Clear Sky Science · fr
Génération de texte en vidéo avec un réseau antagoniste génératif séquentiel à pertes multiples
Transformer les mots en images animées
Imaginez taper une courte description comme « une personne fait du jogging dans un parc » et obtenir instantanément un petit clip vidéo correspondant. Cette étude s'attaque précisément à ce défi : apprendre aux ordinateurs à transformer le langage courant en courtes vidéos réalistes qui restent fidèles au texte et paraissent fluides d'une image à l'autre. Une telle technologie pourrait alimenter de nouveaux outils pour l'éducation, le divertissement, le design et l'accessibilité, mais il est étonnamment difficile d'obtenir des résultats à la fois crédibles et cohérents dans le temps.
Pourquoi la vidéo est plus difficile que l'image
Générer une image unique à partir d'un texte est déjà complexe, pourtant les systèmes modernes le font relativement bien. La vidéo relève la mise : chaque image doit non seulement correspondre à la description, mais aussi s'accorder avec ses voisines temporelles. Si l'arrière-plan change brutalement ou si la silhouette d'une personne se déforme entre deux images, l'illusion du mouvement se brise. Les jeux de données vidéo publics ajoutent une couche de difficulté en mélangeant angles de caméra, conditions d'éclairage et styles d'action différents. En conséquence, de nombreuses méthodes antérieures produisaient des scènes floues, des mouvements cassés ou des vidéos qui correspondaient seulement de façon approximative au texte d'entrée.
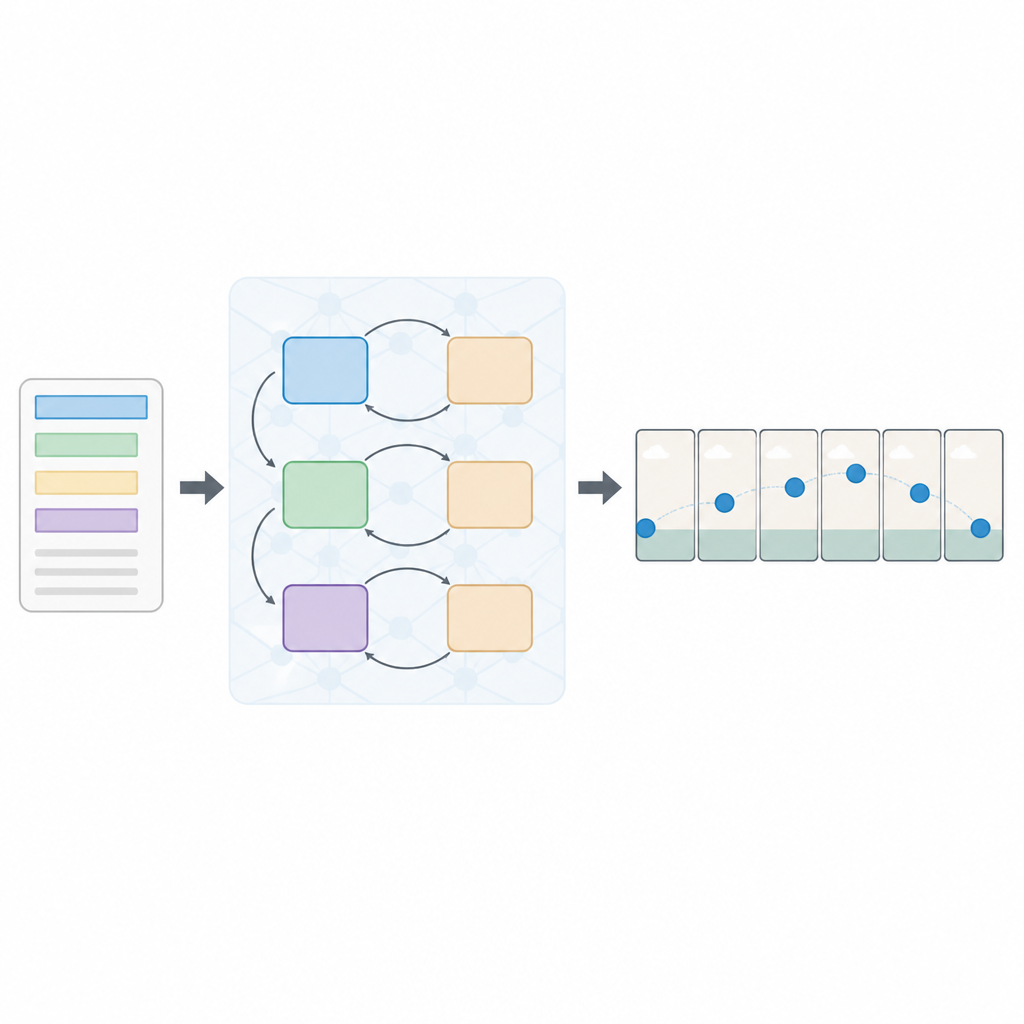
Une approche en couches pour lire et voir
