Clear Sky Science · he
MAGNet: שיפור זיהוי פעולות עם מיזוג מולטימודלי וקונבולוציה גרפית אדפטיבית
ללמד מחשבים לקרוא תנועות של בני אדם
ממשחקי וידאו שעוקבים אחרי גופך ועד רובוטים ביתיים שנעים בבטחה בין אנשים — טכנולוגיות רבות תלויות במחשבים שיכולים להבין פעולות אנושיות. אבל המציאות מבולגנת: התאורה משתנה, אנשים עוברים מאחורי רהיטים, וחלק מהחיישנים נכשלים. המחקר הזה מציג את MAGNet, מערכת חדשה שעוזרת למחשבים לזהות מה אנשים עושים בדיוק ובאמינות רבה יותר בתנאים יומיומיים.
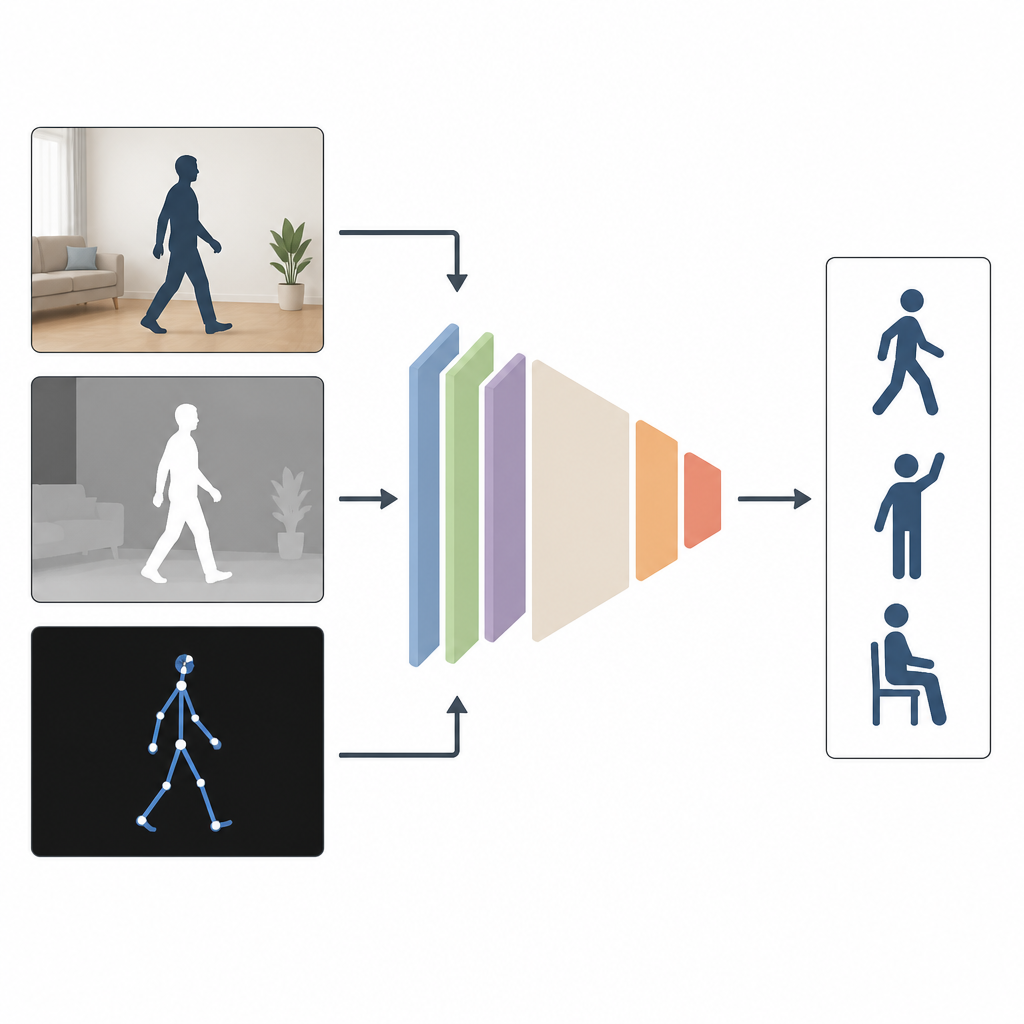
מדוע צפייה מזוויות רבות עוזרת
רוב המערכות העכשוויות מסתכלות על אנשים באמצעות סוג קלט יחיד, כמו וידאו צבעוני רגיל. זה עובד טוב במעבדה, אבל פחות כשחדרים חשוכים, מצלמות ממוקמות מהצד או חלק מהגוף מוסתר. הכותבים טוענים ששילוב מספר סוגי מידע עדיף. MAGNet ממזג שלושה מבטים של אותה פעולה: תמונת צבע רגילה שמציגה הופעה, תמונת עומק שמודדת מרחק של אובייקטים מהמצלמה ותיאור שלד מקל שמייצג את מפרקי הגוף בתלת־ממד. יחד, המבטרים האלה נותנים תמונה עשירה ומלאה יותר של האופן שבו מישהו נע.
