Clear Sky Science · pl
MAGNet: poprawa rozpoznawania czynności dzięki multimodalnej fuzji i adaptacyjnej konwolucji grafowej
Uczenie komputerów czytania ludzkich ruchów
Od gier wideo śledzących ruchy ciała po roboty domowe poruszające się bezpiecznie wokół ludzi — wiele technologii opiera się na komputerach rozumiejących ludzkie czynności. Jednak życie bywa nieuporządkowane: zmienia się oświetlenie, ludzie przechodzą za meblami, a niektóre czujniki zawodzą. W tym badaniu przedstawiono MAGNet, nowy system, który pomaga komputerom dokładniej i bardziej niezawodnie rozpoznawać, co robią ludzie, w warunkach codziennych.
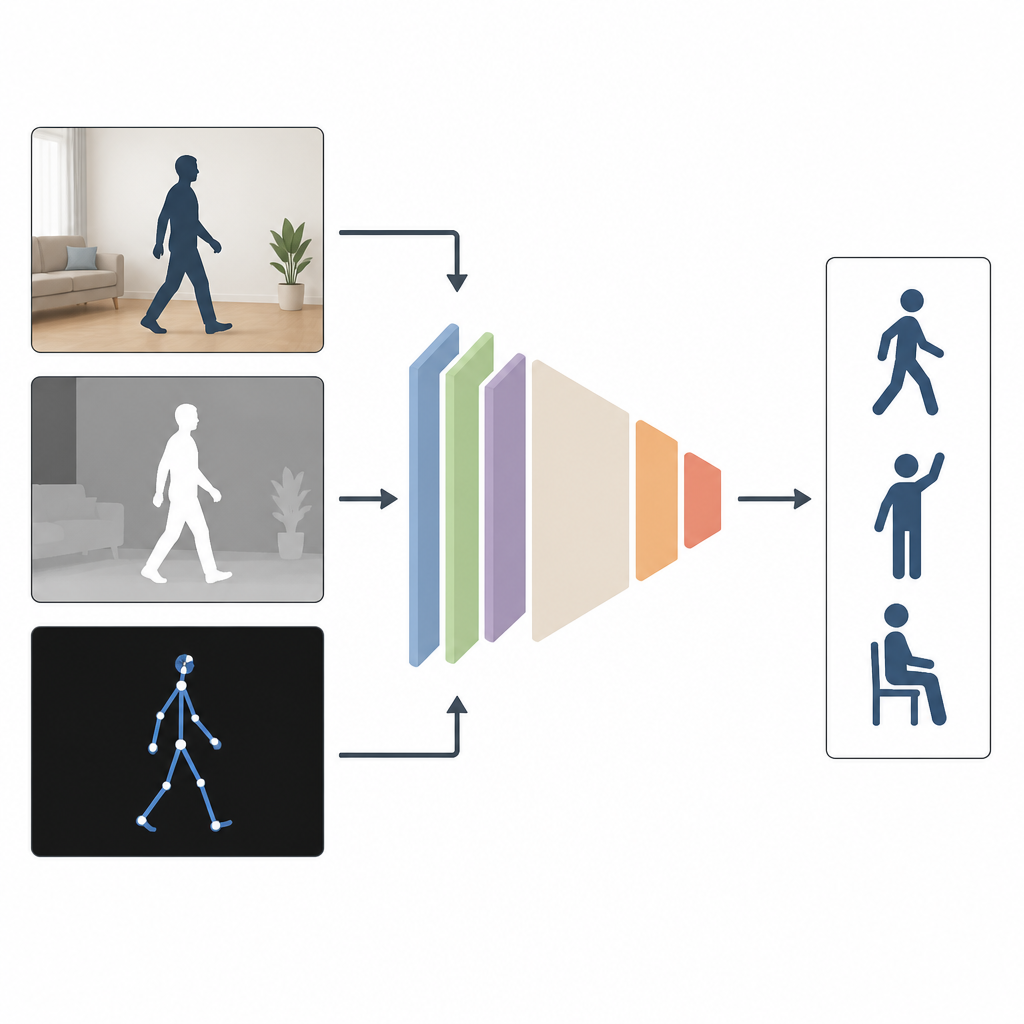
Dlaczego widok z wielu kątów pomaga
Większość istniejących systemów obserwuje ludzi wykorzystując tylko jeden rodzaj danych, na przykład zwykły kolorowy obraz. To działa dobrze w laboratorium, ale gorzej, gdy pokoje są przyciemione, kamery ustawione są z boku lub część ciała jest zasłonięta. Autorzy argumentują, że łączenie kilku rodzajów informacji daje lepsze rezultaty. MAGNet łączy trzy widoki tej samej czynności: zwykły obraz kolorowy pokazujący wygląd, obraz głębokości mierzący odległość obiektów od kamery oraz szkicowy opis stawów ciała w 3D. Razem te widoki dają bogatszy, bardziej kompletny obraz ruchu osoby.
