Clear Sky Science · ru
Генерация видео из текста с помощью последовательной генеративной состязательной сети с несколькими функциями потерь
Превращение слов в движущиеся изображения
Представьте, что вы вводите короткое описание вроде «человек бегает в парке» и мгновенно получаете небольшой видеоклип, соответствующий ему. Это исследование решает именно такую задачу: обучить компьютеры преобразовывать обычный язык в короткие реалистичные видео, которые точно отражают текст и выглядят плавно от кадра к кадру. Такая технология может дать начало новым инструментам для образования, развлечений, дизайна и доступности, но добиться правдоподобия и согласованности во времени одновременно — куда сложнее, чем кажется.
Почему видео сложнее изображений
Сгенерировать одно изображение по тексту уже непросто, однако современные системы с этим справляются довольно хорошо. Видео ставит задачу выше: каждый кадр должен не только соответствовать описанию, но и согласовываться с соседними кадрами во времени. Если фон вдруг меняется или форма человека искажается между кадрами, иллюзия движения рушится. Публичные видеодатасеты добавляют ещё сложностей: они смешивают разные углы съёмки, условия освещения и стили действий. В результате многие ранние методы давали размытые сцены, прерывистое движение или видео, слабо связанное с входным текстом.
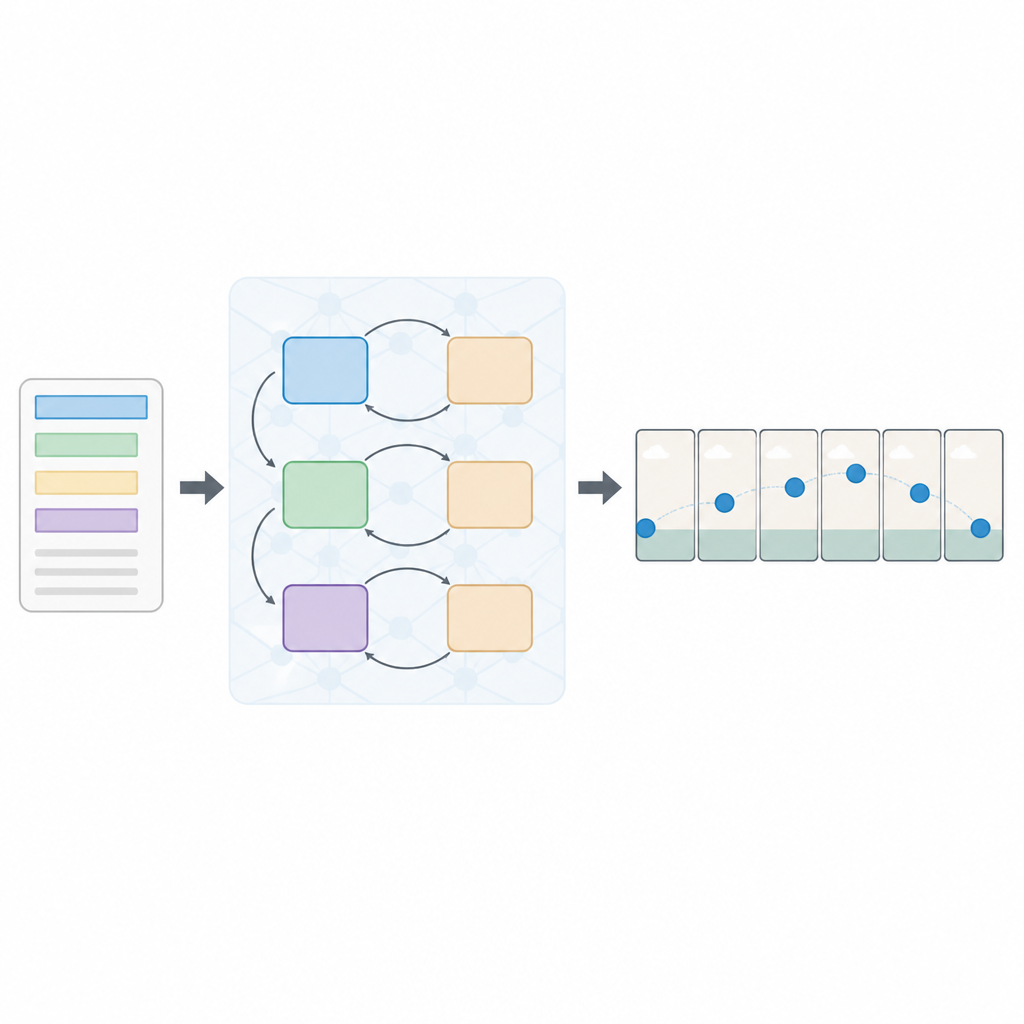
Слоистый подход к чтению и видению
Авторы предлагают новую архитектуру, называемую многопотерьной последовательной генеративной состязательной сетью, или Seq-GAN. Сначала текстовый энкодер на базе LSTM читает предложение слово за словом и преобразует его в компактное числовое «резюме», фиксирующее смысл. Параллельно модифицированный