Clear Sky Science · ar
توليد الفيديو من النص باستخدام شبكة تنافسية توليدية تسلسلية متعددة الخسائر
تحويل الكلمات إلى صور متحركة
تخيل كتابة وصف قصير مثل «شخص يركض في حديقة» والحصول فوراً على مقطع فيديو صغير يطابقه. يتناول هذا البحث هذا التحدي بالضبط: تعليم الحواسيب تحويل اللغة اليومية إلى مقاطع فيديو قصيرة وواقعية تظل أمينة للنص وتظهر سلاسة بين الإطارات. يمكن أن تغذي هذه التقنية أدوات جديدة في التعليم والترفيه والتصميم وإتاحة المحتوى، لكن من الصعب جداً جعل النتائج تبدو مقنعة ومتسقة مع مرور الوقت.
لماذا الفيديو أصعب من الصور
توليد صورة واحدة من النص صعب بالفعل، ومع ذلك تتعامل الأنظمة الحديثة معه بشكل جيد إلى حد ما. يرفع الفيديو المستوى: إذ يجب ألا تتطابق كل إطار مع الوصف فحسب، بل يجب أيضاً أن يتطابق مع الإطارات المجاورة زمنياً. إذا تغير الخلفية فجأة أو تشوَّه شكل شخص بين الإطارات، تنهار وهم الحركة. تضيف مجموعات بيانات الفيديو العامة طبقة صعوبة إضافية لأنها تخلط زوايا كاميرا وإضاءة وأنماط حركة مختلفة. نتيجة لذلك، أنتجت العديد من الطرق السابقة مشاهد ضبابية، أو حركة مكسورة، أو فيديوهات تطابق النص بشكل فضفاض فقط.
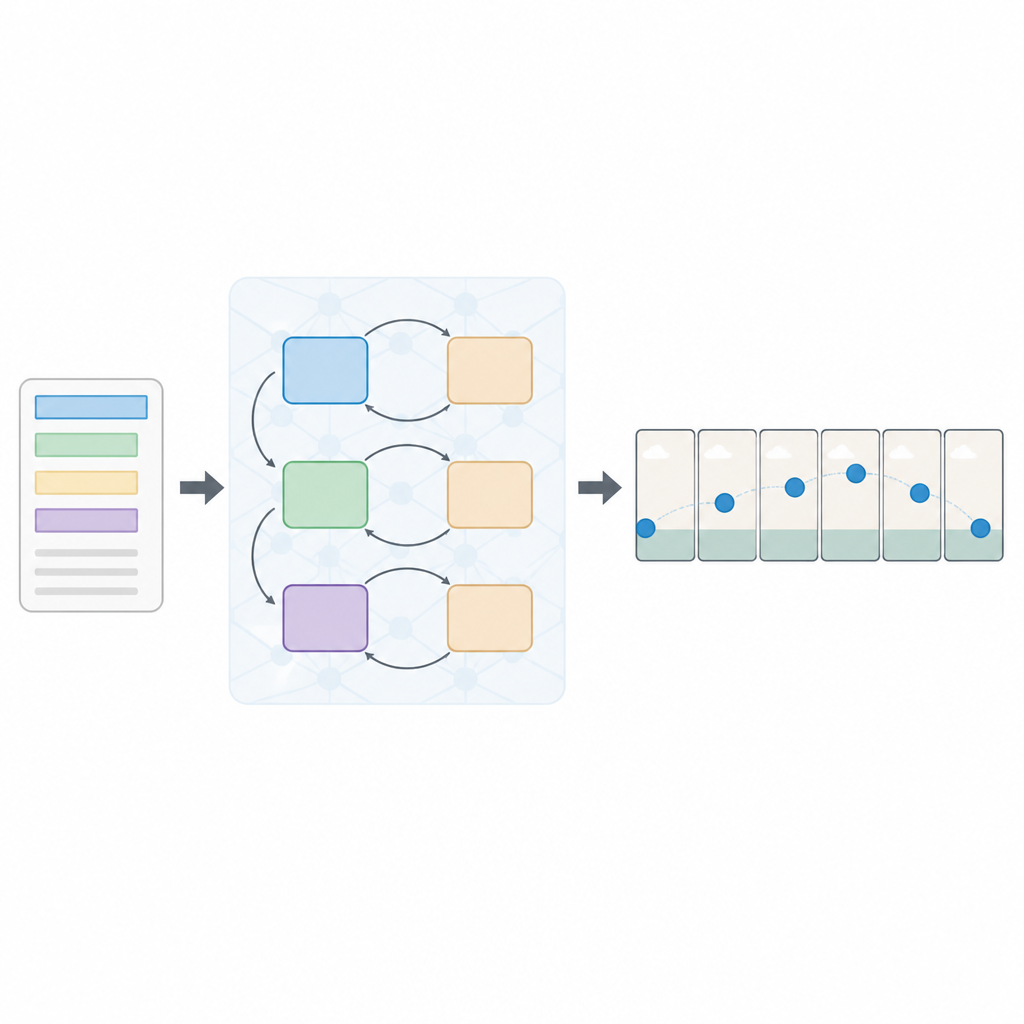
نهج طبقي للقراءة والرؤية
يقترح المؤلفون إعداداً جديداً يسمى شبكة تنافسية توليدية تسلسلية متعددة الخسائر، أو Seq-GAN للاختصار. أولاً، يقوم مشفر نصي مبني على LSTM بقراءة الجملة كلمة بكلمة ويحولها إلى «ملخص» رقمي مضغوط يلتقط المعنى. بالتوازي، يبني مُرمِّز تلقائي متغير معدل