Clear Sky Science · zh
使用多损失序列生成对抗网络的文本到视频生成
把文字变成动态画面
想象一下输入一句简短描述,比如“一个人在公园慢跑”,就能立刻得到一段与之匹配的小视频剪辑。本研究正是解决这一挑战:教会计算机将日常语言转换为短小且真实的视频,既忠实于文本,又在帧与帧之间保持平滑过渡。这类技术可用于教育、娱乐、设计和无障碍工具,但要让结果既可信又在时间上连贯却出奇地困难。
为什么视频比图像更难
从文本生成单张图片已经很难,但现代系统在这方面已相当成熟。视频将难度提升了一个层次:每一帧不仅要符合描述,还要与相邻帧在时间上相一致。如果背景突然变化或人物在帧间变形,运动的幻觉就会被破坏。公开视频数据集增加了额外的挑战,因为它们混合了不同的摄像角度、光照条件和动作风格。因此,早期许多方法生成的场景模糊、运动断裂,或仅与输入文本大致匹配。
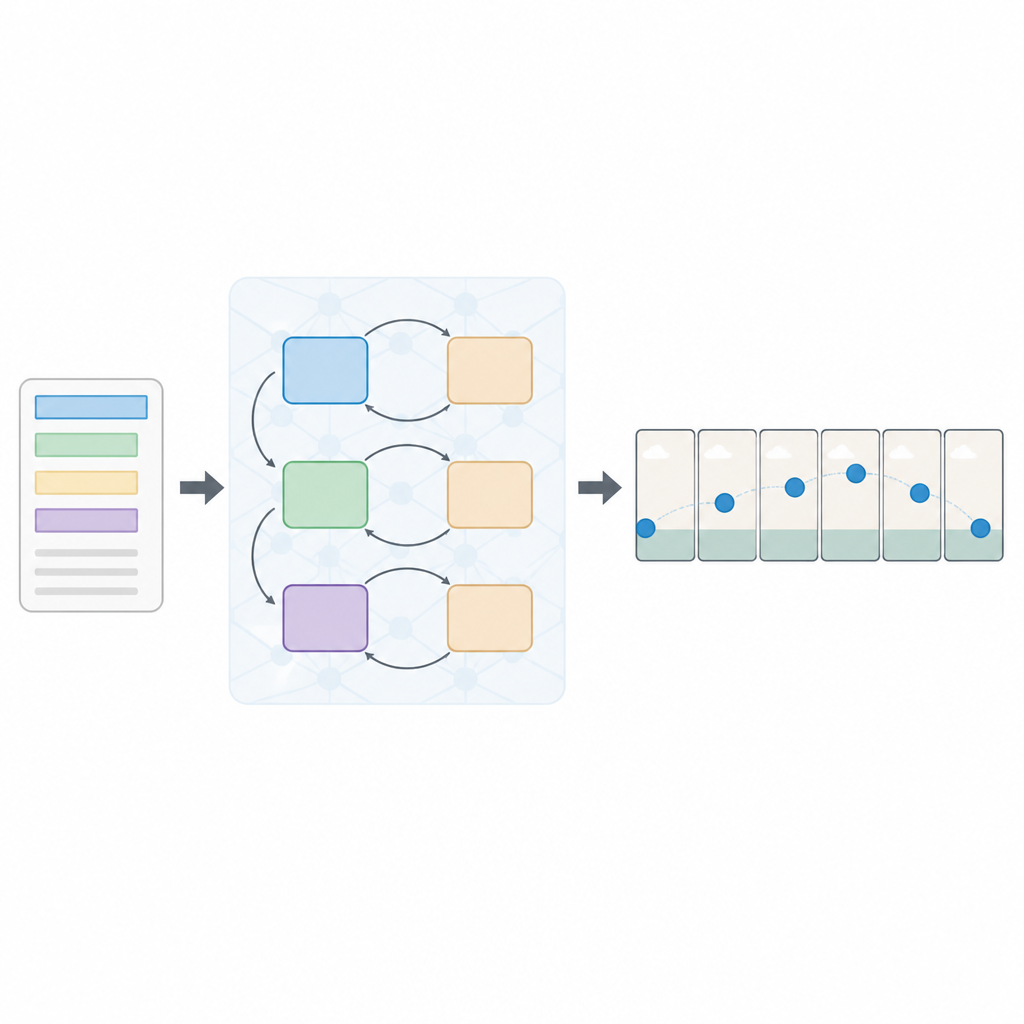
一种分层的“读-见”方法
作者提出了一种名为多损失序列生成对抗网络(简称 Seq-GAN)的新架构。首先,基于 LSTM 的文本编码器逐词读取句子,并将其转换为捕捉语义的紧凑数值“摘要”。并行地,一个改进的变分自编码器从第一帧构建一个“要点”图像,侧重整体背景颜色和布局,而不是细节。这个要点像场景的粗略草图,后来引导最终视频帧的运动和外观。
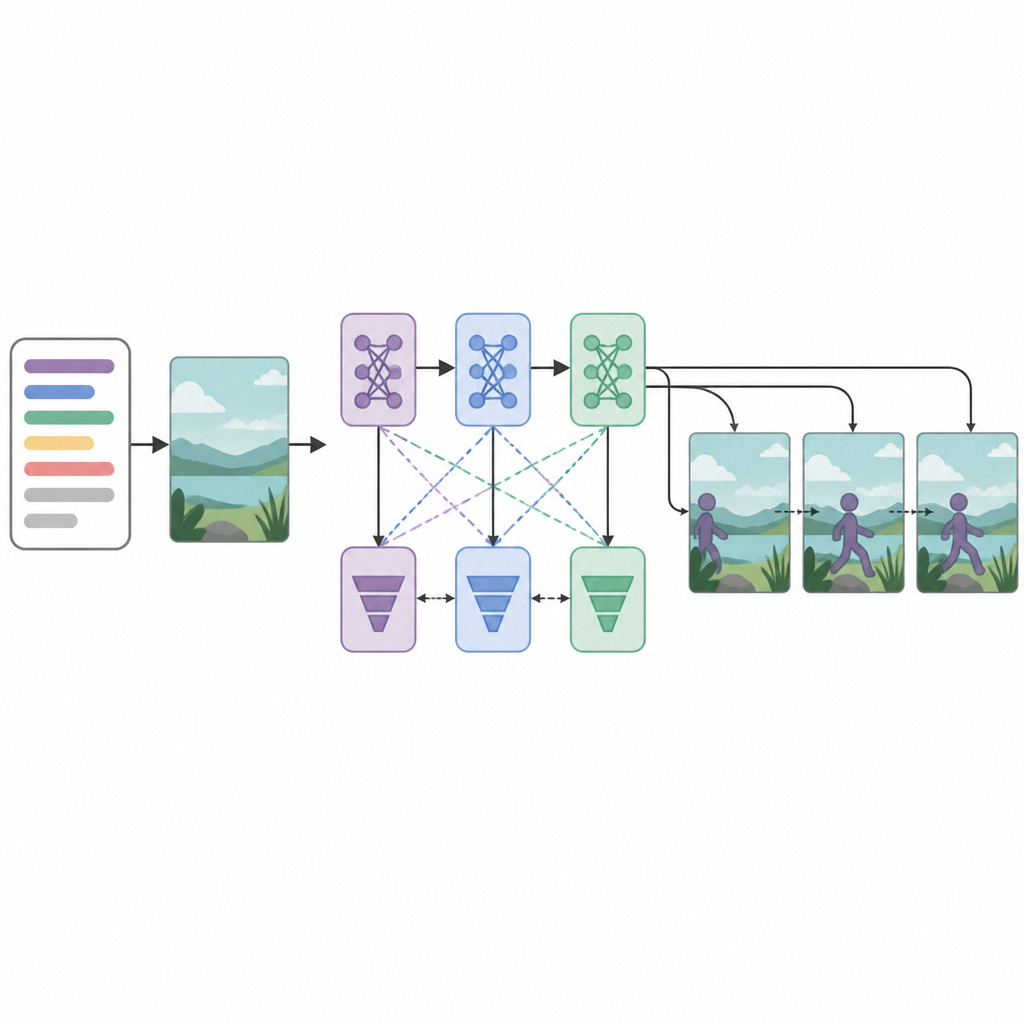
多个判别器以获得更锐利的结果
系统的核心由三个生成器网络和三个按序排列的判别器(或称评论器)组成。每个生成器试图创造看起来自然且与文本匹配的视频帧,而每个判别器则努力区分真实视频与生成视频。不同寻常的是,每对生成器—判别器使用不同的优化策略训练:RMSprop、Adam 或随机梯度下降。这些独立的“损失”促使各阶段专门化:第一阶段构建基本结构,第二阶段提升清晰度与时序,第三阶段关注剪辑是否真正反映所描述的动作。通过将帧生成视为逐步决策过程,模型能更好地在时间上维持平滑运动。
