Clear Sky Science · de
Text-zu-Video-Erzeugung mit einem sequentiellen Generative-Adversarial-Netzwerk mit mehreren Verlusten
Worte in bewegte Bilder verwandeln
Stellen Sie sich vor, Sie tippen eine kurze Beschreibung wie „eine Person joggt in einem Park“ und erhalten sofort einen kleinen Videoclip, der dazu passt. Diese Studie beschäftigt sich genau mit dieser Herausforderung: Computern beizubringen, alltägliche Sprache in kurze, realistische Videos zu verwandeln, die dem Text treu bleiben und von Bild zu Bild flüssig wirken. Solche Technologien könnten neue Werkzeuge für Bildung, Unterhaltung, Design und Barrierefreiheit ermöglichen, doch es ist überraschend schwierig, die Ergebnisse gleichzeitig glaubwürdig und über die Zeit konsistent aussehen zu lassen.
Warum Video schwieriger ist als Bilder
Ein einzelnes Bild aus Text zu erzeugen ist bereits anspruchsvoll, doch moderne Systeme bewältigen das mittlerweile ziemlich gut. Video erhöht die Anforderungen: Jeder Frame muss nicht nur zur Beschreibung passen, sondern auch zu den benachbarten Frames in der Zeit. Wenn sich der Hintergrund plötzlich ändert oder die Körperform einer Person zwischen den Frames verzerrt, bricht die Illusion von Bewegung auseinander. Öffentliche Videodatensätze erschweren die Aufgabe zusätzlich, weil sie unterschiedliche Kamerawinkel, Beleuchtungsbedingungen und Aktionsstile mischen. Infolgedessen erzeugten viele frühere Methoden unscharfe Szenen, gebrochene Bewegungen oder Videos, die nur lose mit dem Eingabetext übereinstimmen.
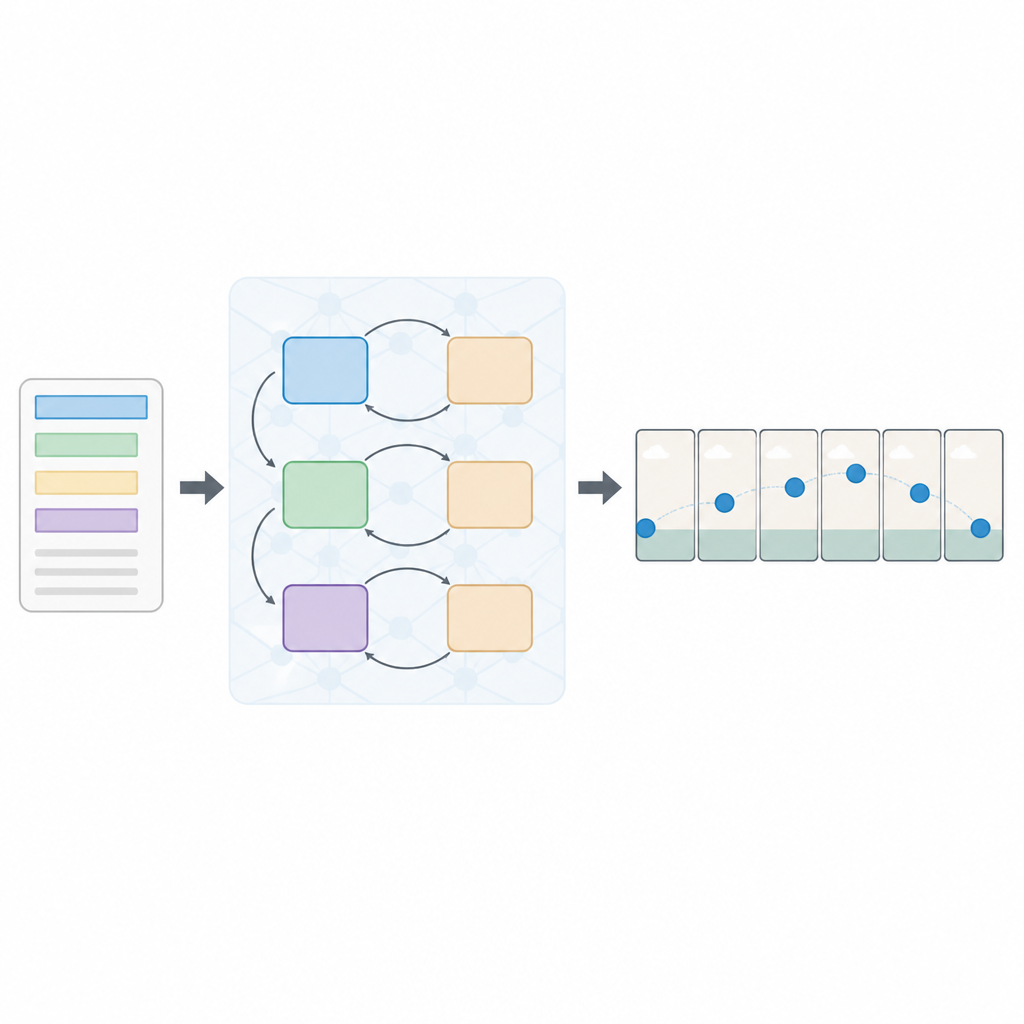
Ein gestufter Ansatz zum Lesen und Sehen
