Clear Sky Science · ja
MAGNet: マルチモーダル融合と適応型グラフ畳み込みによる行動認識の向上
コンピュータに人の動きを読み取らせる
ボディトラッキングを用いるビデオゲームから、人の周囲を安全に動く家庭用ロボットまで、多くの技術は人の行動を理解できるコンピュータに依存している。しかし現実は雑然としており、照明が変わったり、人が家具の後ろを通ったり、センサーが故障したりする。今回の研究はMAGNetという新しいシステムを示し、日常的な条件下でもコンピュータが人の行動をより正確かつ信頼性高く認識できるようにする。
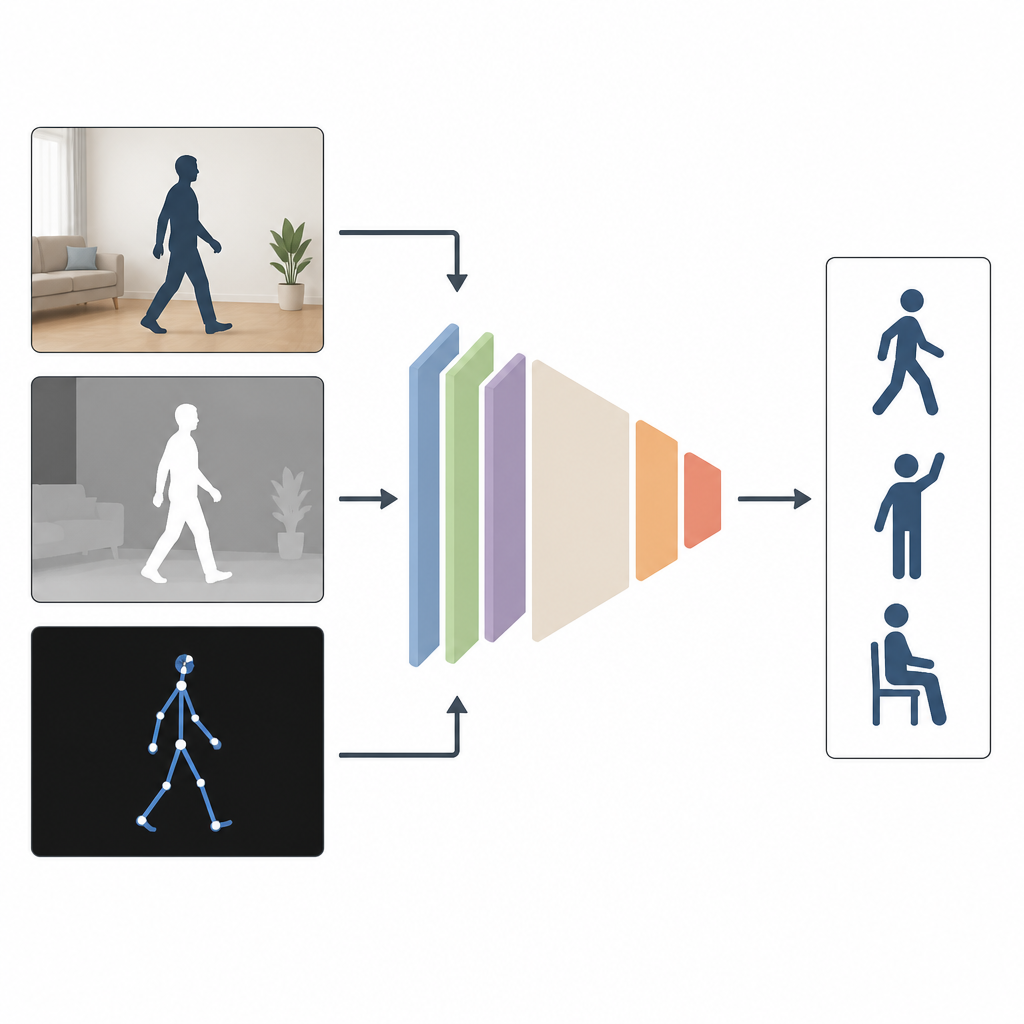
多視点で見ることが助けになる理由
現在の多くのシステムは、通常のカラービデオなど単一の入力に頼っている。研究室環境ではこれで十分でも、部屋が暗い、カメラが横向きに設置されている、身体の一部が隠れるといった現場ではうまくいかない。著者らは複数の種類の情報を組み合わせる方が有利であると主張する。MAGNetは同じ動作を三つの視点で統合する:見た目を示す通常のカラー画像、物体がカメラからどれだけ離れているかを示す深度画像、そして人物の関節を3Dで表したスティックフィギュアである。これらを組み合わせることで、誰かの動きに関するより豊かで完全な描写が得られる。
身体に合わせてネットワークを適応させる
MAGNetの中心には、肩や肘、膝といった接続点のネットワークとして人体を扱う構造がある。この「グラフ」はどの関節が互いに影響を及ぼすかを示す。MAGNetはこの構造を固定しない。代わりに、各センサーの観測に基づいて接続の強さを調整する。