Clear Sky Science · fr
MAGNet : améliorer la reconnaissance d’actions par fusion multimodale et convolution de graphe adaptative
Apprendre aux ordinateurs à lire les mouvements humains
Des jeux vidéo qui suivent votre corps aux robots domestiques qui se déplacent en sécurité autour des personnes, de nombreuses technologies reposent sur des ordinateurs capables de comprendre les actions humaines. Mais la vie réelle est désordonnée : la lumière change, des personnes passent derrière des meubles et certains capteurs peuvent tomber en panne. Cette étude présente MAGNet, un nouveau système qui aide les ordinateurs à reconnaître ce que font les gens avec plus de précision et de fiabilité dans des conditions quotidiennes.
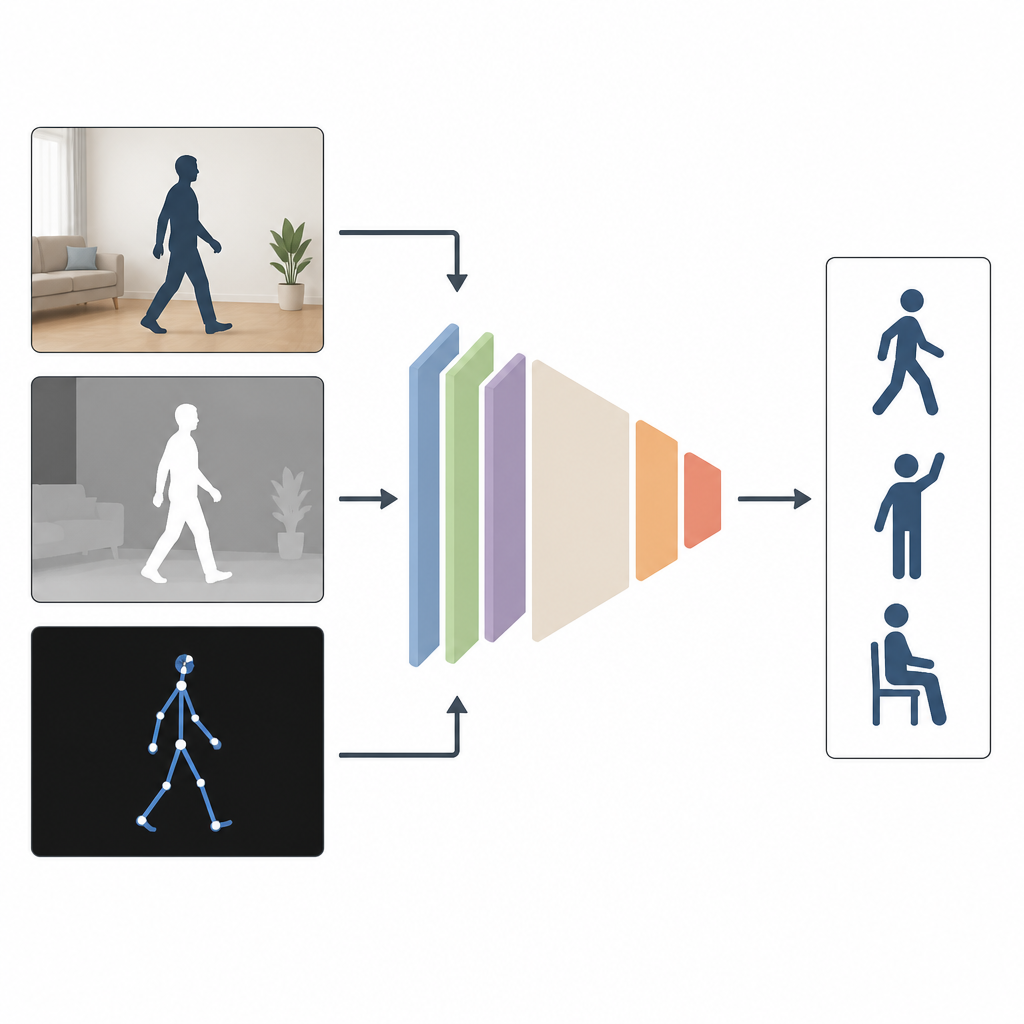
Pourquoi voir sous plusieurs angles aide
La plupart des systèmes actuels observent les personnes avec un seul type d’entrée, comme une vidéo couleur classique. Cela fonctionne bien en laboratoire, mais moins quand les pièces sont peu éclairées, que les caméras sont décalées ou qu’une partie du corps est cachée. Les auteurs soutiennent que la combinaison de plusieurs types d’information est plus efficace. MAGNet fusionne trois vues de la même action : une image couleur ordinaire qui rend l’apparence, une image de profondeur qui mesure la distance des objets à la caméra, et une description en « squelette » des articulations du corps en 3D. Ensemble, ces vues offrent une image plus riche et plus complète du mouvement d’une personne.
