Clear Sky Science · es
MAGNet: mejorando el reconocimiento de acciones con fusión multimodal y convolución gráfica adaptativa
Enseñar a las máquinas a interpretar los movimientos humanos
Desde videojuegos que rastrean tu cuerpo hasta robots domésticos que se desplazan con seguridad entre personas, muchas tecnologías dependen de sistemas capaces de entender las acciones humanas. Sin embargo, la vida real es desordenada: cambia la iluminación, la gente pasa detrás de los muebles y algunos sensores fallan. Este estudio presenta MAGNet, un nuevo sistema que ayuda a las máquinas a reconocer lo que hacen las personas con mayor precisión y fiabilidad en condiciones cotidianas.
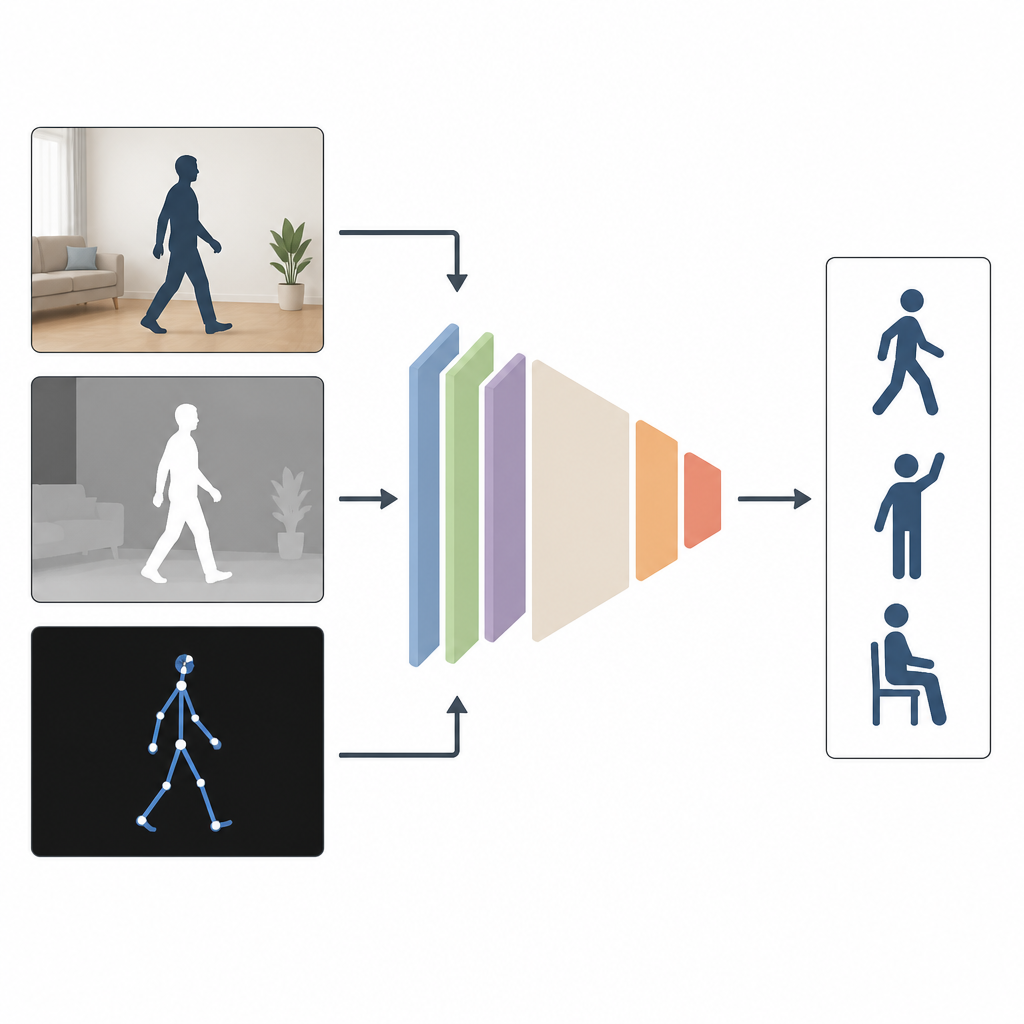
Por qué ver desde varios ángulos ayuda
La mayoría de los sistemas actuales observan a las personas usando un solo tipo de entrada, como un vídeo en color. Eso funciona bien en laboratorio, pero no cuando las habitaciones están oscuras, las cámaras están de lado o parte del cuerpo está oculto. Los autores sostienen que combinar varios tipos de información funciona mejor. MAGNet integra tres vistas de la misma acción: una imagen en color que muestra la apariencia, una imagen de profundidad que mide la distancia de los objetos a la cámara y una descripción en forma de esqueleto de las articulaciones en 3D. Juntas, estas vistas ofrecen una imagen más rica y completa de cómo se mueve una persona.