たとえば、深度カメラが膝の屈曲をはっきり示している一方でカラー画像がノイズにまみれている場合、システムはその部位について深度信号をより重視する。この適応型グラフ設計により、MAGNetはポーズの時間変化を追跡し、各関節でどのセンサーの情報を優先すべきかを判断できるようになる。
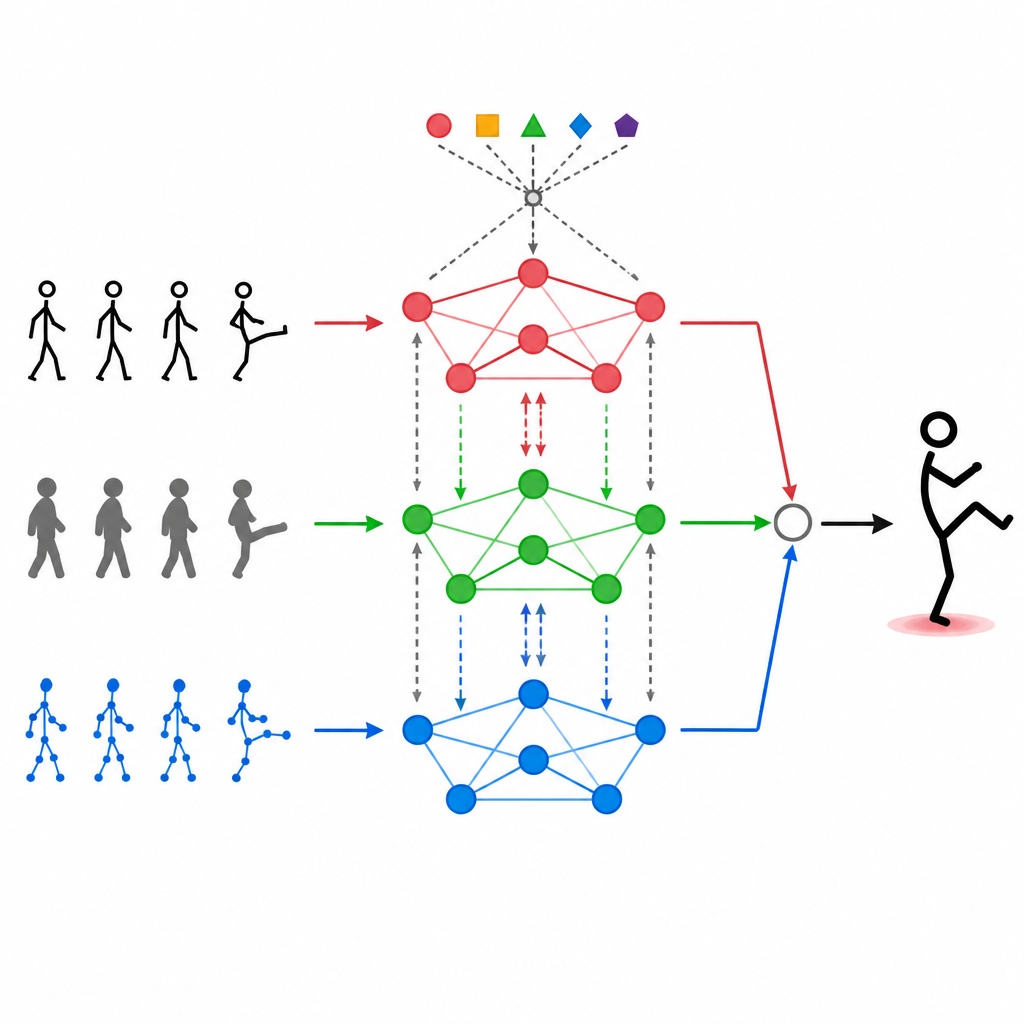
モダリティ同士の対話を可能にする
異なるデータストリームをただ重ねるだけでは不十分だ。MAGNetは自己注意機構を用い、各入力が他の入力を「見て」どの程度影響を受けるべきかを決められるようにする。実際には、例えば「手の関節がこのように動き、深度画像がこの形を示すとき、それは手を振っている可能性が高い」といったパターンを学習し、そうした結合信号を強調できる。この注意プロセスは繰り返し行われ、三種類のモダリティの融合が洗練されていくことで、最終的な特徴表現が実際の人間の動作により整合し、ノイズや欠損フレームの影響を受けにくくなる。
データが欠けたときの穴埋め
現実のセンサーは故障したり遮られたり、同期が外れたりする。これに対処するために、著者らはVQ‑VAEと呼ばれる手法に基づく生成モジュールを追加し、身体の典型的な動き方を学習させる。一つのデータ種類が欠落または大きく破損している場合、このコンポーネントは残りのセンサーの観測と整合する、欠損情報のもっともらしいバージョン(推定されたスケルトンや局所的なポーズ特徴など)を合成できる。重要なのは、生成されたポーズが解剖学的に妥当であり、関連する行動カテゴリに近いままであるようにモデルが訓練されているため、システムを誤導するような荒唐無稽な推定のリスクが減る点である。
実験が示したこと