Pozwalanie sieci dostosowywać się do ciała
W sercu MAGNet leży struktura traktująca ciało ludzkie jak sieć połączonych punktów, takich jak ramiona, łokcie czy kolana. Ten „graf” informuje system, które stawy na siebie wpływają. MAGNet nie utrzymuje tej struktury stałą. Zamiast tego dostosowuje siłę połączeń w oparciu o to, co widzą różne czujniki. Jeśli kamera głębokości wyraźnie pokazuje zgięte kolano, podczas gdy obraz kolorowy jest zaszumiony, system cichcem bardziej ufa sygnałowi z głębokości dla tej części ciała. Taka adaptacyjna konstrukcja grafu pomaga MAGNet śledzić zmiany pozy w czasie i decydować, który czujnik powinien mieć większy wpływ na dany staw.
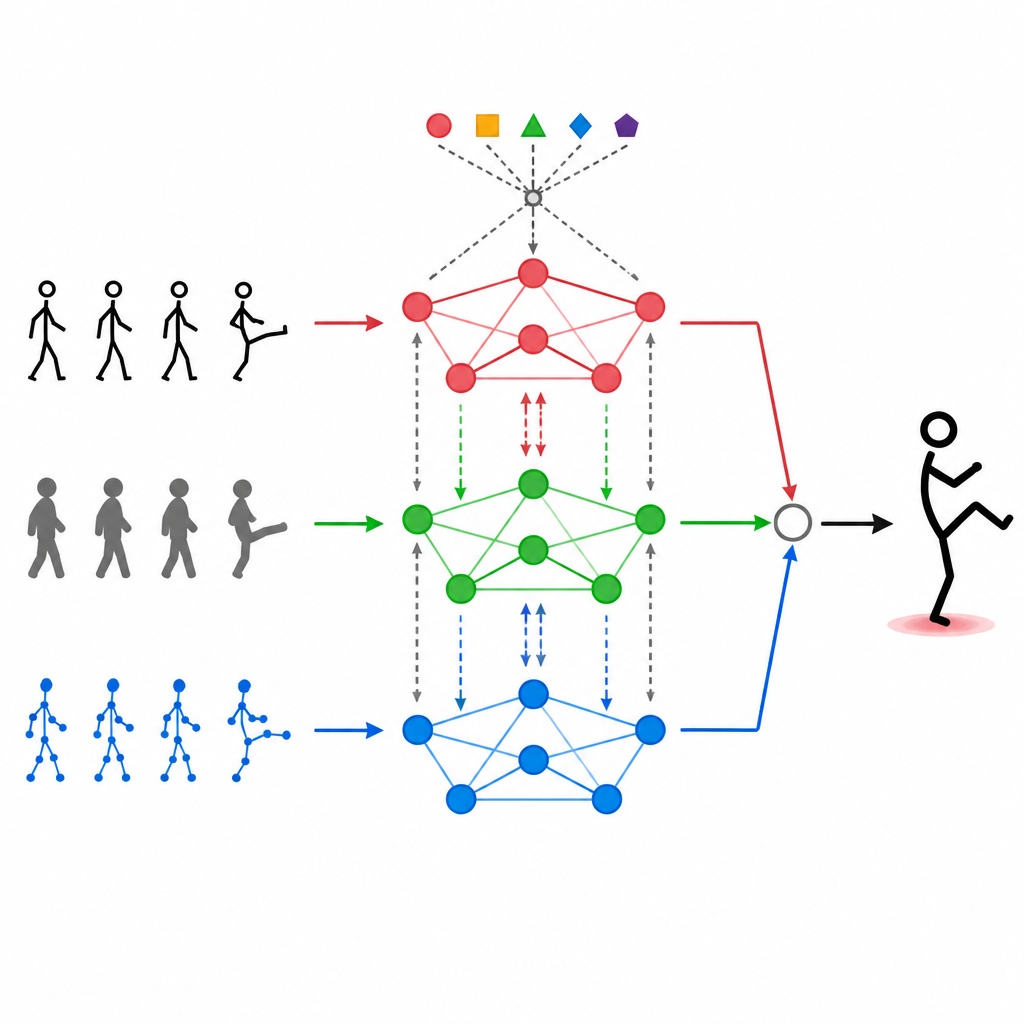
Pozwalanie modalnościom rozmawiać ze sobą
Proste nałożenie różnych strumieni danych na siebie nie wystarcza. MAGNet wykorzystuje mechanizm samo-uwagi, który pozwala każdemu rodzajowi wejścia „spojrzeć” na pozostałe i zdecydować, jak bardzo powinny na nie wpływać. W praktyce oznacza to, że system może nauczyć się wzorców takich jak „gdy stawy dłoni poruszają się w ten sposób, a obraz głębokości ma ten kształt, prawdopodobnie jest to machnięcie” i wzmocnić te połączone sygnały. Proces uwagi zachodzi wielokrotnie, dopracowując sposób, w jaki trzy modalności są łączone, tak aby końcowe cechy lepiej odpowiadały rzeczywistym ludzkim czynnościom i były mniej podatne na szum czy brakujące klatki.
Wypełnianie luk, gdy brakuje danych
Czujniki w świecie rzeczywistym zawodzą, bywają zasłonięte lub tracą synchronizację. Aby sobie z tym poradzić, autorzy dodali moduł generatywny oparty na metodzie zwanej VQ-VAE, który uczy się typowych sposobów poruszania się ciał. Gdy jeden rodzaj danych jest brakujący lub silnie uszkodzony, ten komponent potrafi wygenerować wiarygodną wersję brakującej informacji, taką jak oszacowany szkielet czy lokalne cechy pozy, spójną z tym, co widzą pozostałe czujniki. Co ważne, model jest szkolony tak, aby wygenerowane pozy pozostawały anatomically poprawne i zgodne z prawdopodobną kategorią czynności, zmniejszając ryzyko niekontrolowanych zgadywań, które mogłyby wprowadzić system w błąd.
