Clear Sky Science · tr
MAGNet: çok modlu birleştirme ve uyarlanabilir grafik konvolüsyon ile eylem tanımayı geliştirme
Bilgisayarlara İnsan Hareketlerini Okutmak
Vücudunuzu izleyen video oyunlarından, insanların etrafında güvenle dolaşan ev robotlarına kadar pek çok teknoloji, insan eylemlerini anlayabilen bilgisayarlara dayanır. Ancak gerçek hayat karmaşıktır: aydınlatma değişir, insanlar mobilyaların arkasından geçer ve bazı sensörler arızalanır. Bu çalışma, bilgisayarların günlük koşullarda insanların ne yaptığını daha doğru ve daha güvenilir şekilde tanımasına yardımcı olan yeni bir sistem olan MAGNet’i tanıtıyor.
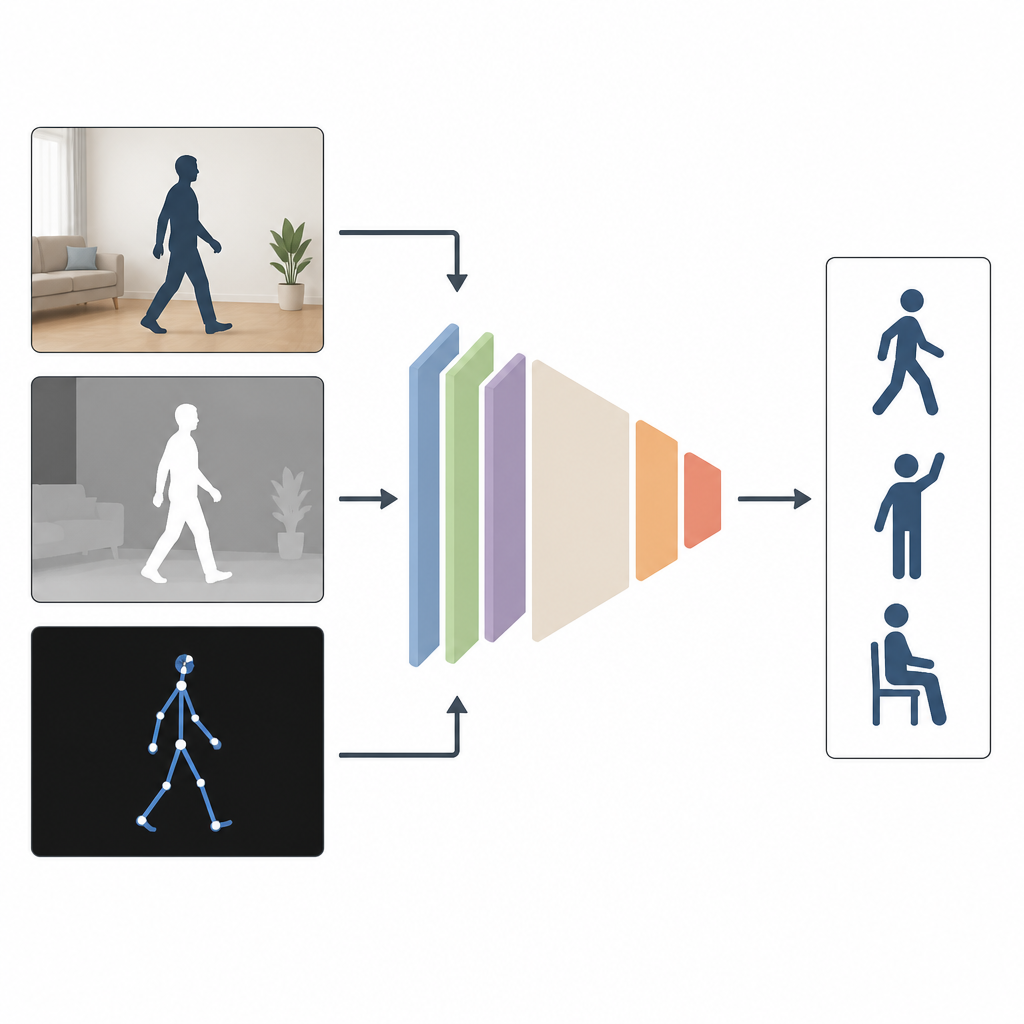
Birçok Açıdan Görmenin Neden Yardımcı Olduğu
Mevcut sistemlerin çoğu, yalnızca renkli video gibi tek bir girdi türünü kullanarak insanları izliyor. Bu, laboratuvarda iyi çalışır ama odalar karanlıksa, kameralar yandan konumlandırılmışsa veya vücudun bir kısmı gizlenmişse yetersiz kalır. Yazarlar, birkaç bilgi türünü birleştirmenin daha iyi olduğunu savunuyor. MAGNet, aynı eylemin üç görünümünü harmanlıyor: görünümü veren sıradan bir renkli görüntü, nesnelerin kameraya olan uzaklığını ölçen bir derinlik görüntüsü ve kişinin 3B vücut eklemlerinin çubuk figür betimlemesi. Bu görünümler birlikte, birinin nasıl hareket ettiğine dair daha zengin ve daha eksiksiz bir tablo sunuyor.