チームは、歩行、手を振る、座るなど多様な動作を含み、視点や照明が変化する環境で記録された二つのよく知られた人間動作ビデオデータセットでMAGNetを評価した。MAGNetはスケルトンのみを用いる手法や、より硬直的な入力結合法を用いる強力な従来法群よりも高い精度を達成した。また、あるセンサーのデータが部分的または完全に欠落するような難しいケースにも強く、ほぼリアルタイムで実用的な速度で動作した。アブレーション実験により、適応型ボディグラフ、注意機構、生成モジュールといった設計要素のそれぞれがこれらの改善に寄与していることが確認された。
より明瞭で信頼できる行動理解
非専門家向けに要点をまとめると、MAGNetはコンピュータが単一の不安定な手がかりに頼るのではなく、視覚、深度、身体の内部モデルを慎重な観察者のように統合して人の動作を理解する手助けをするということだ。複数のセンサー視点を柔軟に組み合わせ、賢く欠損を補うことで、条件が完璧でない場合でも認識精度を高く保つ。このため、スマートホーム、スポーツ解析、支援ロボットなど日常的な場面での行動認識の有望な設計指針となるだろう。
引用: Dong, H., Zhang, F., Liu, C. et al. MAGNet: enhancing action recognition with multimodal fusion and adaptive graph convolution. Sci Rep 16, 15100 (2026). https://doi.org/10.1038/s41598-026-45601-2
キーワード: 人間行動認識, マルチモーダル融合, グラフニューラルネットワーク, コンピュータビジョン, 姿勢推定