Clear Sky Science · nl
Tekst-naar-video generatie met een meerverlies sequentieel generatief adversarieel netwerk
Woorden omzetten in bewegende beelden
Stel je voor dat je een korte beschrijving intypt zoals “een persoon joggend in een park” en meteen een kleine videoclip ontvangt die daarbij past. Deze studie pakt precies die uitdaging aan: computers leren om alledaagse taal om te zetten in korte, realistische video’s die trouw blijven aan de tekst en er vloeiend uitzien van frame tot frame. Zo’n technologie kan nieuwe tools aandrijven voor onderwijs, entertainment, ontwerp en toegankelijkheid, maar het is verrassend moeilijk om de resultaten zowel geloofwaardig als consistent in de tijd te laten lijken.
Waarom video moeilijker is dan afbeeldingen
Het genereren van een enkel plaatje uit tekst is al lastig, maar moderne systemen doen dat redelijk goed. Video legt de lat hoger: elk frame moet niet alleen bij de beschrijving passen, maar ook bij de naburige frames in de tijd. Als de achtergrond plotseling verandert of de vorm van een persoon tussen frames vervormt, wordt de illusie van beweging verbroken. Publieke videodatasets voegen een extra moeilijkheid toe omdat ze verschillende camerahoeken, lichtomstandigheden en actiestijlen mengen. Hierdoor produceerden veel eerdere methodes vage scènes, gebroken bewegingen of video’s die slechts losjes bij de inputtekst aansloten.
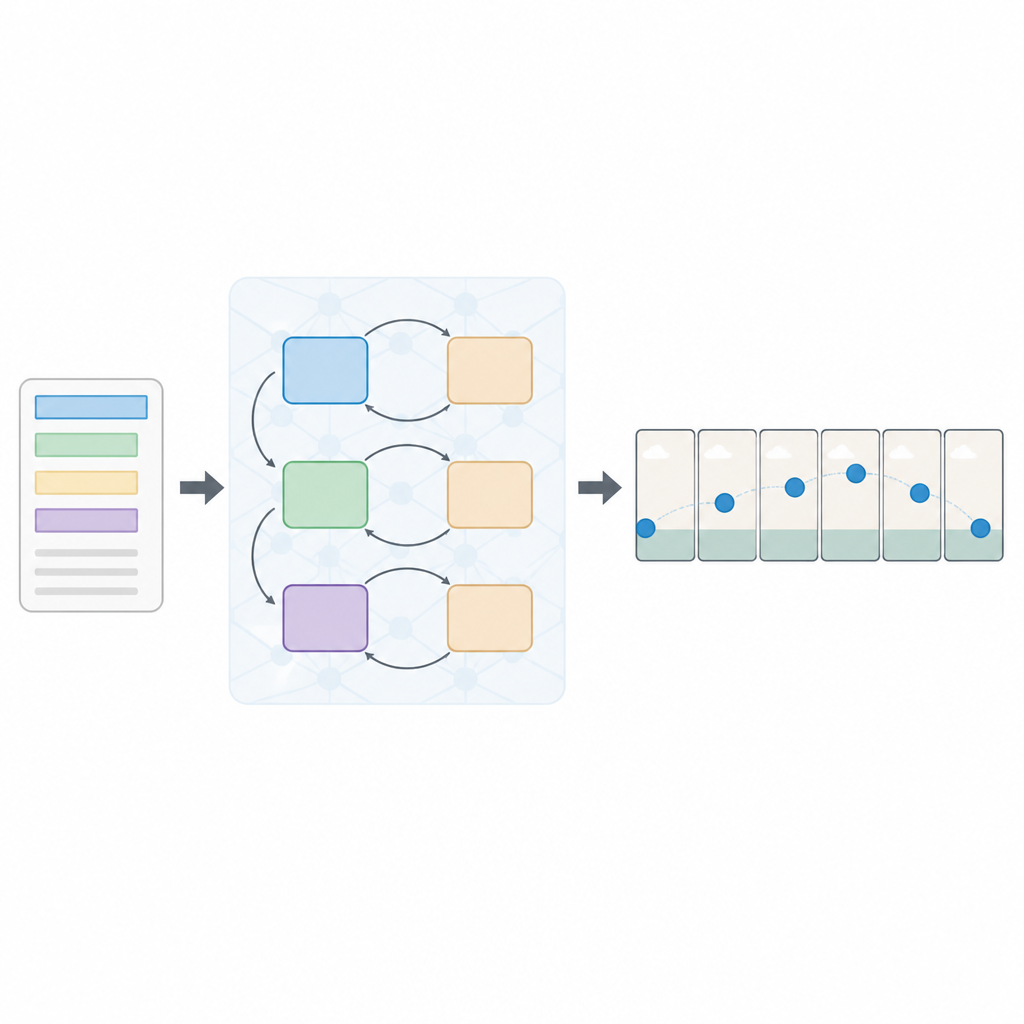
Een gelaagde aanpak om te lezen en te zien
De auteurs stellen een nieuwe opzet voor, een multi-loss Sequential Generative Adversarial Network, of kortweg Seq-GAN. Eerst leest een LSTM-gebaseerde tekstencoder de zin woord voor woord en zet die om in een compacte numerieke “samenvatting” die de betekenis vastlegt. Parallel bouwt een aangepaste variational