Les auteurs proposent une nouvelle architecture appelée réseau antagoniste génératif séquentiel à pertes multiples, ou Seq-GAN en abrégé. D'abord, un encodeur de texte basé sur un LSTM lit la phrase mot par mot et la convertit en un « résumé » numérique compact capturant le sens. En parallèle, un autoencodeur variationnel modifié construit une image de « gist » à partir de la première image, se concentrant sur la couleur et la disposition générales plutôt que sur les détails fins. Ce gist joue le rôle d'esquisse grossière de la scène, qui guidera ensuite le mouvement et l'apparence des images finales de la vidéo.
Plusieurs critiques pour des résultats plus nets
Au cœur du système se trouvent trois réseaux générateurs et trois réseaux discriminateurs, ou critiques, organisés en séquence. Chaque générateur tente de créer des images vidéo réalistes et conformes au texte, tandis que chaque discriminateur essaie de distinguer les vidéos réelles des vidéos générées. De manière inhabituelle, chaque paire générateur–discriminateur est entraînée avec une stratégie d'optimisation différente : RMSprop, Adam ou descente de gradient stochastique. Ces pertes distinctes encouragent chaque étape à se spécialiser : la première construit la structure de base, la seconde améliore la clarté et le timing, et la troisième se concentre sur la fidélité de l'action décrite. En traitant la création d'images comme un processus de décision étape par étape, le modèle peut mieux maintenir un mouvement fluide au fil du temps.
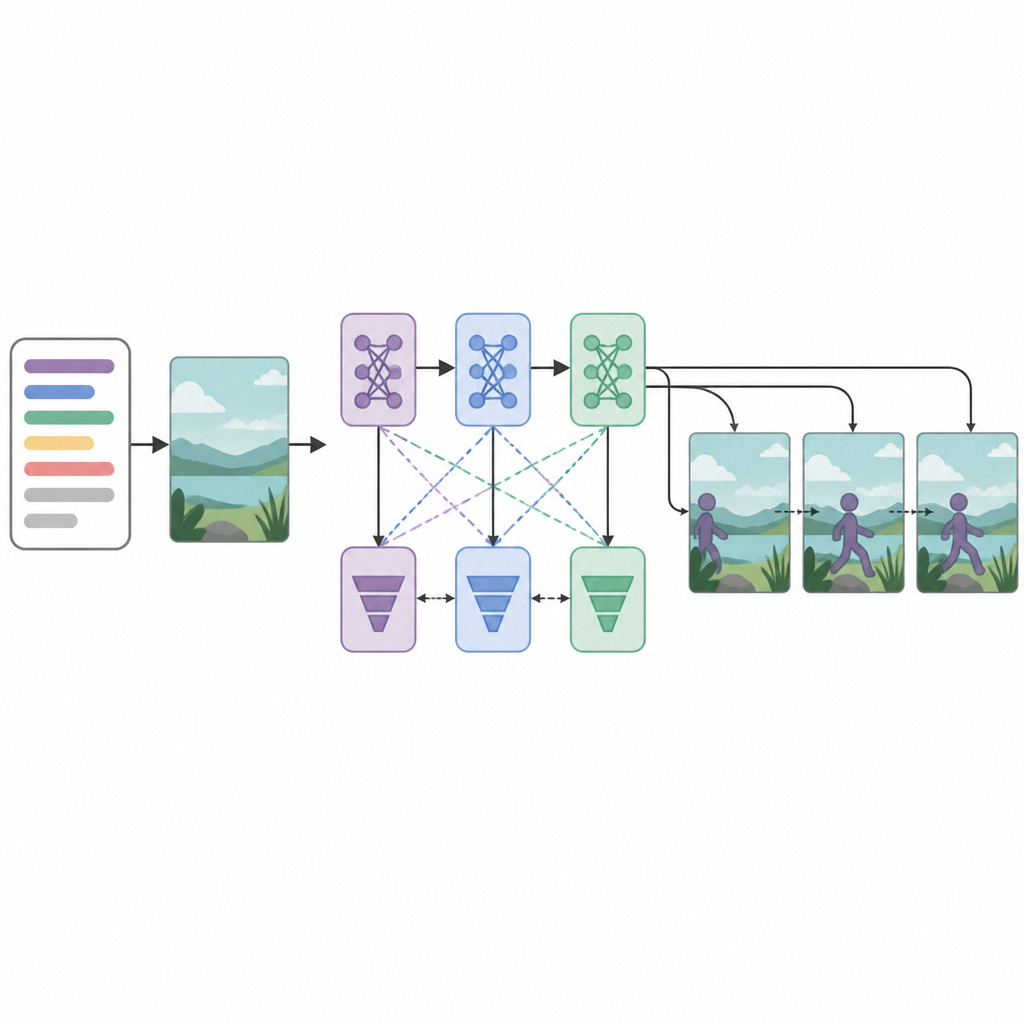
Performances du système
Les chercheurs ont testé leur méthode sur trois ensembles de données : un jeu simple montrant des chiffres uniques rebondissant, et deux grandes collections d'actions humaines (KTH et UCF-101) couvrant des activités comme marcher, courir, boxer et divers sports. Ils ont utilisé des mesures bien connues pour juger du succès : le score Inception pour la variété et la clarté des images, la distance vidéo de Fréchet pour l'affinité des clips générés avec les vidéos réelles, et la similarité CLIP pour l'adéquation du contenu vidéo au texte. Dans ces tests, le nouveau Seq-GAN a systématiquement surpassé les systèmes antérieurs basés sur les GAN et a été compétitif avec des modèles texte-en-vidéo plus récents, en particulier pour maintenir un mouvement cohérent et garder le contenu aligné sur la description écrite.