Permettre au réseau de s’adapter au corps
Au cœur de MAGNet se trouve une structure qui traite le corps humain comme un réseau de points connectés, par exemple épaules, coudes et genoux. Ce « graphe » indique au système quelles articulations s’influencent mutuellement. MAGNet ne maintient pas cette structure fixe. Il ajuste la force des connexions en fonction de ce que perçoivent les différents capteurs. Si une caméra de profondeur montre clairement un genou plié alors que l’image couleur est bruitée, le système accorde silencieusement plus de confiance au signal de profondeur pour cette partie du corps. Ce graphe adaptatif aide MAGNet à suivre l’évolution d’une pose dans le temps et à décider quel capteur doit primer pour chaque articulation.
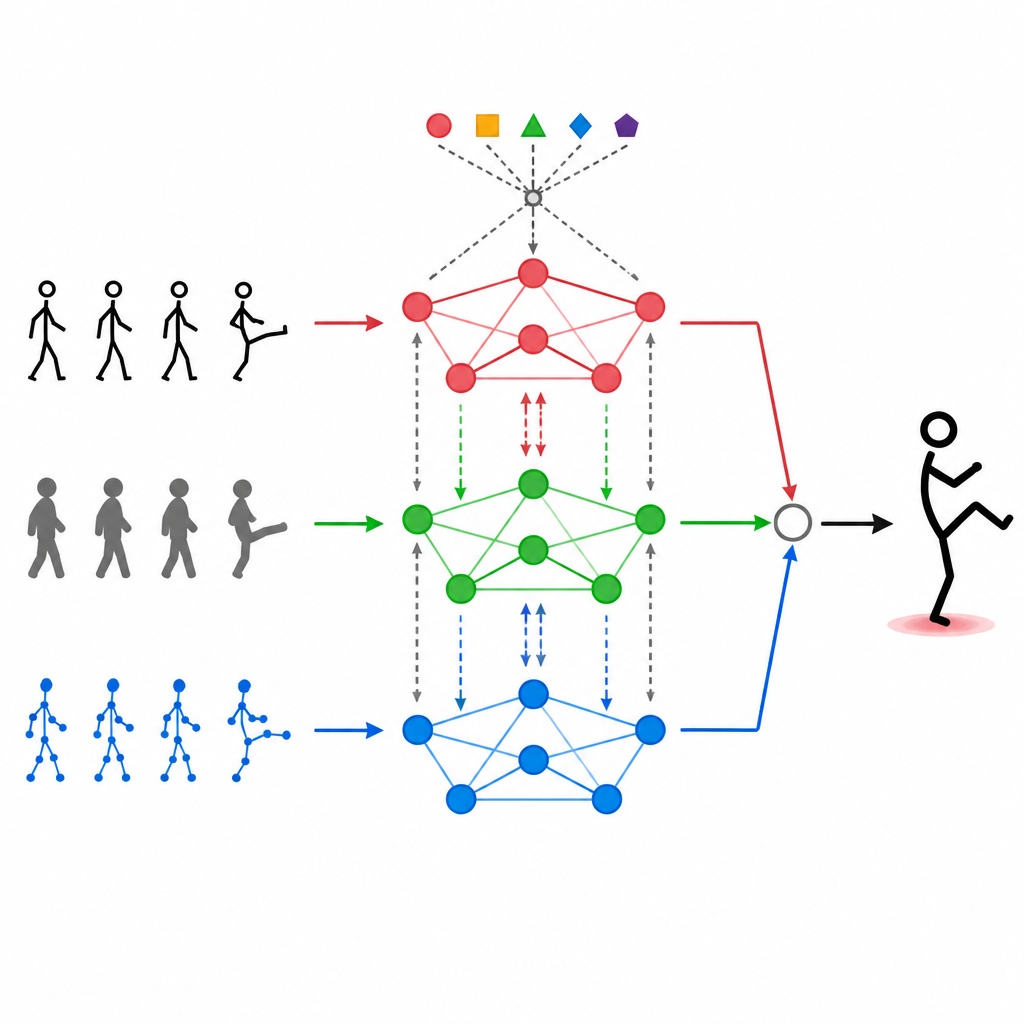
Permettre aux modalités de dialoguer
Empiler simplement différentes sources de données ne suffit pas. MAGNet utilise un mécanisme d’auto-attention qui permet à chaque type d’entrée de « regarder » les autres et de décider dans quelle mesure elles doivent l’influencer. Concrètement, cela signifie que le système peut apprendre des motifs tels que « quand les articulations de la main bougent de cette façon et que l’image de profondeur montre cette forme, il s’agit probablement d’un salut » et renforcer ces signaux combinés. Ce processus d’attention se répète, affinant la manière dont les trois modalités sont fusionnées pour que les caractéristiques finales correspondent mieux aux actions humaines réelles et soient moins affectées par le bruit ou les images manquantes.
Combler les lacunes quand les données manquent
Les capteurs du monde réel tombent en panne, sont obstrués ou se désynchronisent. Pour faire face à cela, les auteurs ajoutent un module génératif basé sur une méthode appelée VQ-VAE qui apprend les façons typiques dont les corps se déplacent. Lorsqu’un type de donnée est absent ou fortement corrompu, ce composant peut synthétiser une version plausible de l’information manquante, par exemple un squelette estimé ou des caractéristiques locales de pose, cohérente avec ce que voient les capteurs restants. Il est important que le modèle soit entraîné pour que ces poses générées restent anatomiquement crédibles et proches de la catégorie d’action probable, réduisant ainsi le risque de conjectures erratiques qui induiraient le système en erreur.