Die Autorinnen und Autoren schlagen eine neue Architektur vor, genannt Multi-Loss Sequential Generative Adversarial Network, kurz Seq-GAN. Zunächst liest ein LSTM-basierter Textencoder den Satz Wort für Wort und wandelt ihn in eine kompakte numerische „Zusammenfassung“ um, die die Bedeutung einfängt. Parallel dazu erzeugt ein modifizierter variationaler Autoencoder ein „Gist“-Bild aus dem ersten Frame, das sich auf die allgemeine Hintergrundfarbe und das Layout statt auf feine Details konzentriert. Dieser Gist fungiert wie eine grobe Skizze der Szene, die später die Bewegung und das Erscheinungsbild der finalen Videoframes steuert.
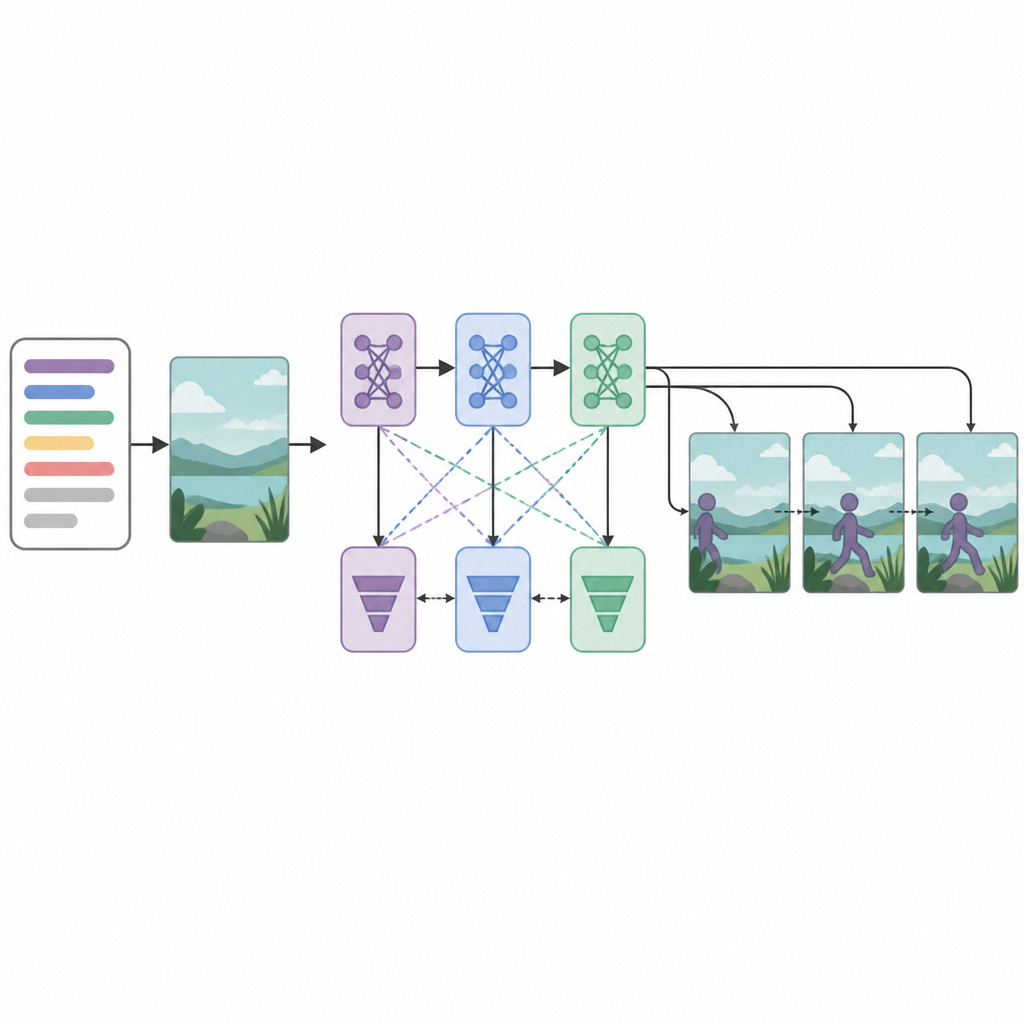
Mehrere Kritiker für schärfere Ergebnisse
Im Kern des Systems sitzen drei Generatornetzwerke und drei Diskriminator- bzw. Kritikernetzwerke, die in Serie angeordnet sind. Jeder Generator versucht, Videoframes zu erzeugen, die realistisch wirken und zum Text passen, während jeder Diskriminator echte Videos von den erzeugten zu unterscheiden versucht. Ungewöhnlich ist, dass jedes Generator–Diskriminator-Paar mit einer anderen Optimierungsstrategie trainiert wird: RMSprop, Adam oder stochastischer Gradientenabstieg. Diese separaten „Verluste“ fördern die Spezialisierung jeder Stufe: Die erste baut die grundlegende Struktur auf, die zweite verbessert Klarheit und Timing, und die dritte konzentriert sich darauf, ob der Clip die beschriebene Aktion tatsächlich widerspiegelt. Indem die Frame-Erzeugung als schrittweiser Entscheidungsprozess behandelt wird, kann das Modell die fließende Bewegung über die Zeit besser beibehalten.
Wie gut das System abschneidet
Die Forschenden testeten ihre Methode an drei Datensätzen: einem einfachen mit einzelnen Ziffern, die umherhüpfen, und zwei großen Sammlungen menschlicher Handlungen (KTH und UCF-101), die Aktivitäten wie Gehen, Laufen, Boxen und verschiedene Sportarten abdecken. Sie nutzten bekannte Metriken zur Bewertung: den Inception Score für Vielfalt und Klarheit der Frames, die Fréchet Video Distance dafür, wie sehr sich die erzeugten Clips echten ähneln, und CLIP-Similarity dafür, wie gut der Videoinhalt zum Text passt. In diesen Tests übertraf das neue Seq-GAN konsequent frühere auf GANs basierende Systeme und war wettbewerbsfähig mit neueren Text-zu-Video-Modellen, insbesondere bei der Aufrechterhaltung kohärenter Bewegungen und der Übereinstimmung des Inhalts mit der Textbeschreibung.