Limites et perspectives
Malgré ses points forts, la méthode peine encore avec des scènes longues ou complexes, des résolutions élevées et des textes très détaillés impliquant plusieurs personnes ou objets. À mesure que le nombre d'images ou la taille de la vidéo augmente, de petits défauts et du flou peuvent apparaître, et le système peut manquer des éléments plus subtils de la description. Les auteurs suggèrent des travaux futurs comparant leur approche de façon plus directe avec de grands modèles vidéo basés sur la diffusion et explorant des architectures hybrides qui mêleraient la rapidité de l'entraînement antagoniste à la richesse de détail des méthodes de diffusion.
Ce que cela signifie pour les utilisateurs
Pour les non‑spécialistes, l'idée principale est que ce travail nous rapproche d'outils où des invites courtes en langage naturel peuvent générer des clips vidéo brefs et crédibles. En combinant compréhension du langage, esquisse visuelle sommaire et plusieurs étapes de contrôle qualité, le cadre Seq-GAN proposé montre qu'il est possible de produire des vidéos qui non seulement semblent réalistes mais restent en phase avec ce que l'on a demandé, ouvrant la voie à des manières plus intuitives de créer et d'éditer des récits visuels à l'avenir.
Citation: Ullah, A., Xing, Z., Tasir, M.A.M. et al. Text-to-video generation with multi-loss sequential generative adversarial network. Sci Rep 16, 14966 (2026). https://doi.org/10.1038/s41598-026-45313-7
Mots-clés: texte-en-vidéo, réseau antagoniste génératif, génération vidéo, apprentissage profond, cohérence temporelle