Permitir que la red se adapte al cuerpo
En el núcleo de MAGNet hay una estructura que trata el cuerpo humano como una red de puntos conectados, como hombros, codos y rodillas. Este «grafo» indica al sistema qué articulaciones se influyen entre sí. MAGNet no mantiene esta estructura fija. En su lugar, ajusta la fuerza de las conexiones según lo que ven los distintos sensores. Si una cámara de profundidad muestra claramente una rodilla doblada mientras la imagen en color tiene mucho ruido, el sistema confía más en la señal de profundidad para esa parte del cuerpo. Este diseño de grafo adaptativo ayuda a MAGNet a seguir cómo cambia la pose en el tiempo y a decidir qué sensor debe «hablar» más fuerte en cada articulación.
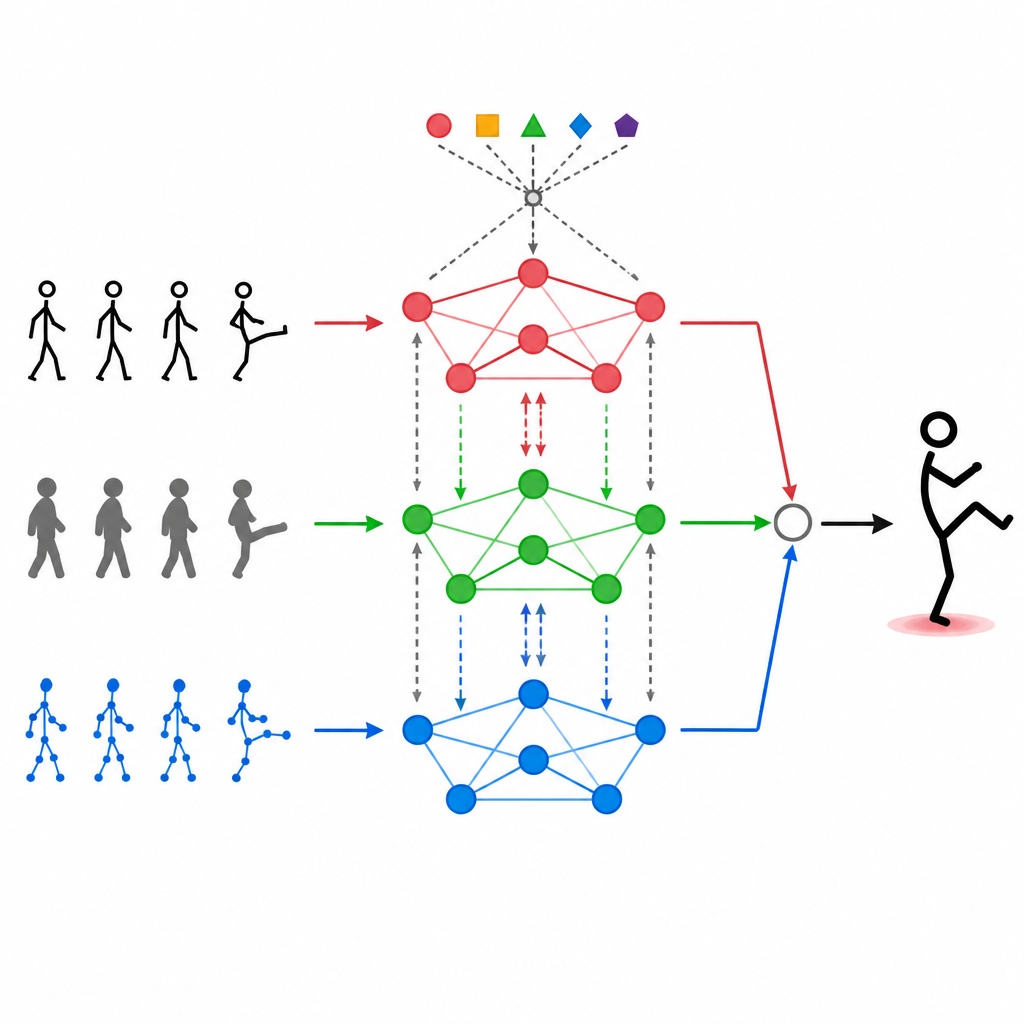
Permitir que las modalidades se comuniquen entre sí
Apilar distintos flujos de datos no es suficiente. MAGNet utiliza un mecanismo de autoatención que permite que cada tipo de entrada «mire» a las demás y decida cuánto deben influir en ella. En la práctica, esto significa que el sistema puede aprender patrones como «cuando las articulaciones de la mano se mueven de esta forma y la imagen de profundidad muestra esta silueta, lo más probable es que sea un saludo» y potenciar esas señales combinadas. Este proceso de atención se repite, refinando la fusión de las tres modalidades para que las características finales se alineen mejor con las acciones humanas reales y resulten menos afectadas por ruido o fotogramas perdidos.
Rellenar los huecos cuando faltan datos
En el mundo real, los sensores fallan, se bloquean o se desincronizan. Para hacer frente a esto, los autores añaden un módulo generativo basado en un método llamado VQ-VAE que aprende las formas típicas de movimiento del cuerpo. Cuando falta un tipo de dato o está muy corrupto, este componente puede sintetizar una versión plausible de la información ausente, por ejemplo un esqueleto estimado o características locales de la pose, consistente con lo que ven los sensores restantes. Es importante que el modelo se entrene para que estas poses generadas sean anatómicamente razonables y se mantengan cercanas a la categoría de acción probable, reduciendo el riesgo de conjeturas erráticas que podrían inducir a error al sistema.
