Clear Sky Science · en
Text-to-video generation with multi-loss sequential generative adversarial network
Turning words into moving pictures
Imagine typing a short description like “a person jogging in a park” and instantly getting a small video clip that matches it. This study tackles exactly that challenge: teaching computers to transform everyday language into short, realistic videos that stay faithful to the text and look smooth from frame to frame. Such technology could power new tools for education, entertainment, design, and accessibility, but it is surprisingly hard to make the results look both believable and consistent over time.
Why video is harder than images
Generating a single picture from text is already difficult, yet modern systems handle it fairly well. Video raises the bar: every frame must not only match the description but also match its neighbors in time. If the background changes suddenly or a person’s shape warps between frames, the illusion of motion breaks. Public video datasets add another layer of difficulty because they mix different camera angles, lighting conditions, and action styles. As a result, many earlier methods produced blurry scenes, broken motion, or videos that only loosely matched the input text.
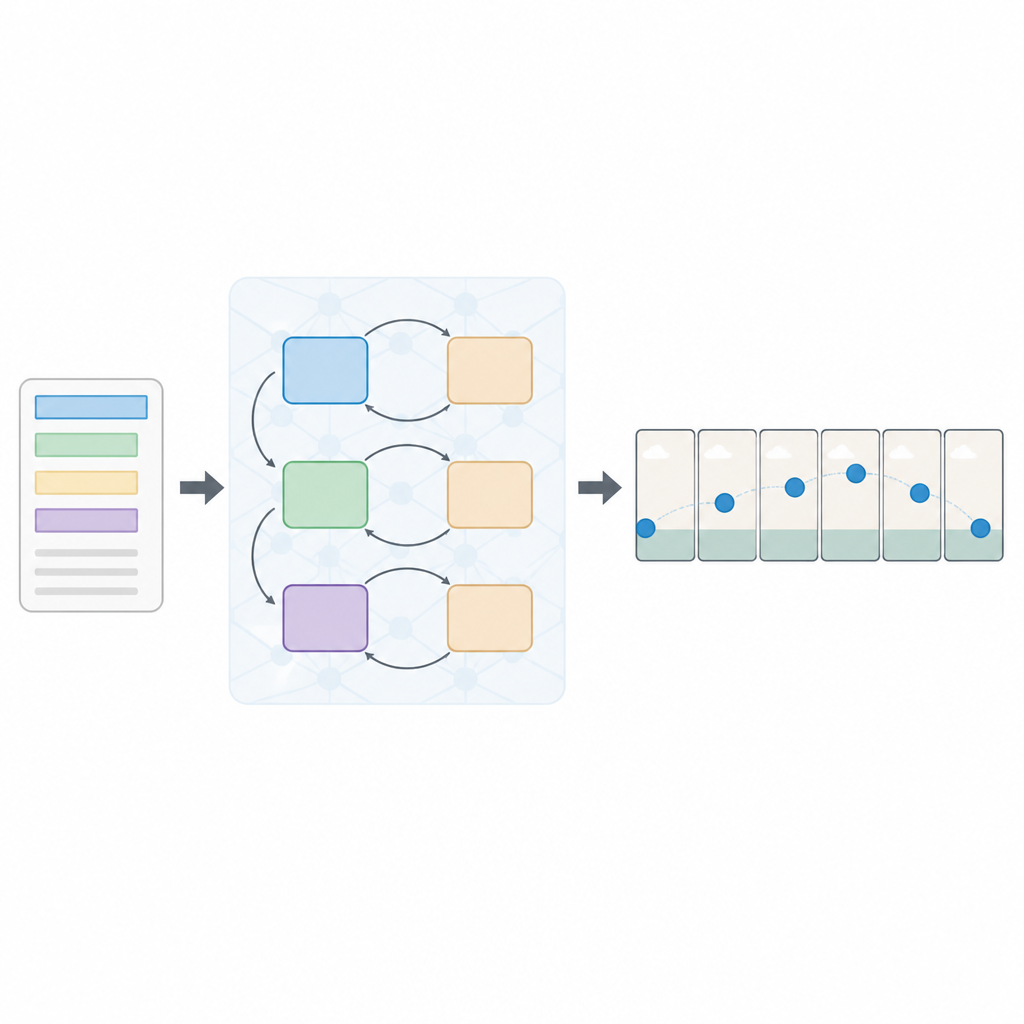
A layered approach to reading and seeing
The authors propose a new setup called a multi-loss Sequential Generative Adversarial Network, or Seq-GAN for short. First, an LSTM-based text encoder reads the sentence word by word and converts it into a compact numerical “summary” that captures the meaning. In parallel, a modified variational autoencoder builds a “gist” image from the first frame, focusing on overall background color and layout rather than fine details. This gist acts like a rough sketch of the scene, which later guides the motion and appearance of the final video frames.
Multiple critics for sharper results
At the heart of the system sit three generator networks and three discriminator, or critic, networks arranged in sequence. Each generator attempts to create video frames that look realistic and match the text, while each discriminator tries to tell real videos apart from the generated ones. Unusually, every generator–discriminator pair is trained with a different optimization strategy: RMSprop, Adam, or stochastic gradient descent. These separate “losses” encourage each stage to specialize: the first builds basic structure, the second improves clarity and timing, and the third focuses on whether the clip truly reflects the described action. By treating frame creation as a step-by-step decision process, the model can better maintain smooth motion across time.
