Clear Sky Science · it
Generazione da testo a video con una rete generativa avversaria sequenziale a perdite multiple
Trasformare le parole in immagini in movimento
Immaginate di digitare una breve descrizione come “una persona che fa jogging in un parco” e di ottenere subito un piccolo clip video che la rappresenti. Questo studio affronta proprio quella sfida: insegnare ai computer a trasformare il linguaggio quotidiano in brevi video realistici che restino fedeli al testo e appaiano fluidi da un fotogramma all’altro. Questa tecnologia potrebbe alimentare nuovi strumenti per l’istruzione, l’intrattenimento, il design e l’accessibilità, ma è sorprendentemente difficile far sì che i risultati siano allo stesso tempo credibili e coerenti nel tempo.
Perché il video è più difficile delle immagini
Generare una singola immagine a partire dal testo è già complesso, eppure i sistemi moderni lo gestiscono abbastanza bene. Il video alza l’asticella: ogni fotogramma deve non solo corrispondere alla descrizione, ma anche essere coerente con i fotogrammi vicini nel tempo. Se lo sfondo cambia improvvisamente o la sagoma di una persona si deforma tra fotogrammi, l’illusione del movimento si rompe. I dataset video pubblici aggiungono un ulteriore livello di difficoltà perché mescolano angolazioni di ripresa diverse, condizioni di illuminazione e stili d’azione. Di conseguenza, molti metodi precedenti producevano scene sfocate, movimenti spezzati o video che corrispondevano solo in modo approssimativo al testo di input.
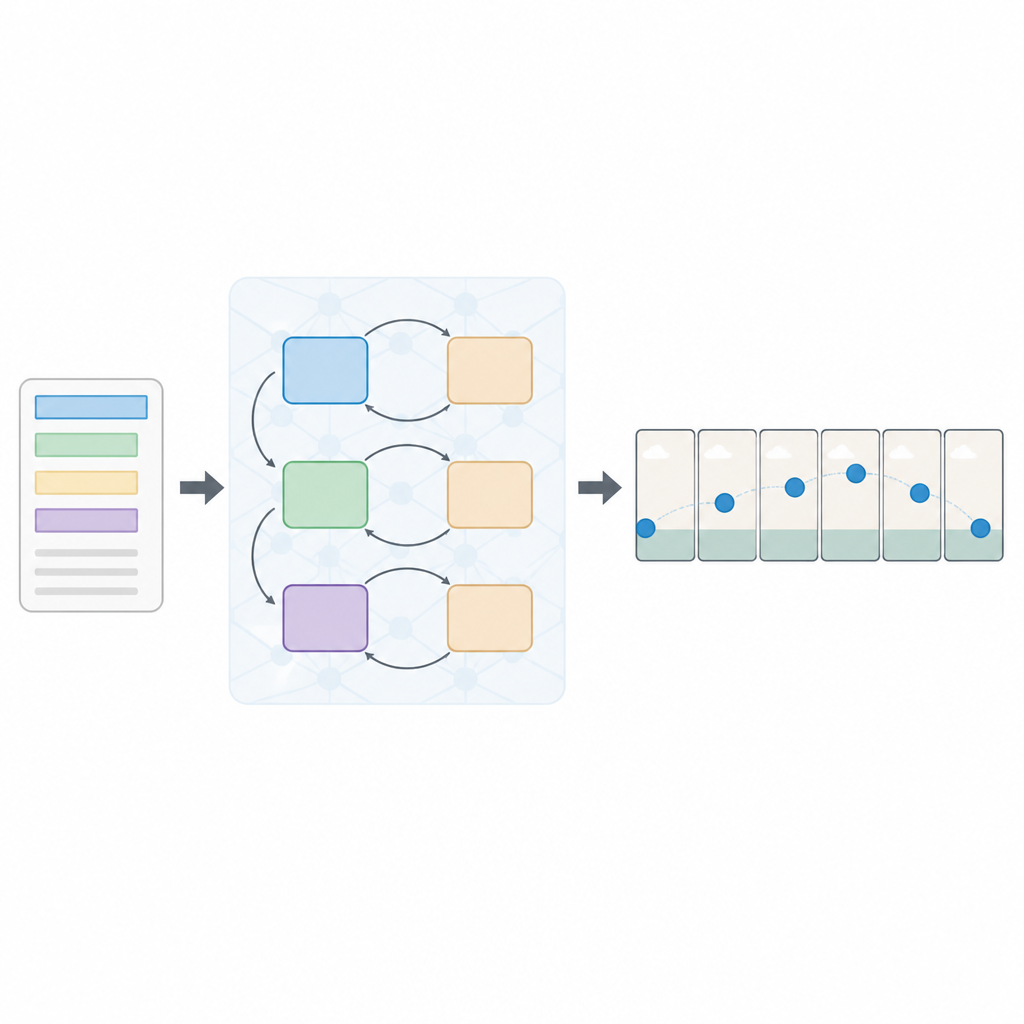
Un approccio stratificato per leggere e vedere
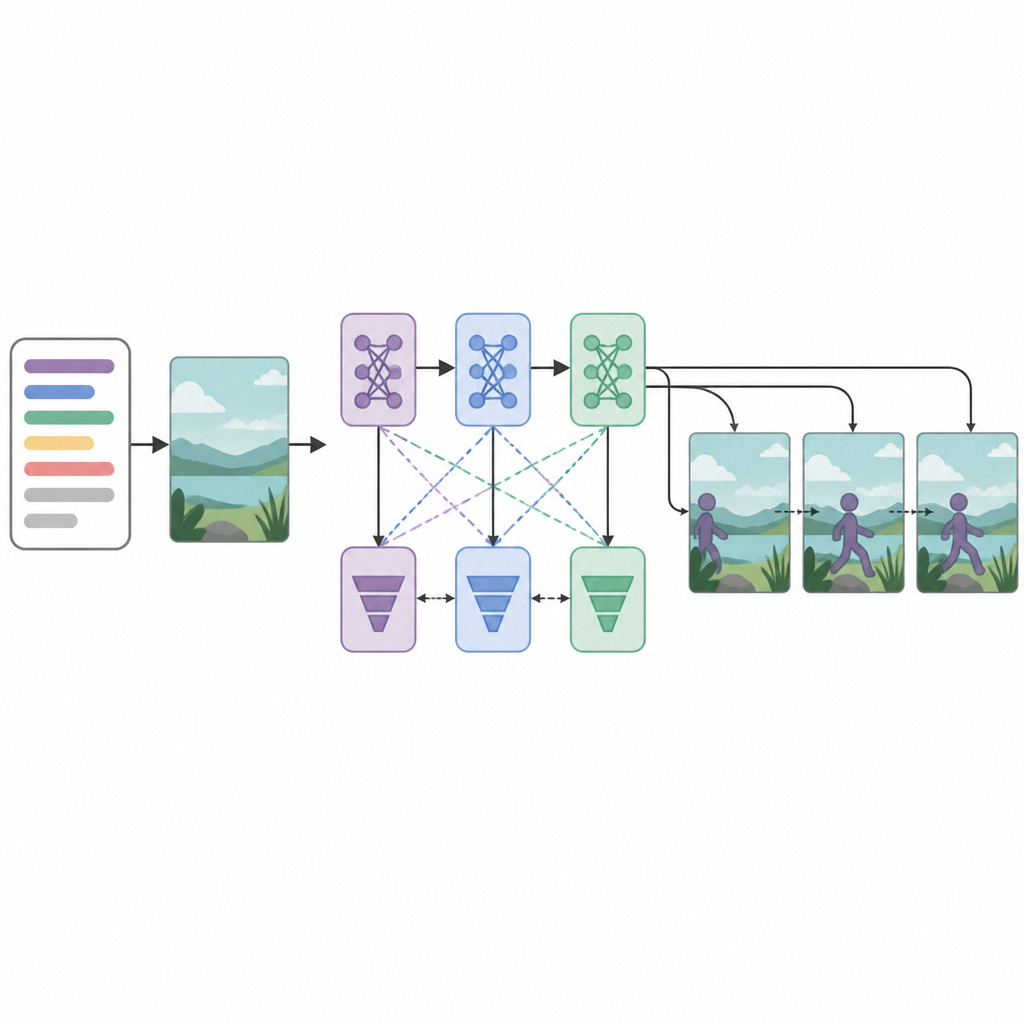
Gli autori propongono una nuova architettura chiamata rete generativa avversaria sequenziale a perdite multiple, o Seq-GAN. Prima, un codificatore testuale basato su LSTM legge la frase parola dopo parola e la converte in un “riassunto” numerico compatto che cattura il significato. In parallelo, un autoencoder variazionale modificato costruisce un’immagine «gist» a partire dal primo fotogramma, concentrandosi sul colore e la disposizione generale dello sfondo più che sui dettagli fini. Questo gist funge da schizzo approssimativo della scena, che poi guida il movimento e l’aspetto dei fotogrammi video finali.
