Clear Sky Science · sv
MAGNet: förbättrad actionigenkänning med multimodal fusion och adaptiv grafkonvolution
Lära datorer att läsa mänskliga rörelser
Från videospel som följer din kropp till hemmarobotar som rör sig säkert kring människor, många tekniker bygger på att datorer kan förstå mänskliga handlingar. Men verkligheten är rörig: ljusförhållanden ändras, människor går bakom möbler och vissa sensorer slutar fungera. Denna studie presenterar MAGNet, ett nytt system som hjälper datorer att känna igen vad människor gör mer exakt och mer pålitligt i vardagliga situationer.
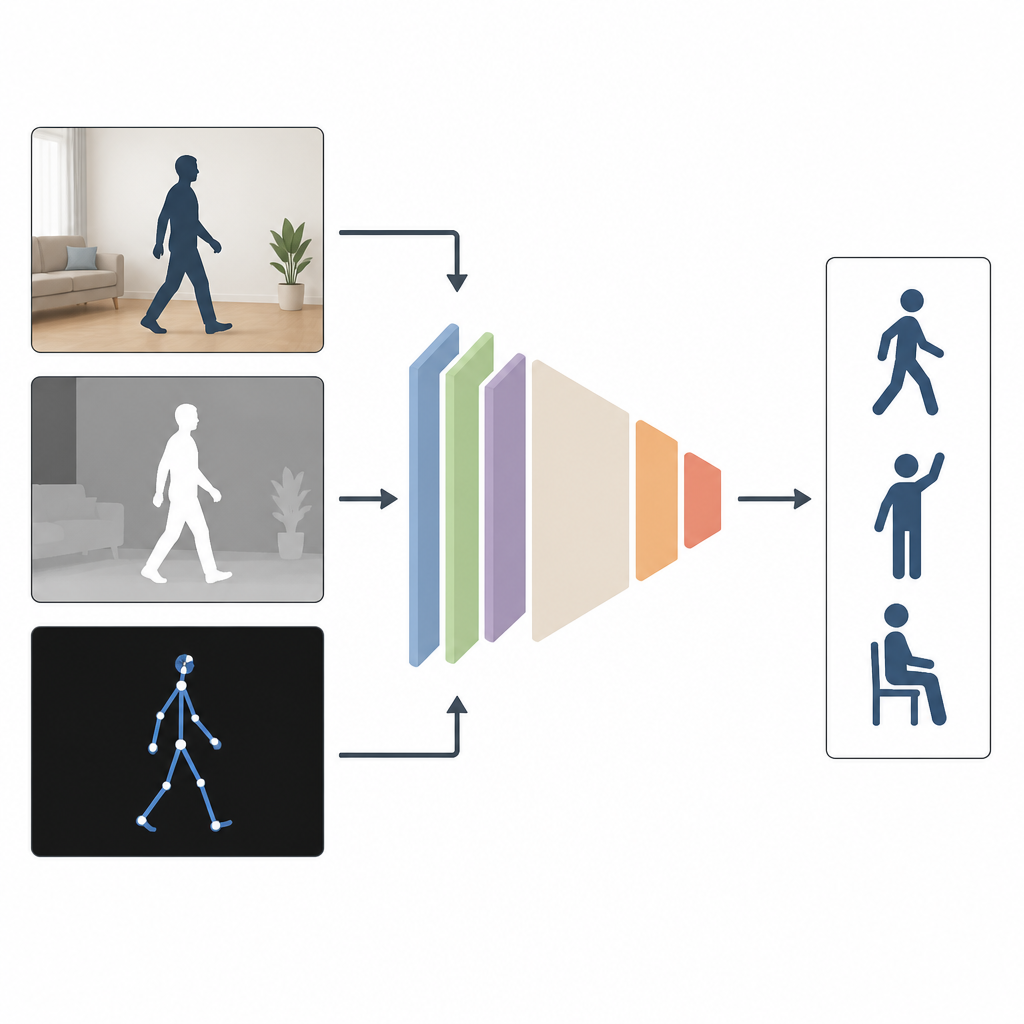
Varför det hjälper att se från flera vinklar
De flesta nuvarande system ser på människor med bara en typ av indata, till exempel färgvideo. Det fungerar bra i ett laboratorium, men inte när rummen är mörka, kameran är placerad snett eller delar av kroppen är dolda. Författarna menar att en kombination av flera informationsslag fungerar bättre. MAGNet blandar tre vyer av samma handling: en vanlig färgbild som visar utseende, en djupbild som mäter hur långt objekt ligger från kameran, och en pinne-figur som beskriver personens kroppsleder i 3D. Tillsammans ger dessa vyer en rikare, mer komplett bild av hur någon rör sig.