صورة «الملخص العام» (gist) من الإطار الأول، مع التركيز على لون الخلفية العام وتخطيط المشهد بدل التفاصيل الدقيقة. يعمل هذا الملخص كرسمة مبدئية للمشهد، توجه لاحقاً الحركة والمظهر في إطارات الفيديو النهائية.
نقاد متعددون لنتائج أكثر حدة
في قلب النظام توجد ثلاث شبكات مولدة وثلاث شبكات مُميِّزة أو نقّاد مرتبة على التتابع. يحاول كل مولد إنشاء إطارات فيديو تبدو واقعية وتطابق النص، بينما تحاول كل مميِّزة التفريق بين الفيديوهات الحقيقية والمولدة. بشكل غير اعتيادي، يُدرّب كل زوج مولد–مميِّزة باستراتيجية تحسين مختلفة: RMSprop أو Adam أو النزول العشوائي للتدرج. تشجّع هذه «الخسائر» المنفصلة كل مرحلة على التخصص: الأولى تبني الهيكل الأساسي، الثانية تحسن الوضوح والتوقيت، والثالثة تركز على ما إذا كان المقطع يعكس بالفعل الفعل الموصوف. من خلال معاملة إنشاء الإطارات كعملية قرار خطوة بخطوة، يمكن للنموذج الحفاظ بشكل أفضل على حركة سلسة عبر الزمن.
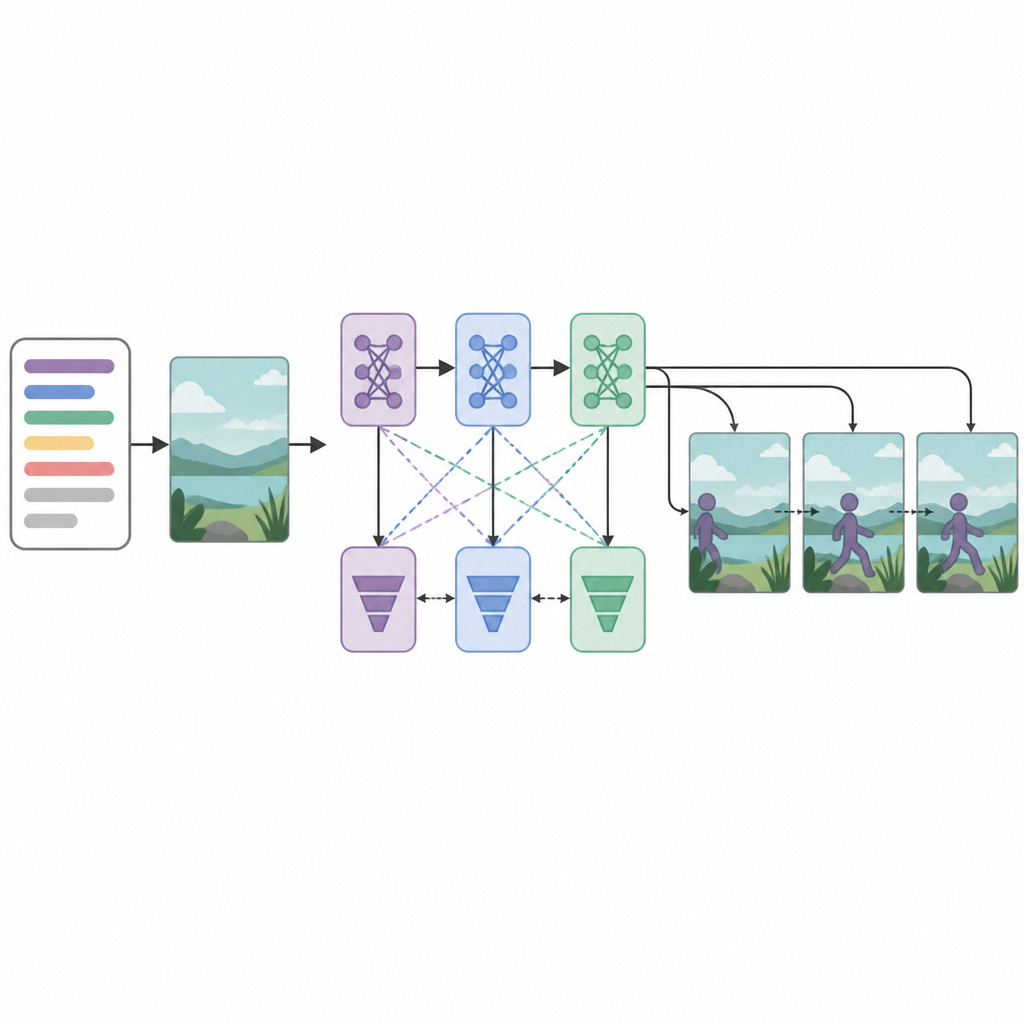
مدى أداء النظام
اختبر الباحثون طريقتهم على ثلاث مجموعات بيانات: مجموعة بسيطة تُظهر أرقاماً فردية تتنطط، ومجموعتين كبيرتين لحركات بشرية (KTH وUCF-101) تغطي أنشطة مثل المشي والجري والملاكمة ومختلف الرياضات. استخدموا مقاييس معروفة للحكم على النجاح: مقياس Inception للتنوع ووضوح الإطارات، ومسافة Fréchet للفيديو لمدى تشابه المقاطع المولدة مع الحقيقية، وتشابه CLIP لمدى توافق محتوى الفيديو مع النص. عبر هذه الاختبارات، تفوّق Seq-GAN الجديد باستمرار على الأنظمة القائمة على GANs وكان تنافسياً مع نماذج نص-إلى-فيديو الأحدث، خاصة في الحفاظ على حركة متماسكة ومطابقة المحتوى للوصف المكتوب.
