Clear Sky Science · pl
Generowanie wideo z tekstu za pomocą wielostratawego sekwencyjnego sieciowego modelu generatywnego typu GAN z wieloma funkcjami straty
Przemiana słów w ruchome obrazy
Wyobraź sobie wpisanie krótkiego opisu, na przykład „osoba biegnąca w parku”, i natychmiastowe otrzymanie krótkiego klipu wideo, który mu odpowiada. Badanie podejmuje się właśnie tego wyzwania: nauczyć komputery przekształcać codzienny język w krótkie, realistyczne filmy, które wiernie odwzorowują tekst i wyglądają płynnie klatka po klatce. Taka technologia może zasilać nowe narzędzia w edukacji, rozrywce, projektowaniu i dostępności, ale zaskakująco trudno jest sprawić, by rezultaty wyglądały jednocześnie wiarygodnie i spójnie w czasie.
Dlaczego wideo jest trudniejsze niż obrazy
Wygenerowanie pojedynczego obrazu z tekstu jest już trudne, jednak nowoczesne systemy radzą sobie z tym całkiem dobrze. Wideo podnosi poprzeczkę: każda klatka musi nie tylko odpowiadać opisowi, ale też pasować do sąsiednich klatek w czasie. Jeśli tło zmienia się nagle lub kształt osoby zniekształca się między klatkami, iluzja ruchu się załamuje. Publiczne zbiory wideo dodają kolejny poziom trudności, ponieważ mieszają różne kąty kamery, warunki oświetleniowe i style akcji. W rezultacie wiele wcześniejszych metod produkowało rozmyte sceny, przerwaną dynamikę lub klipy, które jedynie luźno odpowiadały wejściowemu tekstowi.
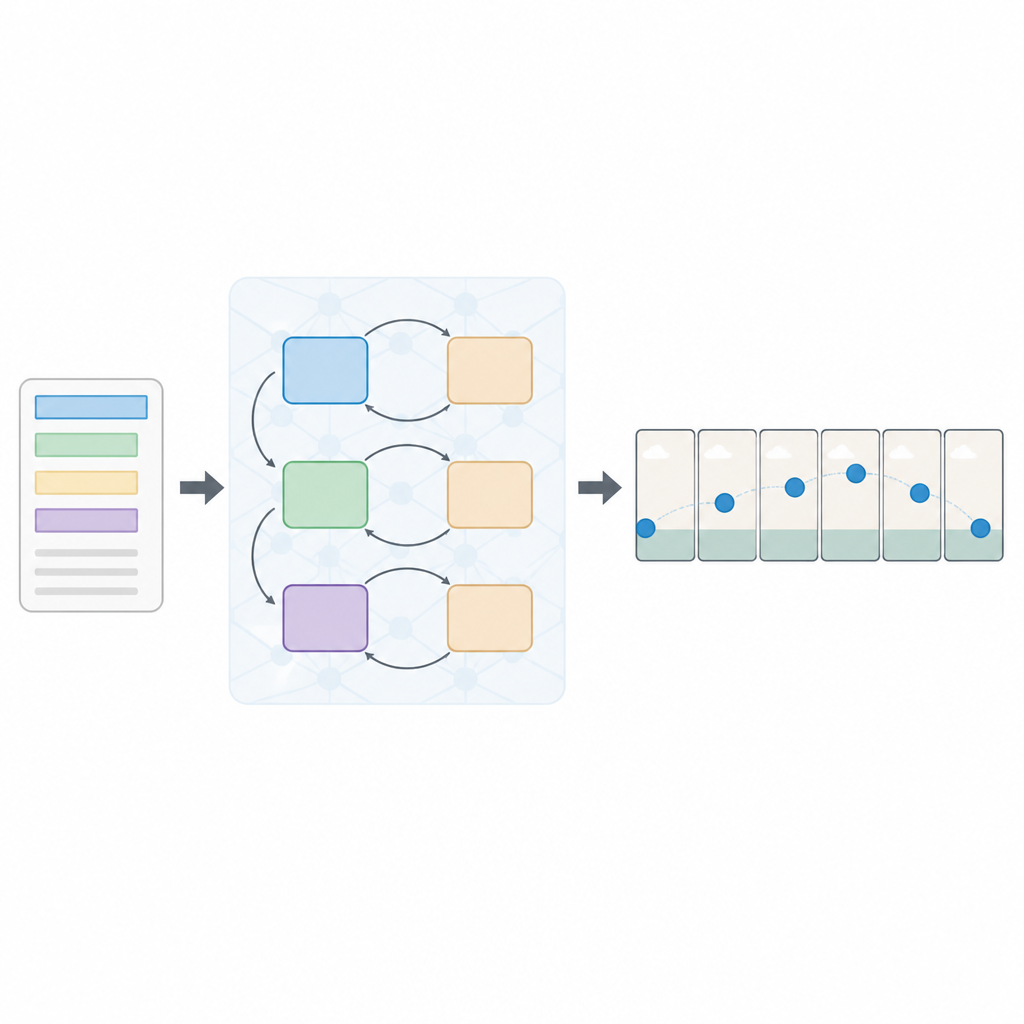
Nawarstwione podejście do czytania i widzenia