Låta nätverket anpassa sig efter kroppen
I hjärtat av MAGNet finns en struktur som behandlar kroppen som ett nätverk av sammankopplade punkter, som axlar, armbågar och knän. Denna "graf" berättar för systemet vilka leder som påverkar varandra. MAGNet håller inte denna struktur statisk. Istället justerar det kopplingarnas styrka baserat på vad de olika sensorerna ser. Om en djupkamera tydligt visar ett böjt knä medan färgbilden är brusig, litar systemet mer på djupinformationen för den delen av kroppen. Denna adaptiva grafdesign hjälper MAGNet att följa hur en pose förändras över tid och avgöra vilken sensor som bör ha mest inflytande i varje led.
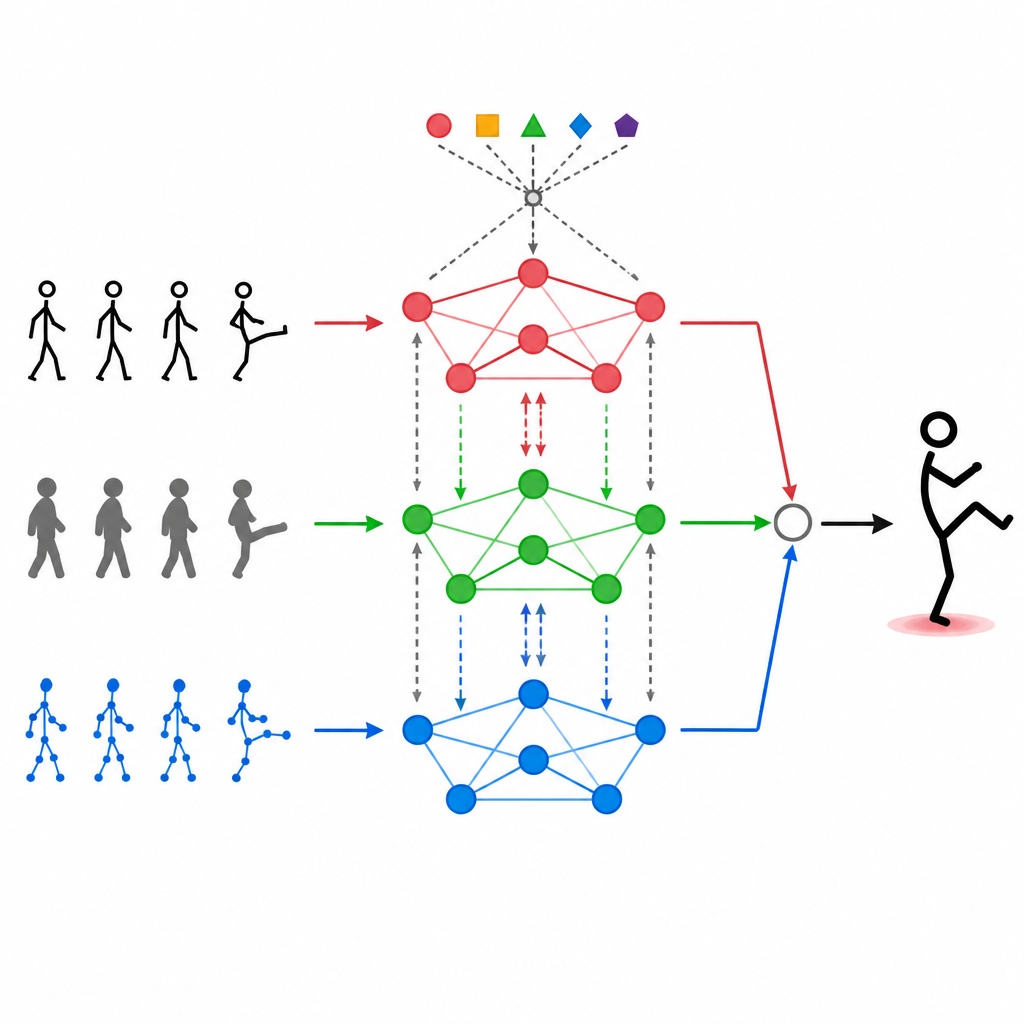
Låta modaliteterna tala med varandra
Att bara stapla olika dataströmmar ovanpå varandra räcker inte. MAGNet använder en självuppmärksamhetsmekanism som låter varje inmatningstyp "titta" på de andra och avgöra hur mycket de ska påverka den. I praktiken innebär detta att systemet kan lära sig mönster som "när handlederna rör sig på detta sätt och djupbilden visar denna form är det sannolikt en vinkning" och sedan förstärka dessa kombinerade signaler. Denna uppmärksamhetsprocess sker upprepade gånger och förfinar hur de tre modaliteterna smälts samman så att de slutliga egenskaperna bättre överensstämmer med verkliga mänskliga handlingar och påverkas mindre av brus eller saknade bildrutor.
Fyller i luckorna när data saknas
Verkliga sensorer fallerar, blockeras eller kommer ur synk. För att hantera detta lägger författarna till en generativ modul baserad på en metod som kallas VQ-VAE, som lär sig typiska sätt kroppar rör sig på. När en typ av data saknas eller är svårt korrupt kan denna komponent syntetisera en rimlig version av den saknade informationen, såsom ett uppskattat skelett eller lokala pose-egenskaper, som är förenlig med vad de kvarvarande sensorerna visar. Viktigt är att modellen tränas så att dessa genererade poser förblir anatomiskt rimliga och nära den sannolika handlingkategorin, vilket minskar risken för vilda gissningar som kan vilseleda systemet.