Ce que montrent les expériences
L’équipe a testé MAGNet sur deux collections bien connues de vidéos d’actions humaines incluant marche, salut, assis et bien d’autres mouvements, enregistrées sous des points de vue et des éclairages variés. MAGNet a atteint une précision supérieure à celle d’une série de méthodes précédentes performantes, y compris celles qui s’appuient uniquement sur les squelettes ou qui combinent les entrées de manière plus rigide. Il a également mieux géré les cas difficiles, par exemple lorsque les données d’un capteur étaient partiellement ou totalement manquantes, et a conservé des performances assez rapides pour être pratique en quasi temps réel. Des tests d’ablation soigneux ont confirmé que chaque composant de la conception, du graphe corporel adaptatif au mécanisme d’attention en passant par le module génératif, a contribué à ces gains.
Une compréhension des actions plus claire et plus fiable
Pour un non‑spécialiste, l’essentiel est que MAGNet aide les ordinateurs à comprendre les mouvements humains de façon plus proche d’un observateur attentif qui combine la vue, la profondeur et un modèle mental du corps, plutôt que de se fier à un seul indice peu fiable. En combinant de manière flexible plusieurs vues de capteurs et en comblant intelligemment les lacunes, le système maintient une précision de reconnaissance élevée même lorsque les conditions sont loin d’être parfaites. Cela en fait un modèle prometteur pour la reconnaissance d’actions dans des environnements quotidiens comme la maison intelligente, l’analyse sportive et les robots d’assistance.
Citation: Dong, H., Zhang, F., Liu, C. et al. MAGNet: enhancing action recognition with multimodal fusion and adaptive graph convolution. Sci Rep 16, 15100 (2026). https://doi.org/10.1038/s41598-026-45601-2
Mots-clés: reconnaissance d’actions humaines, fusion multimodale, réseau de neurones sur graphe, vision par ordinateur, estimation de pose