Clear Sky Science · de
MAGNet: Verbesserung der Aktionserkennung durch multimodale Fusion und adaptive Graphkonvolution
Computern beibringen, menschliche Bewegungen zu lesen
Von Videospielen, die Ihren Körper verfolgen, bis zu Haushaltsrobotern, die sich sicher um Personen bewegen: Viele Technologien sind darauf angewiesen, dass Computer menschliche Handlungen verstehen. Die Realität ist jedoch unordentlich: Lichtverhältnisse ändern sich, Menschen laufen hinter Möbeln vorbei und einige Sensoren versagen. Diese Studie stellt MAGNet vor, ein neues System, das Computern hilft, in Alltagsbedingungen genauer und zuverlässiger zu erkennen, was Menschen tun.
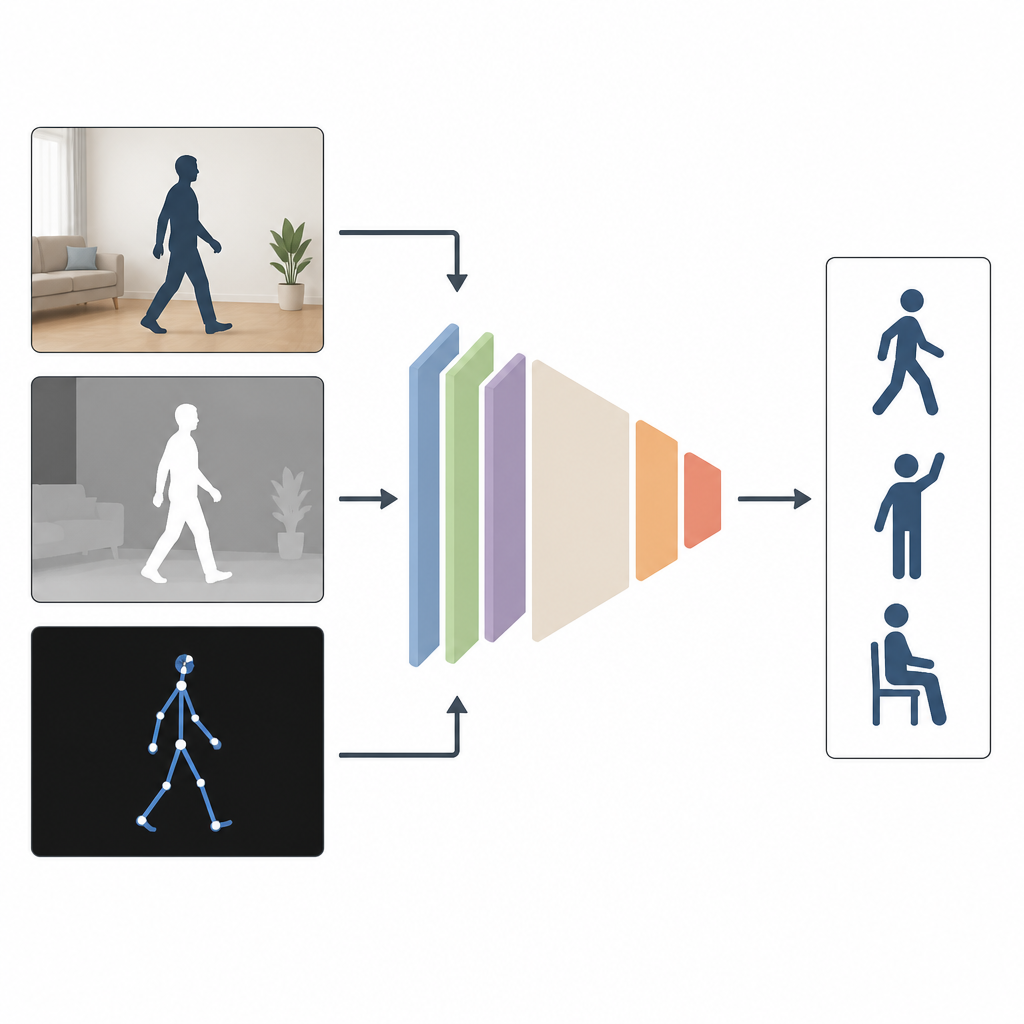
Warum das Sehen aus vielen Blickwinkeln hilft
Die meisten aktuellen Systeme beobachten Personen nur mit einer Eingabeart, etwa einem normalen Farbvideo. Das funktioniert im Labor gut, aber nicht, wenn Räume dunkel sind, Kameras seitlich angebracht sind oder Körperteile verdeckt sind. Die Autoren argumentieren, dass die Kombination mehrerer Informationsarten besser ist. MAGNet vereint drei Sichten derselben Aktion: ein gewöhnliches Farbbild, das das Aussehen zeigt, ein Tiefenbild, das die Entfernung von Objekten zur Kamera misst, und eine Strichfigurdarstellung der Körpergelenke in 3D. Zusammen liefern diese Sichten ein reichhaltigeres, vollständigeres Bild davon, wie sich jemand bewegt.