вариационный автоэнкодер строит «эскиз» — изображение-опору из первого кадра, уделяя внимание общей цветовой гамме и расположению компонентов сцены, а не тонким деталям. Этот эскиз служит грубым наброском сцены, который затем направляет движение и внешний вид конечных кадров видео.
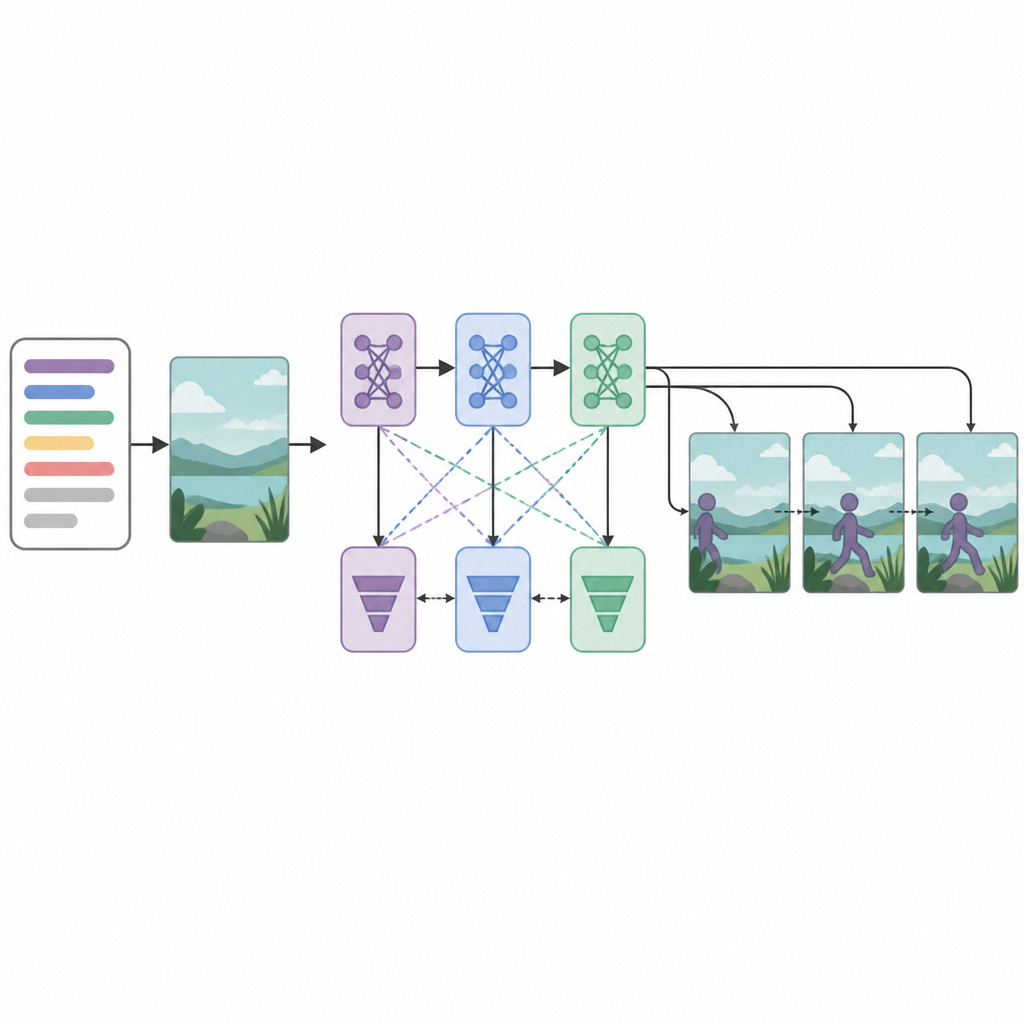
Несколько критиков для более чётких результатов
В ядре системы расположены три сети-генератора и три дисриминатора, или «критика», выстроенные последовательно. Каждый генератор пытается создать кадры, которые выглядят реалистично и соответствуют тексту, а каждый дискриминатор пытается отличить реальные видео от сгенерированных. Необычно то, что каждая пара генератор–дискриминатор обучается с использованием разной оптимизационной стратегии: RMSprop, Adam или стохастического градиентного спуска. Эти отдельные «функции потерь» побуждают каждую стадию специализироваться: первая выстраивает базовую структуру, вторая улучшает чёткость и синхронизацию, а третья сосредоточена на том, действительно ли клип отражает описанное действие. Обращаясь к созданию кадров как к пошаговому процессу принятия решений, модель лучше поддерживает плавное движение во времени.
Насколько хорошо работает система
Исследователи протестировали свой метод на трёх наборах данных: простом, где отдельные цифры отскакивают, и двух больших коллекциях человеческих действий (KTH и UCF-101) с такими активностями, как ходьба, бег, бокс и различные виды спорта. Для оценки использовали общепринятые метрики: Inception Score для разнообразия и чёткости кадров, Fréchet Video Distance для измерения сходства с реальными клипами и CLIP-similarity для оценки соответствия содержимого видео тексту. По этим тестам новая Seq-GAN последовательно превосходила ранние GAN-базированные системы и конкурировала с более современными моделями текст-видео, особенно заметно удерживая связное движение и соответствие содержимого заданному описанию.