Autorzy proponują nowe rozwiązanie nazwane wielostratawą sekwencyjną siecią generatywną przeciwnika, w skrócie Seq-GAN. Najpierw enkoder tekstu oparty na LSTM czyta zdanie słowo po słowie i konwertuje je do zwartego numerycznego „streszczenia”, które uchwyca sens. Równolegle zmodyfikowany autoenkoder wariacyjny tworzy „zarys” obrazu na podstawie pierwszej klatki, skupiając się na ogólnym kolorze tła i układzie, a nie na drobnych szczegółach. Ten zarys działa jak szkic sceny, który później kieruje ruchem i wyglądem końcowych klatek wideo.
Wielu krytyków dla ostrzejszych wyników
W sercu systemu znajdują się trzy sieci generatorów oraz trzy sieci dyskryminatorów, czyli krytyków, ustawione w sekwencji. Każdy generator próbuje tworzyć klatki wideo, które wyglądają realistycznie i pasują do tekstu, podczas gdy każdy dyskryminator stara się odróżnić prawdziwe wideo od wygenerowanego. Nietypowo, każda para generator–dyskryminator jest trenowana z inną strategią optymalizacji: RMSprop, Adam lub stochastyczny spadek gradientu. Te oddzielne „straty” zachęcają każdy etap do specjalizacji: pierwszy buduje podstawową strukturę, drugi poprawia klarowność i timing, a trzeci skupia się na tym, czy klip rzeczywiście odzwierciedla opisaną akcję. Traktując tworzenie klatek jako proces decyzyjny krok po kroku, model lepiej utrzymuje płynny ruch w czasie.
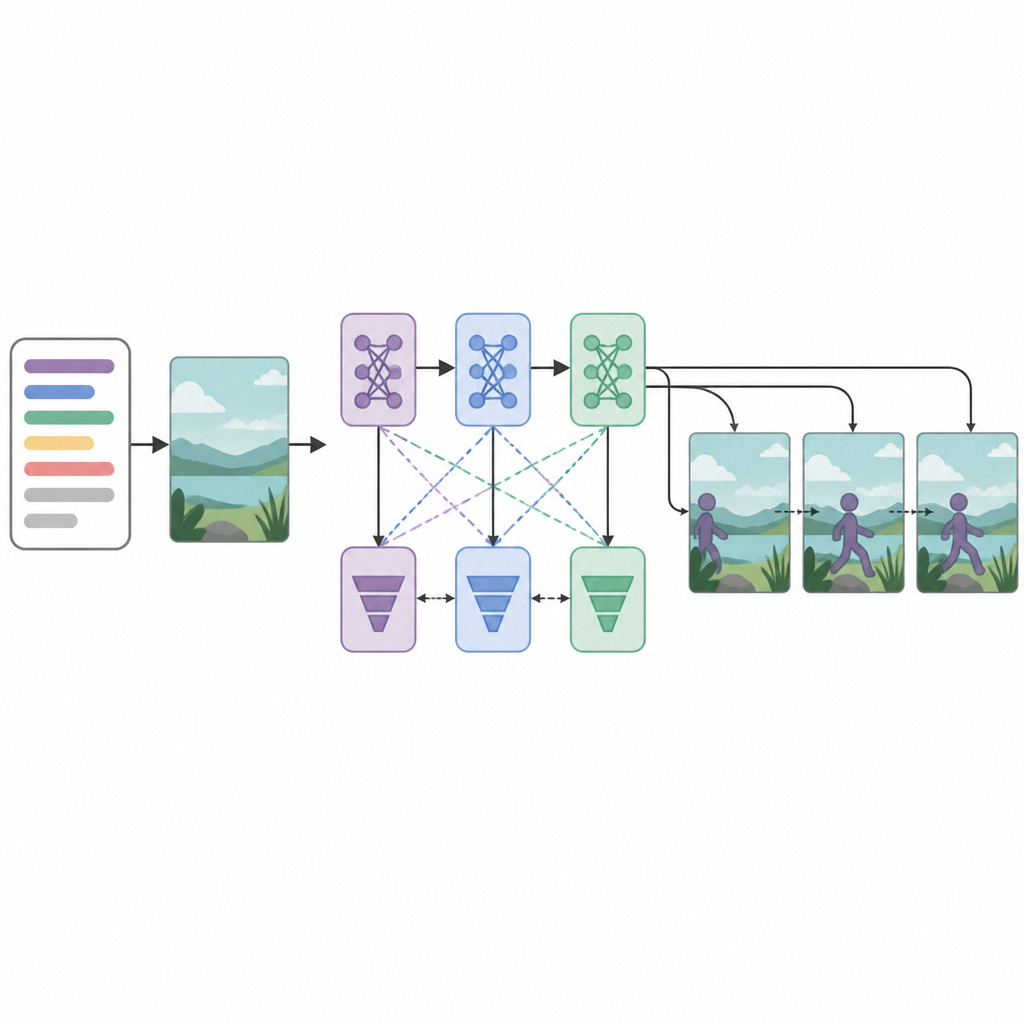
Jak dobrze działa system
Badacze przetestowali swoją metodę na trzech zbiorach danych: prostym pokazującym pojedyncze cyfry odbijające się, oraz na dwóch dużych kolekcjach ludzkich aktywności (KTH i UCF-101) obejmujących czynności takie jak chodzenie, bieganie, boks i różne sporty. Użyli powszechnie znanych miar oceny: Inception Score dla różnorodności i ostrości klatek, Fréchet Video Distance dla podobieństwa wygenerowanych klipów do prawdziwych oraz CLIP-similarity dla dopasowania treści wideo do tekstu. W tych testach nowy Seq-GAN konsekwentnie przewyższał wcześniejsze systemy oparte na GAN-ach i był konkurencyjny wobec nowszych modeli text-to-video, zwłaszcza w utrzymywaniu spójnego ruchu i dopasowania treści do opisu.