Vad experimenten visar
Teamet testade MAGNet på två välkända samlingar av videor med mänskliga handlingar som inkluderar att gå, vinka, sitta och många andra rörelser, inspelade under varierande synvinklar och ljusförhållanden. MAGNet nådde högre noggrannhet än en rad starka tidigare metoder, inklusive sådana som endast förlitar sig på skelettdata eller som använder mer stelbenta sätt att kombinera indatan. Det hanterade också svåra fall bättre, till exempel när en sensors data delvis eller helt saknades, och kördes fortfarande tillräckligt snabbt för att vara praktiskt för nästan realtidsanvändning. Noggranna ablationstester bekräftade att varje del av designen, från den adaptiva kroppsgrafen till uppmärksamhetsmekanismen och den generativa modulen, bidrog till dessa förbättringar.
Klarare, mer pålitlig actionförståelse
För en icke-expert är huvudpoängen att MAGNet hjälper datorer att förstå mänskliga rörelser mer som en uppmärksam observatör som använder syn, djup och en mental kroppsmodell tillsammans, istället för att förlita sig på ett enda opålitligt tecken. Genom att flexibelt kombinera flera sensorvyer och intelligent fylla i luckor håller systemet sin igenkänningsnoggrannhet hög även när förhållandena är långt ifrån perfekta. Det gör det till en lovande mall för actionigenkänning i vardagliga miljöer som smarta hem, sportanalys och assistansrobotar.
Citering: Dong, H., Zhang, F., Liu, C. et al. MAGNet: enhancing action recognition with multimodal fusion and adaptive graph convolution. Sci Rep 16, 15100 (2026). https://doi.org/10.1038/s41598-026-45601-2
Nyckelord: igenkänning av mänskliga handlingar, multimodal fusion, grafneuralnätverk, datorseende, pose-estimering