Clear Sky Science · en
MAGNet: enhancing action recognition with multimodal fusion and adaptive graph convolution
Teaching Computers to Read Human Moves
From video games that track your body to home robots that move safely around people, many technologies depend on computers that can understand human actions. Yet real life is messy: lighting changes, people walk behind furniture, and some sensors fail. This study presents MAGNet, a new system that helps computers recognize what people are doing more accurately and more reliably in everyday conditions.
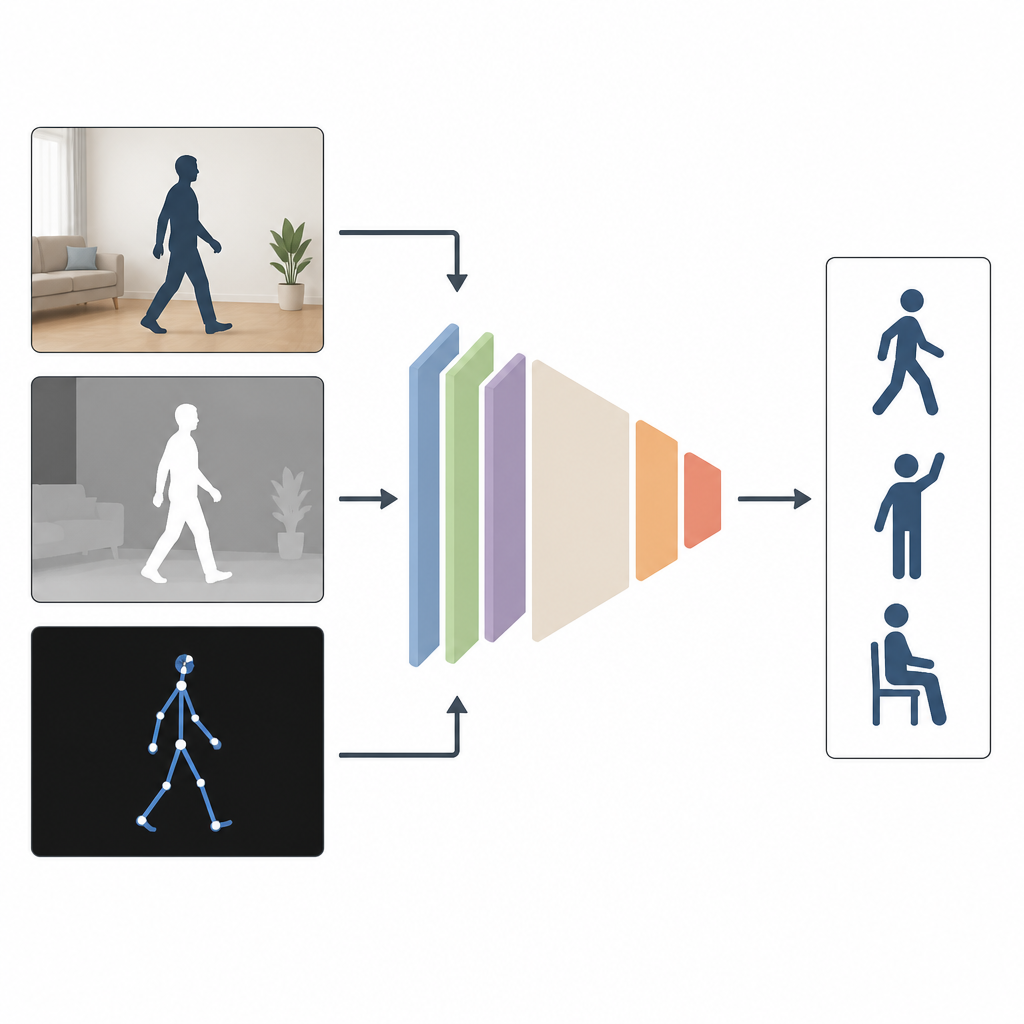
Why Seeing from Many Angles Helps
Most current systems watch people using just one type of input, such as a regular color video. That works well in a lab, but not when rooms are dim, cameras are off to the side, or part of the body is hidden. The authors argue that combining several kinds of information works better. MAGNet blends three views of the same action: an ordinary color image that shows appearance, a depth image that measures how far objects are from the camera, and a stick figure description of the person’s body joints in 3D. Together, these views give a richer, more complete picture of how someone is moving.
Letting the Network Adapt to the Body
At the heart of MAGNet is a structure that treats the human body like a network of connected points, such as shoulders, elbows, and knees. This "graph" tells the system which joints influence one another. MAGNet does not keep this structure fixed. Instead, it adjusts the strength of the connections based on what the different sensors are seeing. If a depth camera clearly shows a bent knee while the color image is noisy, the system quietly trusts the depth signal more for that part of the body. This adaptive graph design helps MAGNet follow how a pose changes over time and decide which sensor should speak the loudest at each joint.
