liu, C. et al. MAGNet: enhancing action recognition with multimodal fusion and adaptive graph convolution. Sci Rep 16, 15100 (2026). https://doi.org/10.1038/s41598-026-45601-2
Ключевые слова: распознавание действий человека, мультимодальное слияние, графовая нейронная сеть, компьютерное зрение, оценка позы