autoencoder een “gist”-afbeelding uit het eerste frame, waarbij de focus ligt op algemene achtergrondkleur en indeling in plaats van op fijne details. Deze gist fungeert als een ruwe schets van de scène, die later de beweging en het uiterlijk van de uiteindelijke videoframes stuurt.
Meerdere critici voor scherpere resultaten
In het hart van het systeem zitten drie generator-netwerken en drie discriminator- of critic-netwerken die in een sequentie zijn gerangschikt. Elke generator probeert videoframes te maken die realistisch lijken en bij de tekst passen, terwijl elke discriminator probeert echte video’s te onderscheiden van de gegenereerde. Opmerkelijk is dat elk generator–discriminatorpaar met een andere optimalisatiestrategie wordt getraind: RMSprop, Adam of stochastische gradientdescent. Deze afzonderlijke “verliezen” moedigen elke fase aan zich te specialiseren: de eerste bouwt de basisstructuur, de tweede verbetert helderheid en timing, en de derde richt zich erop of de clip werkelijk de beschreven handeling weerspiegelt. Door het creëren van frames als een stapsgewijs besluitvormingsproces te behandelen, kan het model beweging over de tijd beter behouden.
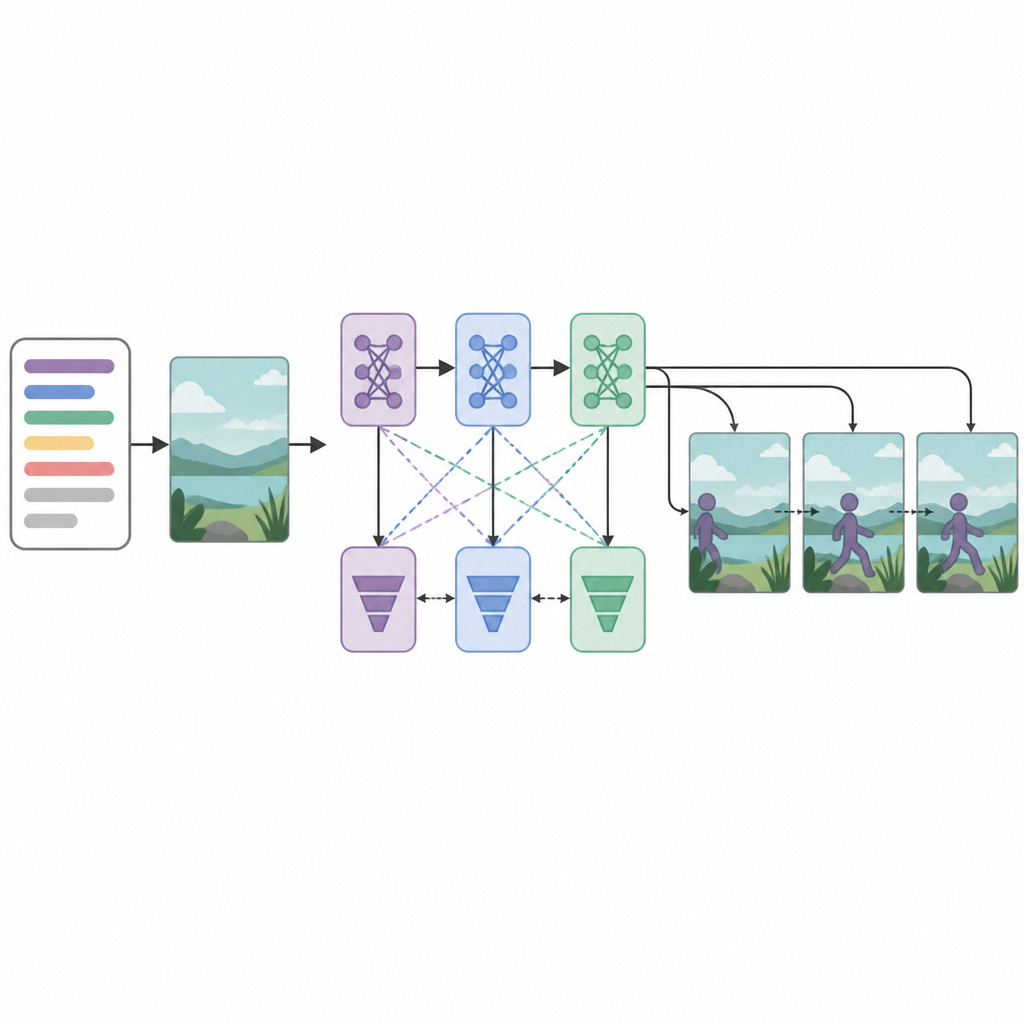
Hoe goed het systeem presteert
De onderzoekers testten hun methode op drie datasets: een eenvoudige die enkele cijfers laat rondstuiteren, en twee grote verzamelingen van menselijke acties (KTH en UCF-101) met activiteiten zoals lopen, rennen, boksen en verschillende sporten. Ze gebruikten bekende maatstaven om succes te beoordelen: de Inception Score voor variatie en helderheid van frames, Fréchet Video Distance voor hoe dicht de gegenereerde clips bij echte clips liggen, en CLIP-similariteit voor hoe goed de videocontent bij de tekst past. Over deze tests heen versloeg de nieuwe Seq-GAN consequent eerdere GAN-gebaseerde systemen en was hij concurrerend met recentere tekst-naar-video modellen, vooral in het behouden van coherente beweging en het in lijn houden van de inhoud met de geschreven beschrijving.