Ograniczenia i co dalej
Pomimo zalet metoda wciąż ma problemy z długimi lub złożonymi scenami, wysokimi rozdzielczościami oraz bardzo szczegółowymi opisami obejmującymi wielu ludzi lub obiekty. W miarę zwiększania liczby klatek lub rozmiaru wideo mogą pojawiać się drobne usterki i rozmycia, a system może pominąć subtelniejsze elementy opisu. Autorzy sugerują dalsze badania, które porównają ich podejście bezpośrednio z dużymi modelami wideo opartymi na dyfuzji oraz zbadają hybrydowe projekty łączące szybkość treningu przeciwników z wysokim poziomem szczegółu modeli dyfuzyjnych.
Co to oznacza dla zwykłych użytkowników
Dla osób niebędących ekspertami kluczowy przekaz jest taki, że praca ta przybliża nas do narzędzi, w których krótkie, prostoliniowe polecenia w języku naturalnym mogą generować krótkie, wiarygodne klipy wideo. Poprzez połączenie rozumienia języka, zgrubnego szkicu wizualnego i kilku etapów kontroli jakości, proponowane ramy Seq-GAN pokazują, że możliwe jest generowanie wideo, które nie tylko wygląda realistycznie, ale też pozostaje zgodne z naszym opisem, wskazując drogę do bardziej intuicyjnych sposobów tworzenia i edycji wizualnych opowieści w przyszłości.
Cytowanie: Ullah, A., Xing, Z., Tasir, M.A.M. et al. Text-to-video generation with multi-loss sequential generative adversarial network. Sci Rep 16, 14966 (2026). https://doi.org/10.1038/s41598-026-45313-7
Słowa kluczowe: text-to-video, sieć generatywna przeciwstawna, generowanie wideo, uczenie głębokie, spójność czasowa