Co pokazują eksperymenty
Zespół przetestował MAGNet na dwóch dobrze znanych zbiorach wideo z ludzkimi czynnościami obejmującymi chodzenie, machanie, siedzenie i wiele innych ruchów, nagrywanych z różnych punktów widzenia i przy różnym oświetleniu. MAGNet osiągnął wyższą dokładność niż szereg silnych wcześniejszych metod, w tym tych opierających się wyłącznie na szkielecie czy używających bardziej sztywnych sposobów łączenia wejść. Poradził sobie również lepiej w trudnych przypadkach, na przykład gdy dane jednego czujnika były częściowo lub całkowicie brakujące, i nadal działał wystarczająco szybko, by być praktycznym do zastosowań w niemal czasie rzeczywistym. Dokładne testy ablacym potwierdziły, że każda część projektu — od adaptacyjnego grafu ciała po mechanizm uwagi i moduł generatywny — przyczyniła się do tych popraw.
Bardziej przejrzyste i niezawodne rozumienie czynności
Dla osoby niebędącej ekspertem najważniejsze jest to, że MAGNet pomaga komputerom rozumieć ludzkie ruchy bardziej jak uważny obserwator, który wykorzystuje jednocześnie wzrok, głębokość i model ciała, zamiast polegać na jednym zawodnym wskaźniku. Dzięki elastycznemu łączeniu wielu widoków czujników i inteligentnemu wypełnianiu braków system utrzymuje wysoką dokładność rozpoznawania nawet gdy warunki są dalekie od idealnych. To czyni go obiecującym wzorcem dla rozpoznawania czynności w codziennych zastosowaniach, takich jak inteligentne domy, analiza sportowa czy roboty wspomagające.
Cytowanie: Dong, H., Zhang, F., Liu, C. et al. MAGNet: enhancing action recognition with multimodal fusion and adaptive graph convolution. Sci Rep 16, 15100 (2026). https://doi.org/10.1038/s41598-026-45601-2
Słowa kluczowe: rozpoznawanie czynności człowieka, multimodalna fuzja, sieć neuronowa grafowa, widzenie komputerowe, estymacja pozy