القيود وما هو آت
على الرغم من نقاط القوة، لا تزال الطريقة تكافح مع المشاهد الطويلة أو المركبة، والدقات العالية، والنصوص المفصلة جداً التي تتضمن عدة أشخاص أو أشياء. مع زيادة عدد الإطارات أو حجم الفيديو، قد تظهر عيوب طفيفة وضبابية، وقد يغفل النظام عن أجزاء أدق من الوصف. يقترح المؤلفون أعمالاً مستقبلية تقارن نهجهم بشكل أكثر مباشرة مع نماذج الفيديو المستندة إلى الانتشار (diffusion) الكبيرة وتستكشف تصميمات هجينة تمزج سرعة التدريب التنافسي مع التفاصيل العالية لطرق الانتشار.
ماذا يعني هذا للمستخدمين العاديين
بالنسبة لغير المتخصصين، الرسالة الأساسية هي أن هذا العمل يقربنا من أدوات يمكن فيها لمطالبات قصيرة وبسيطة أن تولد مقاطع فيديو قصيرة ومقنعة. من خلال الجمع بين فهم اللغة، ورسمة بصرية مبدئية، وعدة مراحل للتحكم في الجودة، يُظهر إطار Seq-GAN المقترح أنه من الممكن توليد فيديوهات لا تبدو واقعية فحسب، بل تبقى أيضاً متوافقة مع ما طلبناه، مما يفتح الطريق لطرق أكثر بديهية لإنشاء وتحرير القصص البصرية في المستقبل.
الاستشهاد: Ullah, A., Xing, Z., Tasir, M.A.M. et al. Text-to-video generation with multi-loss sequential generative adversarial network. Sci Rep 16, 14966 (2026). https://doi.org/10.1038/s41598-026-45313-7
الكلمات المفتاحية: النص-إلى-فيديو, شبكة تنافسية توليدية, توليد الفيديو, التعلم العميق, التماسك الزمني