לאפשר לרשת להסתגל לגוף
בלב MAGNet עומדת מבנה שמייחס לגוף האנושי רשת של נקודות מחוברות, כגון כתפיים, מרפקים וברכיים. ה"גרף" הזה אומר למערכת אילו מפרקים משפיעים זה על זה. MAGNet אינו משאיר מבנה זה קבוע. במקום זאת, הוא מתאים את חוזק הקשרים לפי מה שהחיישנים השונים רואים. אם מצלמת עומק מראה באופן ברור ברך כפופה בעוד שהתמונה הצבעונית רעשנית, המערכת נותנת בשקט משקל גבוה יותר לאות העומק באותו חלק של הגוף. עיצוב הגרף האדפטיבי הזה עוזר ל-MAGNet לעקוב אחרי שינויי תנוחה לאורך זמן ולהחליט איזה חיישן צריך להשפיע ביותר על כל מפרק.
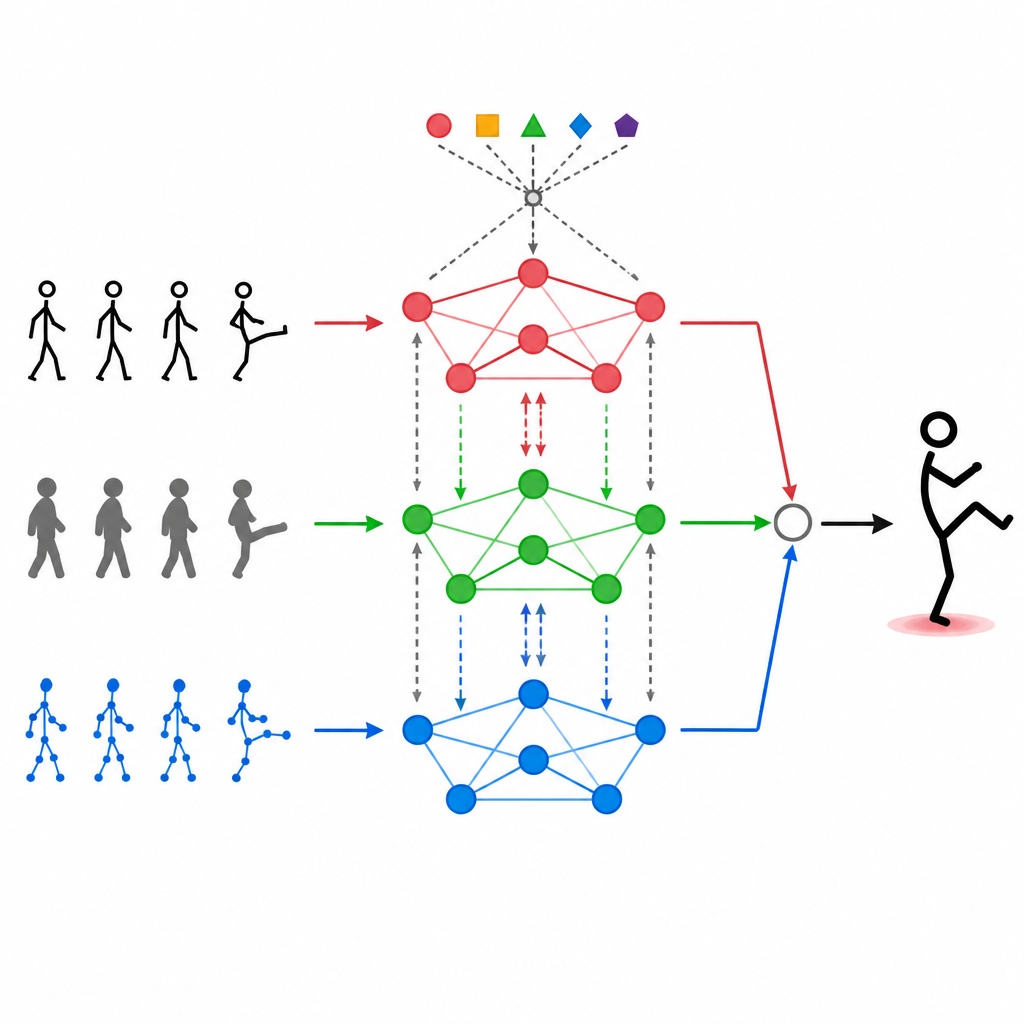
לאפשר למודאליות לתקשר זו עם זו
סימון פשוט של זרמי נתונים שונים זה מעל זה לא מספיק. MAGNet משתמש במנגנון תשומת לב עצמאי שמאפשר לכל סוג קלט "להסתכל" על האחרים ולהחליט כמה הם צריכים להשפיע עליו. בפועל, זה אומר שהמערכת יכולה ללמוד דפוסים כמו "כאשר מפרקי היד נעשים באופן זה ותמונת העומק מציגה צורה זו, כנראה שמדובר בלהתנופף" ואז לחזק אותות משולבים אלה. תהליך התשומת לב הזה חוזר על עצמו, ומשכלל את האופן שבו המודאליות השלוש מתמזגות כך שהתכונות הסופיות יתאימו טוב יותר לפעולות אנושיות אמיתיות ופחות יושפעו מרעש או פריימים חסרים.
למלא את החריצים כשהנתונים חסרים
חיישנים במציאות נכשלו, נחסמים או יוצאים מאיזון סינכרוני. כדי להתמודד עם זאת, המחברים מוסיפים מודול גנרטיבי המבוסס על שיטה הנקראת VQ-VAE שלומדת דרכי תנועה טיפוסיות של גופים. כאשר סוג נתונים חסר או נפגם בצורה קשה, רכיב זה יכול לסנתז גרסה סבירה של המידע החסר, כמו שלד משוער או תכונות תנוחה מקומיות, התואמת למה שהחיישנים הנותרים רואים. באופן חשוב, המודל מאומן כך שהתנוחות המיוצרות יישארו אנטומית־מגובשות ותישארנה קרובות לקטגוריית הפעולה הסבירה, וכך מצמצמות את הסיכון לניחושים שגויים שיכולים להטעות את המערכת.