Ağın Vücuda Uyarlanmasına İzin Vermek
MAGNet’in merkezinde, omuz, dirsek ve diz gibi bağlı noktalar ağı olarak insan vücudunu ele alan bir yapı bulunuyor. Bu "graf" sistemin hangi eklemlerin birbirini etkilediğini bilmesini sağlıyor. MAGNet bu yapıyı sabit tutmuyor. Bunun yerine bağlantıların gücünü farklı sensörlerin gördüklerine göre ayarlıyor. Bir derinlik kamerası eğilmiş bir dizi net gösterirken renkli görüntü gürültülüyse, sistem o vücut bölgesi için derinlik sinyaline daha fazla güveniyor. Bu uyarlanabilir grafik tasarımı, MAGNet’in bir pozun zaman içindeki değişimini izlemesine ve hangi sensörün her eklemde daha baskın olacağına karar vermesine yardımcı oluyor.
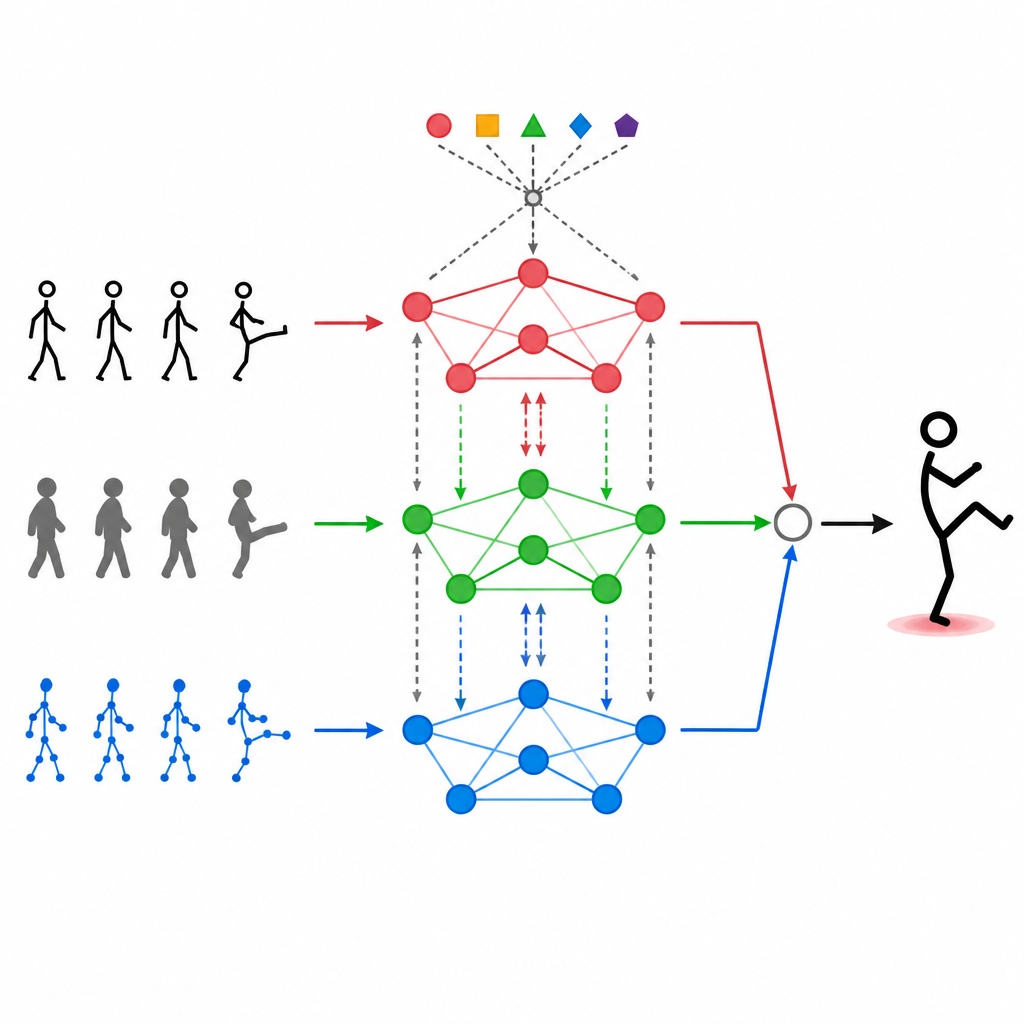
Modların Birbirleriyle Konuşmasına İzin Vermek
Farklı veri akışlarını üst üste koymak tek başına yeterli değil. MAGNet, her giriş türünün diğerlerini "görmesine" ve ne kadar etkileyici olmaları gerektiğine karar vermesine olanak tanıyan bir öz-dikkat mekanizması kullanıyor. Pratikte bu, sistemin "el eklemleri bu şekilde hareket ettiğinde ve derinlik görüntüsü bu şekli gösterdiğinde bunun büyük olasılıkla bir el sallama olduğu" gibi desenleri öğrenebilmesi ve bu birleşik sinyalleri güçlendirebilmesi anlamına geliyor. Bu dikkat süreci tekrar tekrar gerçekleşir; üç modalitenin nasıl harmanlandığını rafine eder ve sonuçta elde edilen özelliklerin gerçek insan eylemleriyle daha iyi hizalanmasını, gürültü veya eksik karelerden daha az etkilenmesini sağlar.
Veri Eksik olduğunda Boşlukları Doldurmak
Gerçek dünyada sensörler arızalanır, engellenir veya senkron dışı kalır. Buna uyum sağlamak için yazarlar, vücutların tipik hareket biçimlerini öğrenen VQ-VAE adlı bir yönteme dayalı üretici bir modül ekliyor. Bir veri türü eksik veya ciddi şekilde bozulmuşsa, bu bileşen eksik bilginin (örneğin tahmini bir iskelet veya yerel poz özellikleri) kalan sensörlerin gördükleriyle tutarlı makul bir versiyonunu sentezleyebiliyor. Önemli olarak, model bu üretilen pozların anatomik olarak mantıklı kalması ve olası eylem kategorisine yakın durması için eğitiliyor; böylece sistemi yanıltabilecek rastgele tahminlerin riski azaltılıyor.