系统表现如何
研究人员在三个数据集上测试了他们的方法:一个显示单个数字弹跳的简单数据集,以及两个大型的人类动作集合(KTH 和 UCF-101),涵盖行走、跑步、拳击和各种运动等活动。他们使用了常用指标来评估:用于帧多样性和清晰度的 Inception Score,衡量生成剪辑与真实剪辑相似程度的 Fréchet Video Distance,以及评估视频内容与文本匹配度的 CLIP 相似性。在这些测试中,新的 Seq-GAN 持续超越早期基于 GAN 的系统,并在保持运动连贯性与内容与文本对齐方面与更近的文本到视频模型竞争力相当。
局限与未来方向
尽管具有优势,该方法在处理长或复杂场景、高分辨率以及涉及多人或多物体的详细文本时仍有困难。随着帧数或视频尺寸的增加,小瑕疵与模糊可能出现,系统也可能遗漏更细微的描述部分。作者建议未来工作可以更直接地将其方法与大型基于扩散的视频模型比较,并探索将对抗训练的速度与扩散方法的高细节性相结合的混合设计。
这对普通用户意味着什么
对非专业人士而言,核心信息是这项工作使我们更接近于通过简短的自然语言提示创建短小、逼真视频的工具。通过结合语言理解、粗略的视觉草图和多阶段的质量控制,所提出的 Seq-GAN 框架表明有可能生成不仅看起来真实且与我们的需求保持一致的视频,这为未来更直观的视觉故事创建与编辑方式指明了方向。
引用: Ullah, A., Xing, Z., Tasir, M.A.M. et al. Text-to-video generation with multi-loss sequential generative adversarial network. Sci Rep 16, 14966 (2026). https://doi.org/10.1038/s41598-026-45313-7
关键词: 文本到视频, 生成对抗网络, 视频生成, 深度学习, 时间一致性