מה שהניסויים מראים
הצוות בחן את MAGNet על שתי אוספות ידועות של סרטוני פעולות אנושיות הכוללות הליכה, התנופפות, ישיבה ועוד תנועות, שהוקלטו מזוויות ותנאי תאורה שונים. MAGNet השיג דיוק גבוה יותר ממגוון שיטות מוקדמות חזקות, כולל אלה המתבססות רק על שלדים או שימוש בשיטות קשיחות יותר למיזוג קלטים. הוא טיפל גם במקרים מאתגרים טוב יותר, כגון כאשר נתוני חיישן חלקיים או חסרים לחלוטין, ועדיין רץ במהירות מספקת לשימוש כמעט בזמן אמת. ניסויי א־בליישן מדוקדקים אישרו שכל חלק בעיצוב — מהגרף האדפטיבי של הגוף ועד מנגנון התשומת לב והמודול הגנרטיבי — תרם לשיפורים אלה.
הבנה ברורה ואמינה יותר של פעולות
ללא מומחיות מיוחדת, המסקנה המרכזית היא ש-MAGNet עוזר למחשבים להבין תנועות אנושיות כמו צופה זהיר שמשלב ראייה, עומק ומודל מנטלי של הגוף, במקום להסתמך על רמז יחיד בלתי אמין. על ידי שילוב גמיש של מבטי חיישנים מרובים ומילוי חכם של מרווחים, המערכת שומרת על דיוק זיהוי גבוה גם כאשר התנאים רחוקים ממושלמים. זה הופך את המערכת לתבנית מבטיחה לזיהוי פעולות בסביבות יומיומיות כמו בתים חכמים, ניתוח ספורט ורובוטים מסייעים.
ציטוט: Dong, H., Zhang, F., Liu, C. et al. MAGNet: enhancing action recognition with multimodal fusion and adaptive graph convolution. Sci Rep 16, 15100 (2026). https://doi.org/10.1038/s41598-026-45601-2
מילות מפתח: זיהוי פעולות אנושיות, מיזוג מולטימודלי, רשת עצבית גרפית, ראיית מכונה, אמדן תנוחה