Das Netzwerk an den Körper anpassen lassen
Kernstück von MAGNet ist eine Struktur, die den menschlichen Körper als Netzwerk verbundener Punkte wie Schultern, Ellbogen und Knie behandelt. Dieser "Graph" sagt dem System, welche Gelenke sich gegenseitig beeinflussen. MAGNet hält diese Struktur nicht starr. Stattdessen passt es die Stärke der Verbindungen darauf an, was die verschiedenen Sensoren sehen. Wenn eine Tiefenkamera ein deutlich gebeugtes Knie zeigt, während das Farbvideo verrauscht ist, vertraut das System für diesen Bereich stillschweigend stärker dem Tiefensignal. Dieses adaptive Graphdesign hilft MAGNet, wie sich eine Pose im Zeitverlauf verändert zu verfolgen und zu entscheiden, welcher Sensor an jedem Gelenk am stärksten gewichtet werden sollte.
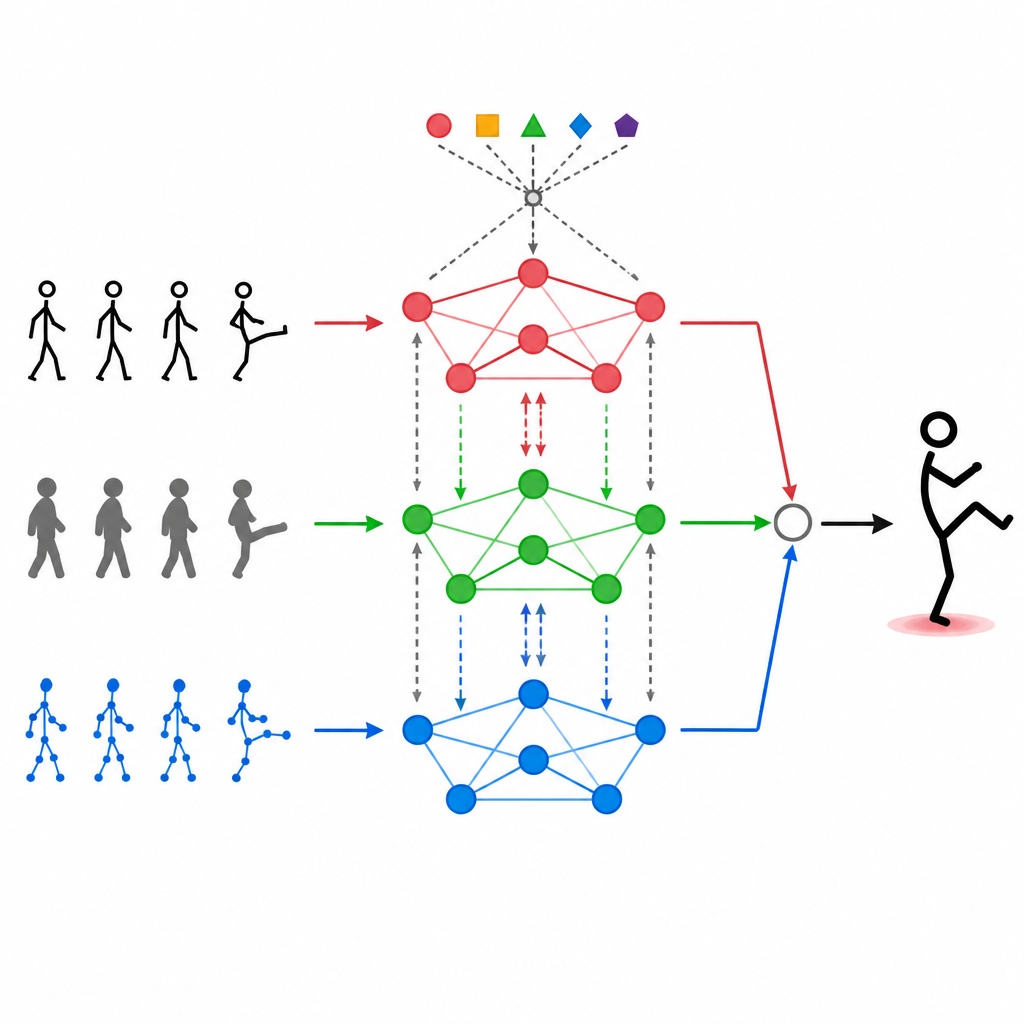
Modalitäten miteinander sprechen lassen
Verschiedene Datenströme einfach übereinander zu stapeln reicht nicht aus. MAGNet nutzt einen Self-Attention-Mechanismus, der jeder Eingabeart erlaubt, die anderen zu "betrachten" und zu entscheiden, wie stark sie diese beeinflussen sollen. In der Praxis kann das System so Muster lernen wie „wenn sich die Handgelenke auf diese Weise bewegen und das Tiefenbild diese Form zeigt, handelt es sich wahrscheinlich um ein Winken“ und diese kombinierten Signale verstärken. Dieser Aufmerksamkeitsprozess wiederholt sich und verfeinert die Fusion der drei Modalitäten, sodass die finalen Merkmale besser mit realen menschlichen Aktionen übereinstimmen und weniger durch Rauschen oder fehlende Frames gestört werden.
Fehlende Daten plausibel ergänzen
Sensoren fallen in der realen Welt aus, werden blockiert oder geraten außer Takt. Um damit umzugehen, fügen die Autoren ein generatives Modul auf Basis einer Methode namens VQ-VAE hinzu, das typische Körperbewegungen erlernt. Wenn eine Datenart fehlt oder stark gestört ist, kann dieses Modul eine plausible Version der fehlenden Information synthetisieren, etwa ein geschätztes Skelett oder lokale Pose-Merkmale, die mit den übrigen Sensoren konsistent sind. Wichtig ist, dass das Modell so trainiert wird, dass diese generierten Posen anatomisch sinnvoll bleiben und nahe an der wahrscheinlichen Aktionskategorie liegen, wodurch das Risiko von unplausiblen Vermutungen reduziert wird, die das System in die Irre führen könnten.