Ограничения и дальнейшие направления
Несмотря на сильные стороны, метод всё ещё испытывает трудности с длинными или сложными сценами, высокими разрешениями и очень подробными описаниями, включающими нескольких людей или объектов. По мере увеличения числа кадров или размера видео могут появляться мелкие артефакты и размытие, а система может упускать тонкие элементы описания. Авторы предлагают в будущем сравнить свой подход напрямую с крупными диффузионными моделями для видео и исследовать гибридные архитектуры, сочетающие быстроту обучения через состязание с высокой детализацией, которую дают диффузионные методы.
Что это значит для обычных пользователей
Для широкой аудитории главный вывод таков: эта работа приближает нас к инструментам, где короткие простые текстовые подсказки могут создавать правдоподобные видеоклипы. Комбинируя понимание языка, грубый визуальный эскиз и несколько стадий контроля качества, предложенная архитектура Seq-GAN демонстрирует, что возможно генерировать видео, которые не только выглядят реалистично, но и соответствуют нашим запросам, открывая путь к более интуитивным способам создания и редактирования визуальных историй в будущем.
Цитирование: Ullah, A., Xing, Z., Tasir, M.A.M. et al. Text-to-video generation with multi-loss sequential generative adversarial network. Sci Rep 16, 14966 (2026). https://doi.org/10.1038/s41598-026-45313-7
Ключевые слова: текст-видео, генеративная состязательная сеть, генерация видео, глубокое обучение, временная когерентность