Grenzen und Ausblick
Trotz seiner Stärken hat die Methode weiterhin Schwierigkeiten mit langen oder komplexen Szenen, hohen Auflösungen und sehr detaillierten Texten, die mehrere Personen oder Objekte betreffen. Mit wachsender Frame-Anzahl oder größerer Videoauflösung können kleine Störungen und Unschärfen auftreten, und das System kann feinere Teile der Beschreibung übersehen. Die Autorinnen und Autoren schlagen zukünftige Arbeiten vor, die ihren Ansatz direkter mit großen, diffusionbasierten Videomodellen vergleichen und hybride Designs untersuchen, die die Geschwindigkeit adversarialer Trainingsverfahren mit der hohen Detailtreue von Diffusionsmethoden verbinden.
Was das für Anwenderinnen und Anwender bedeutet
Für Nicht‑Expertinnen und Nicht‑Experten lautet die Kernbotschaft: Diese Arbeit bringt uns der Vision näher, dass kurze, einfache Texteingaben die Erstellung glaubwürdiger Kurzclips steuern können. Durch die Kombination von Sprachverständnis, einer groben visuellen Skizze und mehreren Stufen der Qualitätskontrolle zeigt das vorgeschlagene Seq-GAN-Framework, dass es möglich ist, Videos zu erzeugen, die nicht nur realistisch aussehen, sondern auch mit der gestellten Anfrage in Einklang bleiben — ein Schritt hin zu intuitiveren Wegen, visuelle Geschichten zu erstellen und zu bearbeiten.
Zitation: Ullah, A., Xing, Z., Tasir, M.A.M. et al. Text-to-video generation with multi-loss sequential generative adversarial network. Sci Rep 16, 14966 (2026). https://doi.org/10.1038/s41598-026-45313-7
Schlüsselwörter: text-zu-video, generative adversariale Netzwerke, Videoerzeugung, Deep Learning, zeitliche Kohärenz