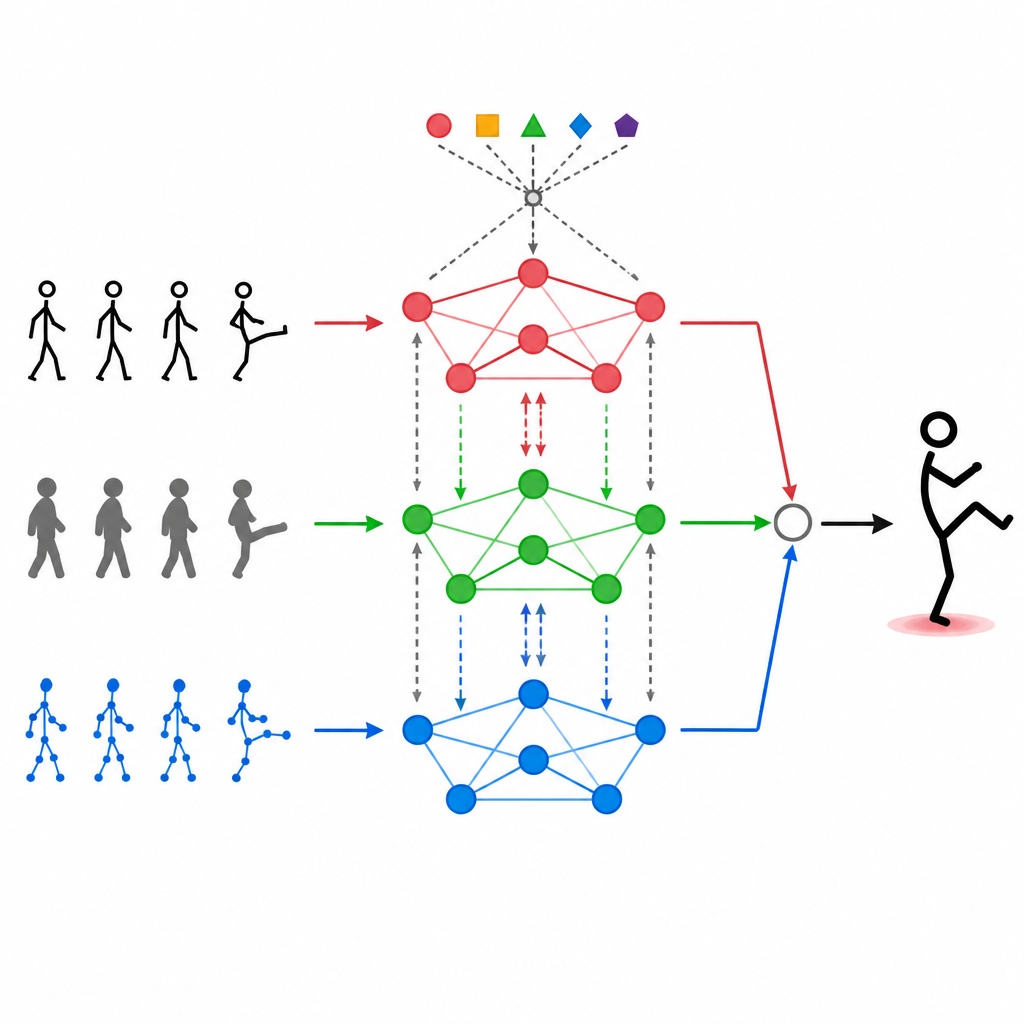
Letting Modalities Talk to Each Other
Simply stacking different data streams on top of one another is not enough. MAGNet uses a self-attention mechanism that allows each type of input to "look" at the others and decide how much they should influence it. In practice, this means the system can learn patterns such as "when the hand joints move in this way and the depth image shows this shape, it is likely a wave" and then boost those combined signals. This attention process happens repeatedly, refining how the three modalities are blended so that the final features are better aligned with real human actions and less affected by noise or missing frames.
Filling in the Gaps When Data Is Missing
Real-world sensors fail, get blocked, or go out of sync. To cope with this, the authors add a generative module based on a method called VQ-VAE that learns typical ways bodies move. When one type of data is missing or badly corrupted, this component can synthesize a plausible version of the missing information, such as an estimated skeleton or local pose features, that is consistent with what the remaining sensors see. Importantly, the model is trained so that these generated poses remain anatomically sensible and stay close to the likely action category, reducing the risk of wild guesses that could mislead the system.
What the Experiments Show
The team tested MAGNet on two well known collections of human action videos that include walking, waving, sitting, and many other moves, recorded under varied viewpoints and lighting. MAGNet reached higher accuracy than a range of strong earlier methods, including those that rely only on skeletons or that use more rigid ways to combine inputs. It also handled challenging cases better, such as when one sensor’s data was partially or completely missing, and still ran fast enough to be practical for near real time use. Careful ablation tests confirmed that each part of the design, from the adaptive body graph to the attention mechanism and generative module, contributed to these gains.
Clearer, More Reliable Action Understanding
For a non expert, the key takeaway is that MAGNet helps computers understand human movements more like a careful observer who uses sight, depth, and a mental model of the body together, rather than relying on a single unreliable cue. By flexibly combining multiple sensor views and intelligently filling in gaps, the system keeps its recognition accuracy high even when conditions are far from perfect. This makes it a promising blueprint for action recognition in everyday settings such as smart homes, sports analysis, and assistive robots.
Citation: Dong, H., Zhang, F., Liu, C. et al. MAGNet: enhancing action recognition with multimodal fusion and adaptive graph convolution. Sci Rep 16, 15100 (2026). https://doi.org/10.1038/s41598-026-45601-2
Keywords: human action recognition, multimodal fusion, graph neural network, computer vision, pose estimation