Clear Sky Science · it
MAGNet: migliorare il riconoscimento delle azioni con fusione multimodale e convoluzione adattiva su grafo
Insegnare ai computer a leggere i movimenti umani
Dai videogiochi che tracciano il corpo ai robot domestici che si muovono in sicurezza attorno alle persone, molte tecnologie dipendono da computer capaci di comprendere le azioni umane. La vita reale però è disordinata: la luce cambia, le persone camminano dietro ai mobili e alcuni sensori possono guastarsi. Questo studio presenta MAGNet, un nuovo sistema che aiuta i computer a riconoscere ciò che le persone stanno facendo con maggiore accuratezza e affidabilità nelle condizioni quotidiane.
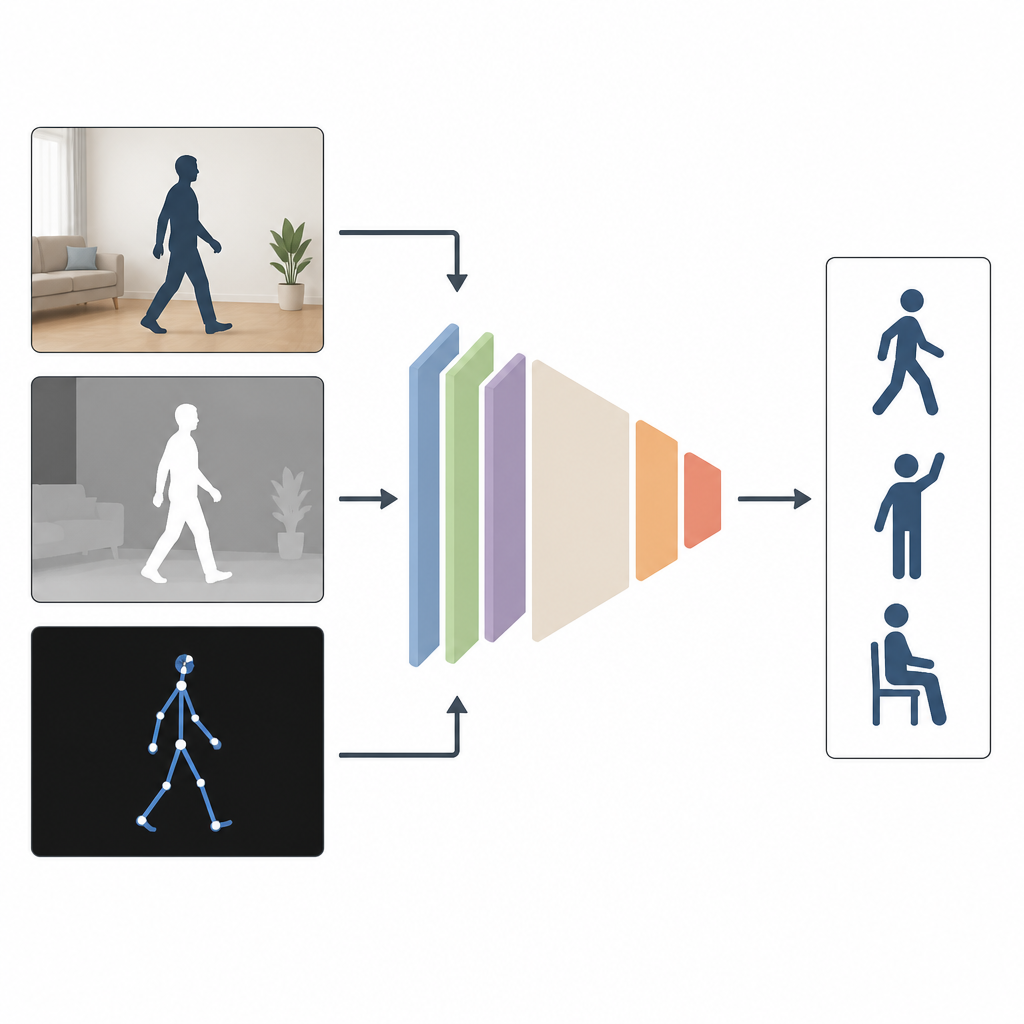
Perché vedere da più angolazioni aiuta
La maggior parte dei sistemi attuali osserva le persone usando un solo tipo di ingresso, ad esempio un video a colori. Questo funziona bene in laboratorio, ma non quando le stanze sono scure, le telecamere sono laterali o una parte del corpo è nascosta. Gli autori sostengono che combinare diversi tipi di informazione dia risultati migliori. MAGNet fonde tre viste della stessa azione: un'immagine a colori ordinaria che mostra l'aspetto, un'immagine di profondità che misura la distanza degli oggetti dalla camera e una descrizione a stick figure delle giunzioni corporee in 3D. Insieme, queste viste forniscono un quadro più ricco e completo di come una persona si muove.