Was die Experimente zeigen
Das Team testete MAGNet an zwei bekannten Datensätzen mit menschlichen Aktionsvideos, die Gehen, Winken, Sitzen und viele andere Bewegungen unter verschiedenen Blickwinkeln und Lichtverhältnissen enthalten. MAGNet erreichte höhere Genauigkeit als eine Reihe starker früherer Methoden, einschließlich solcher, die nur auf Skeletten beruhen oder starrere Verfahren zur Eingabefusion verwenden. Es meisterte auch schwierige Fälle besser, etwa wenn die Daten eines Sensors teilweise oder vollständig fehlten, und lief noch schnell genug für eine praktische nahezu Echtzeitanwendung. Sorgfältige Ablationsstudien bestätigten, dass jeder Teil des Designs — vom adaptiven Körpergraphen über den Aufmerksamkeitsmechanismus bis zum generativen Modul — zu diesen Verbesserungen beitrug.
Deutlichere, zuverlässigere Aktionserkennung
Für Nicht-Experten lautet die wichtigste Erkenntnis: MAGNet hilft Computern, menschliche Bewegungen eher wie ein aufmerksamer Beobachter zu verstehen, der Sicht, Tiefe und ein mentales Körpermodell zusammen nutzt, statt sich auf ein einziges unzuverlässiges Signal zu verlassen. Durch die flexible Kombination mehrerer Sensoransichten und das intelligente Schließen von Lücken hält das System seine Erkennungsgenauigkeit hoch, selbst wenn die Bedingungen weit von ideal sind. Das macht MAGNet zu einem vielversprechenden Vorbild für Aktionserkennung in Alltagsumgebungen wie Smart Homes, Sportanalyse und assistiven Robotern.
Zitation: Dong, H., Zhang, F., Liu, C. et al. MAGNet: enhancing action recognition with multimodal fusion and adaptive graph convolution. Sci Rep 16, 15100 (2026). https://doi.org/10.1038/s41598-026-45601-2
Schlüsselwörter: Erkennung menschlicher Aktionen, multimodale Fusion, Graphneuronales Netzwerk, Computer Vision, Pose-Schätzung