Qué muestran los experimentos
El equipo evaluó MAGNet en dos colecciones bien conocidas de vídeos de acciones humanas que incluyen caminar, saludar, sentarse y muchos otros movimientos, grabados bajo distintos ángulos e iluminaciones. MAGNet alcanzó mayor precisión que varios métodos previos de referencia, incluidos aquellos que solo usan esqueletos o que emplean formas más rígidas de combinar entradas. También manejó mejor casos difíciles, como cuando los datos de un sensor estaban parcial o completamente ausentes, y todavía funcionó con suficiente rapidez como para ser práctico en usos casi en tiempo real. Pruebas de ablación cuidadosas confirmaron que cada parte del diseño —desde el grafo corporal adaptativo hasta el mecanismo de atención y el módulo generativo— contribuyó a estas mejoras.
Comprensión de acciones más clara y fiable
Para un público no experto, la conclusión clave es que MAGNet ayuda a las máquinas a entender los movimientos humanos más como un observador cuidadoso que combina visión, profundidad y un modelo corporal, en lugar de confiar en una sola pista poco fiable. Al combinar de forma flexible múltiples vistas de sensores y rellenar inteligentemente los huecos, el sistema mantiene alta su precisión de reconocimiento incluso cuando las condiciones están lejos de ser ideales. Esto lo convierte en un esquema prometedor para el reconocimiento de acciones en entornos cotidianos como hogares inteligentes, análisis deportivo y robots asistenciales.
Cita: Dong, H., Zhang, F., Liu, C. et al. MAGNet: enhancing action recognition with multimodal fusion and adaptive graph convolution. Sci Rep 16, 15100 (2026). https://doi.org/10.1038/s41598-026-45601-2
Palabras clave: reconocimiento de acciones humanas, fusión multimodal, red neuronal gráfica, visión por computador, estimación de pose