Lasciare che la rete si adatti al corpo
Al centro di MAGNet c'è una struttura che tratta il corpo umano come una rete di punti connessi, come spalle, gomiti e ginocchia. Questo «grafo» indica al sistema quali giunzioni si influenzano a vicenda. MAGNet non mantiene questa struttura fissa. Al contrario, adatta la forza delle connessioni in base a ciò che i diversi sensori osservano. Se una camera di profondità mostra chiaramente un ginocchio piegato mentre l'immagine a colori è rumorosa, il sistema dà silenziosamente più fiducia al segnale di profondità per quella parte del corpo. Questo design adattivo del grafo aiuta MAGNet a seguire come la posa cambia nel tempo e a decidere quale sensore debba avere maggiore peso per ciascuna giunzione.
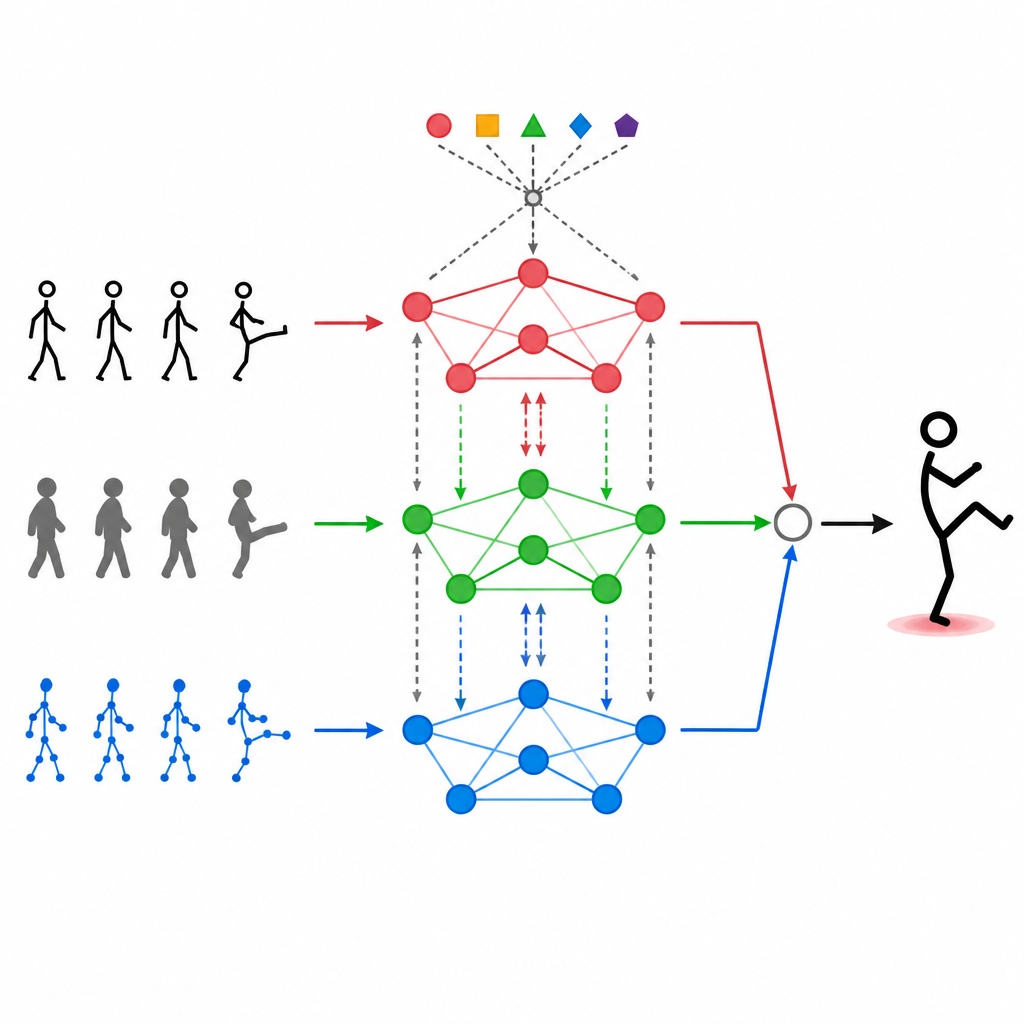
Lasciare che le modalità comunichino tra loro
Impilare semplicemente diversi flussi di dati uno sopra l'altro non è sufficiente. MAGNet usa un meccanismo di self-attention che permette a ciascun tipo di ingresso di «guardare» gli altri e decidere quanto debbano influenzarlo. In pratica, questo significa che il sistema può apprendere schemi del tipo «quando le giunzioni della mano si muovono in questo modo e l'immagine di profondità mostra questa forma, è probabile che si tratti di un saluto» e quindi rafforzare quei segnali combinati. Questo processo di attenzione avviene ripetutamente, raffinando il modo in cui le tre modalità vengono fuse in modo che le caratteristiche finali siano meglio allineate alle azioni umane reali e meno soggette a rumore o fotogrammi mancanti.
Colmare le lacune quando mancano i dati
I sensori del mondo reale si guastano, vengono bloccati o si desincronizzano. Per far fronte a ciò, gli autori aggiungono un modulo generativo basato su un metodo chiamato VQ-VAE che apprende i modi tipici in cui si muovono i corpi. Quando un tipo di dato è mancante o fortemente corrotto, questo componente può sintetizzare una versione plausibile dell'informazione mancante, come uno scheletro stimato o caratteristiche locali di posa, coerente con ciò che gli altri sensori osservano. È importante che il modello venga addestrato in modo che queste pose generate restino anatomicamente sensate e vicine alla categoria d'azione probabile, riducendo il rischio di congetture erratiche che potrebbero fuorviare il sistema.