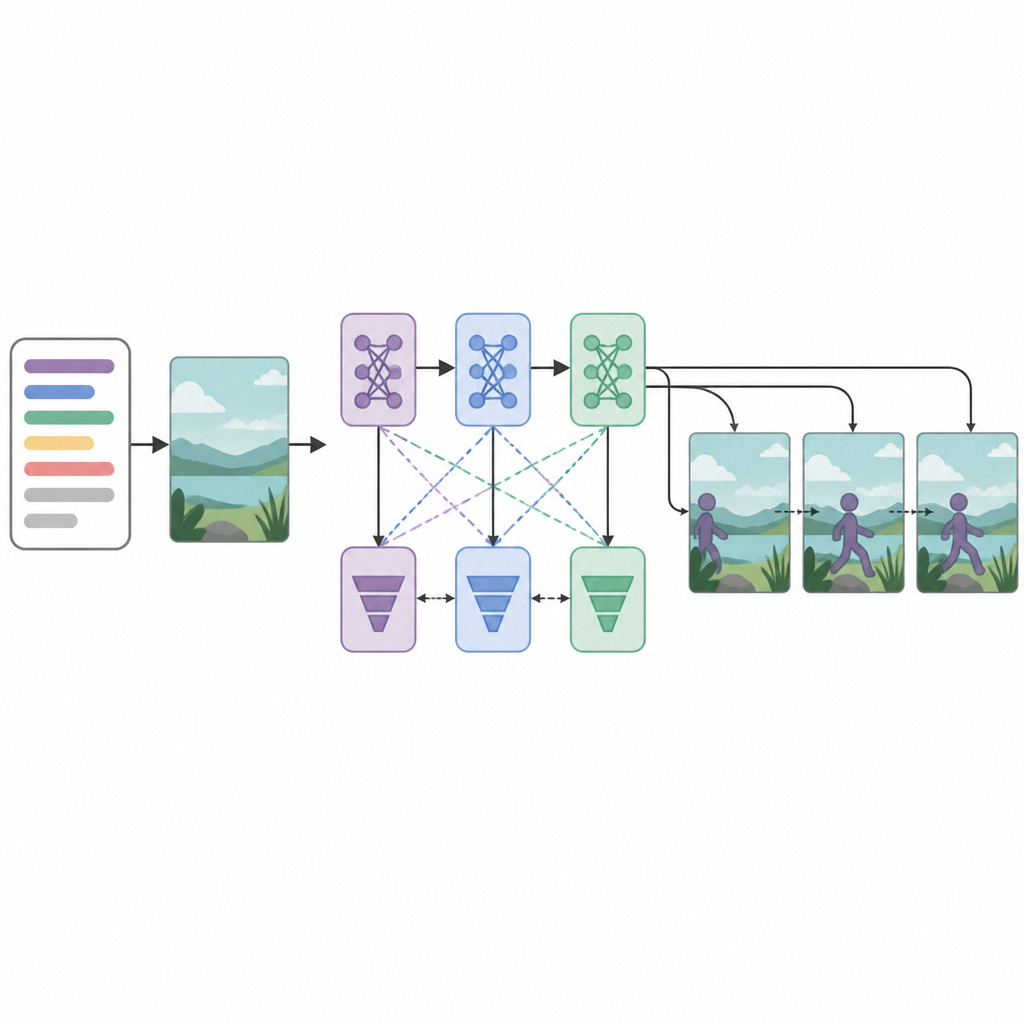
How well the system performs
The researchers tested their method on three datasets: a simple one showing single digits bouncing around, and two large collections of human actions (KTH and UCF-101) covering activities like walking, running, boxing, and various sports. They used well-known measures to judge success: the Inception Score for variety and clarity of frames, Fréchet Video Distance for how closely the generated clips resemble real ones, and CLIP-similarity for how well the video content matches the text. Across these tests, the new Seq-GAN consistently beat earlier GAN-based systems and was competitive with more recent text-to-video models, especially in maintaining coherent motion and keeping the content aligned with the written description.
Limits and what comes next
Despite its strengths, the method still struggles with long or complex scenes, high resolutions, and very detailed text involving multiple people or objects. As the number of frames or the size of the video grows, small glitches and blur can creep in, and the system may miss subtler parts of the description. The authors suggest future work that compares their approach more directly with large diffusion-based video models and explores hybrid designs that blend the speed of adversarial training with the high detail of diffusion methods.
What this means for everyday users
For non-experts, the key message is that this work brings us closer to tools where short, plain-language prompts can drive the creation of short, believable video clips. By combining language understanding, a rough visual sketch, and several stages of quality control, the proposed Seq-GAN framework shows that it is possible to generate videos that not only look realistic but also stay in sync with what we asked for, pointing toward more intuitive ways to create and edit visual stories in the future.
Citation: Ullah, A., Xing, Z., Tasir, M.A.M. et al. Text-to-video generation with multi-loss sequential generative adversarial network. Sci Rep 16, 14966 (2026). https://doi.org/10.1038/s41598-026-45313-7
Keywords: text-to-video, generative adversarial network, video generation, deep learning, temporal coherence