Beperkingen en wat volgt
Ondanks zijn sterke punten worstelt de methode nog steeds met lange of complexe scènes, hoge resoluties en zeer gedetailleerde teksten die meerdere personen of objecten beschrijven. Naarmate het aantal frames of de grootte van de video toeneemt, kunnen kleine foutjes en onscherpte optreden, en kan het systeem subtielere onderdelen van de beschrijving missen. De auteurs stellen toekomstig werk voor dat hun aanpak directer vergelijkt met grote diffusion-gebaseerde videomodellen en hybride ontwerpen onderzoekt die de snelheid van adversariële training combineren met de hoge details van diffusion-methoden.
Wat dit betekent voor dagelijkse gebruikers
Voor niet-experts is de kernboodschap dat dit werk ons dichterbij tools brengt waarbij korte, alledaagse prompts het maken van korte, geloofwaardige videoclips kunnen aansturen. Door taalbegrip, een ruwe visuele schets en meerdere lagen van kwaliteitscontrole te combineren, laat het voorgestelde Seq-GAN-kader zien dat het mogelijk is video’s te genereren die niet alleen realistisch ogen maar ook overeenstemmen met wat we hebben gevraagd, wat wijst op meer intuïtieve manieren om visuele verhalen te maken en te bewerken in de toekomst.
Bronvermelding: Ullah, A., Xing, Z., Tasir, M.A.M. et al. Text-to-video generation with multi-loss sequential generative adversarial network. Sci Rep 16, 14966 (2026). https://doi.org/10.1038/s41598-026-45313-7
Trefwoorden: tekst-naar-video, generatief adversarieel netwerk, video generatie, deep learning, tijdelijke coherentie