Deneyler Ne Gösteriyor
Ekip, MAGNet’i farklı bakış açıları ve aydınlatmalarda kaydedilmiş yürüme, el sallama, oturma ve birçok diğer hareketleri içeren iki iyi bilinen insan eylem video koleksiyonunda test etti. MAGNet, yalnızca iskeletlere dayanan veya girdileri daha katı yollarla birleştiren güçlü önceki yöntemlere göre daha yüksek doğruluk elde etti. Ayrıca bir sensörün verilerinin kısmen veya tamamen eksik olduğu zor durumları daha iyi ele aldı ve neredeyse gerçek zamanlı kullanım için yeterince hızlı çalıştı. Ayrıntılı ablation (bileşen ayırma) testleri, uyarlanabilir vücut grafiğinden dikkat mekanizmasına ve üretici modüle kadar tasarımın her bir parçasının bu kazanımlara katkıda bulunduğunu doğruladı.
Daha Net, Daha Güvenilir Eylem Anlayışı
Uzman olmayan bir okuyucu için alınacak ana ders şudur: MAGNet, bilgisayarların insan hareketlerini tek, güvenilmez bir ipucuna dayanmak yerine görüş, derinlik ve vücudun zihinsel modeli gibi kaynakları birlikte kullanan dikkatli bir gözlemci gibi anlamasına yardımcı olur. Birden çok sensör görünümünü esnekçe birleştirip boşlukları akıllıca doldurarak, sistem koşullar mükemmel olmadığında bile tanıma doğruluğunu yüksek tutar. Bu da onu akıllı evler, spor analizleri ve yardımcı robotlar gibi günlük ortamlarda eylem tanıma için umut verici bir şablon yapar.
Atıf: Dong, H., Zhang, F., Liu, C. et al. MAGNet: enhancing action recognition with multimodal fusion and adaptive graph convolution. Sci Rep 16, 15100 (2026). https://doi.org/10.1038/s41598-026-45601-2
Anahtar kelimeler: insan eylem tanıma, çok modlu birleştirme, graf sinir ağı, bilgisayarlı görme, poze tahmini