Cosa mostrano gli esperimenti
Il team ha testato MAGNet su due collezioni ben note di video di azioni umane che includono camminare, salutare, sedersi e molti altri movimenti, registrati sotto punti di vista e condizioni di illuminazione variabili. MAGNet ha raggiunto una precisione superiore rispetto a una gamma di metodi precedenti di alto livello, inclusi quelli che si basano solo sugli scheletri o che usano modi più rigidi di combinare gli ingressi. Ha anche gestito meglio i casi difficili, come quando i dati di un sensore erano parzialmente o completamente assenti, e ha comunque funzionato abbastanza velocemente da risultare praticabile per un uso quasi in tempo reale. Test di ablazione accurati hanno confermato che ogni parte del design, dal grafo corporeo adattivo al meccanismo di attenzione e al modulo generativo, ha contribuito a questi miglioramenti.
Comprensione delle azioni più chiara e affidabile
Per un non esperto, la conclusione principale è che MAGNet aiuta i computer a comprendere i movimenti umani in modo più simile a un osservatore attento che usa insieme visione, profondità e un modello mentale del corpo, invece di affidarsi a un singolo indizio inaffidabile. Combinando in modo flessibile più viste sensoriali e colmando intelligentemente le lacune, il sistema mantiene alta la sua accuratezza di riconoscimento anche quando le condizioni sono lontane dall'ideale. Questo lo rende un progetto promettente per il riconoscimento delle azioni in contesti quotidiani come case intelligenti, analisi sportiva e robot di assistenza.
Citazione: Dong, H., Zhang, F., Liu, C. et al. MAGNet: enhancing action recognition with multimodal fusion and adaptive graph convolution. Sci Rep 16, 15100 (2026). https://doi.org/10.1038/s41598-026-45601-2
Parole chiave: riconoscimento delle azioni umane, fusione multimodale, reti neurali a grafo, visione artificiale, stima della posa