Più critici per risultati più nitidi
Al centro del sistema ci sono tre reti generatrici e tre reti discriminatorie, o critici, disposte in sequenza. Ogni generatore tenta di creare fotogrammi video realistici e coerenti con il testo, mentre ogni discriminatore cerca di distinguere i video reali da quelli generati. In modo non convenzionale, ogni coppia generatore–discriminatore viene addestrata con una diversa strategia di ottimizzazione: RMSprop, Adam o discesa del gradiente stocastica. Queste perdite separate incoraggiano ogni fase a specializzarsi: la prima costruisce la struttura di base, la seconda migliora chiarezza e tempismo, e la terza si concentra sul fatto che il clip rifletta davvero l’azione descritta. Trattando la creazione dei fotogrammi come un processo decisionale passo dopo passo, il modello può mantenere meglio un movimento fluido nel tempo.
Quanto bene funziona il sistema
I ricercatori hanno testato il metodo su tre dataset: uno semplice che mostra singole cifre che rimbalzano e due collezioni ampie di azioni umane (KTH e UCF-101) che coprono attività come camminare, correre, boxe e vari sport. Hanno utilizzato misure note per giudicare il successo: l’Inception Score per varietà e nitidezza dei fotogrammi, la Fréchet Video Distance per quanto i clip generati somiglino a quelli reali, e la similarità CLIP per quanto il contenuto video corrisponda al testo. In tutti questi test, il nuovo Seq-GAN ha superato costantemente i sistemi GAN precedenti ed è risultato competitivo con modelli text-to-video più recenti, specialmente nel mantenere un movimento coerente e nel mantenere il contenuto allineato con la descrizione scritta.
Limiti e sviluppi futuri
Nonostante i suoi punti di forza, il metodo fatica ancora con scene lunghe o complesse, alte risoluzioni e testi molto dettagliati che coinvolgono più persone o oggetti. All’aumentare del numero di fotogrammi o delle dimensioni del video, possono comparire piccoli difetti e sfocature, e il sistema può perdere aspetti più sottili della descrizione. Gli autori suggeriscono lavori futuri che confrontino il loro approccio in modo più diretto con grandi modelli video basati su diffusione ed esplorino design ibridi che combinino la velocità dell’addestramento avversario con l’elevato livello di dettaglio dei metodi di diffusione.
Cosa significa per gli utenti comuni
Per i non esperti, il messaggio chiave è che questo lavoro ci avvicina a strumenti in cui brevi prompt in linguaggio naturale possono guidare la creazione di brevi clip video credibili. Combinando comprensione del linguaggio, uno schizzo visivo approssimativo e diverse fasi di controllo qualità, il framework Seq-GAN proposto dimostra che è possibile generare video che non solo appaiono realistici, ma rimangono anche in sintonia con quanto richiesto, indicando modi più intuitivi per creare e modificare storie visive in futuro.
Citazione: Ullah, A., Xing, Z., Tasir, M.A.M. et al. Text-to-video generation with multi-loss sequential generative adversarial network. Sci Rep 16, 14966 (2026). https://doi.org/10.1038/s41598-026-45313-7
Parole chiave: text-to-video, generative adversarial network, video generation, deep learning, temporal coherence