Clear Sky Science · tr
Çoklu-kayıp sıralı üretici karşıt ağ ile metinden-videoya üretim
Sözleri hareketli görüntülere dönüştürmek
“Bir kişinin parkta koşması” gibi kısa bir açıklamayı yazdığınızı ve bununla anında uyumlu küçük bir video klip elde ettiğinizi hayal edin. Bu çalışma tam da bu meydan okumayla ilgileniyor: bilgisayarları günlük dili kısa, gerçekçi videolara dönüştürmeye öğretmek; metne sadık kalan ve kareden kareye akıcı görünen videolar üretmek. Bu teknoloji eğitim, eğlence, tasarım ve erişilebilirlik için yeni araçlar sağlayabilir, ancak sonuçların hem inandırıcı hem de zaman içinde tutarlı görünmesini sağlamak beklenenden zor oluyor.
Videonun görüntüden daha zor olmasının nedeni
Bir tek resmi metinden üretmek zaten zordur, buna rağmen modern sistemler bunu oldukça iyi yapabiliyor. Video ise çıtayı yükseltir: her kare sadece açıklamaya uymakla kalmamalı, aynı zamanda komşu karelerle de uyumlu olmalıdır. Arka plan aniden değişirse veya bir kişinin şekli kareler arasında bozulursa, hareket yanılsaması çöker. Halk veri setleri ayrıca farklı kamera açıları, aydınlatma koşulları ve hareket stillerini karıştırdığı için ayrı bir zorluk katmanı getirir. Sonuç olarak birçok önceki yöntem bulanık sahneler, bozulmuş hareketler veya girdiye sadece gevşekçe uyan videolar üretti.
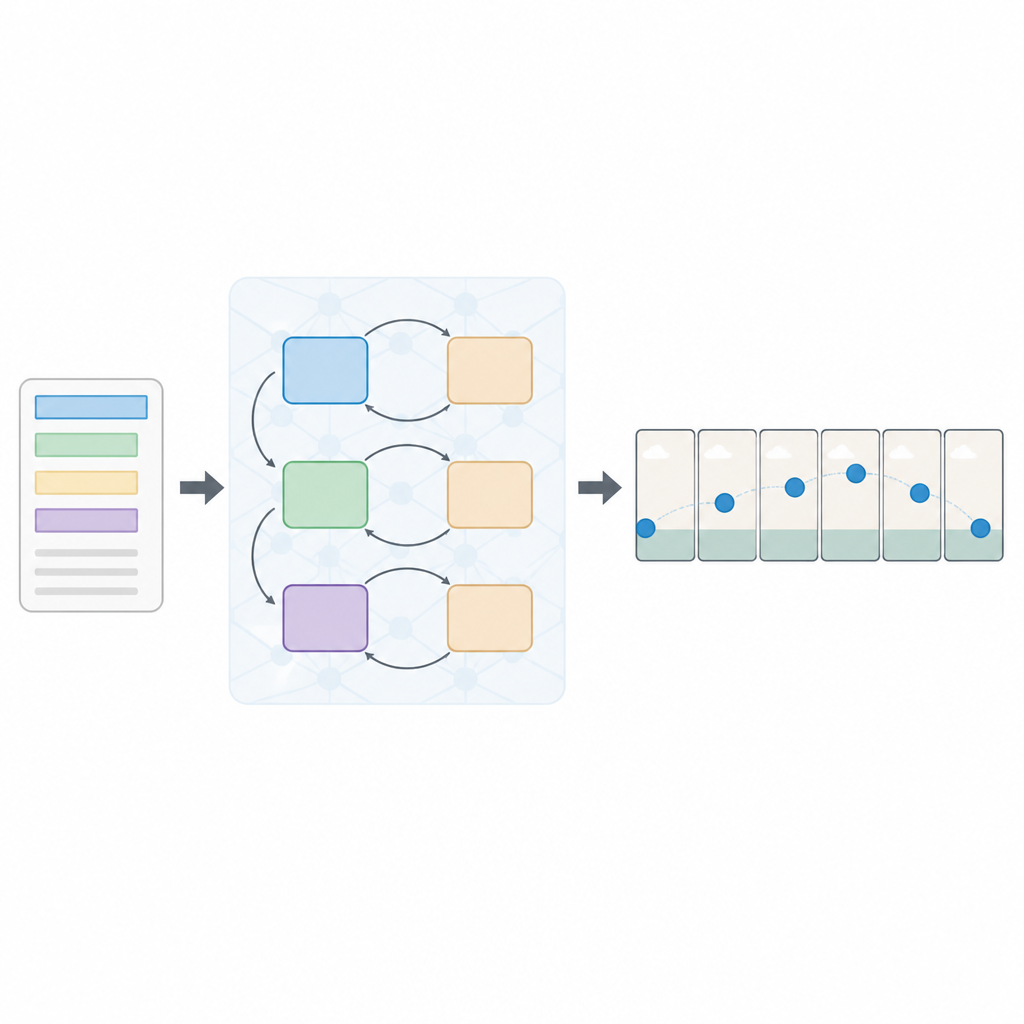
Okuma ve görme için katmanlı bir yaklaşım
Yazarlar, çoklu-kayıp Sıralı Üretici Karşıt Ağ (Seq-GAN) adlı yeni bir düzen öneriyor. Önce, LSTM tabanlı bir metin kodlayıcı cümleyi kelime kelime okur ve anlamı yakalayan kompakt bir sayısal “özet”e dönüştürür. Paralel olarak, değiştirilmiş bir varyasyonel oto-kodlayıcı ilk kareden bir “öz” (gist) görüntüsü oluşturur; bu, ince ayrıntılardan ziyade genel arka plan rengi ve düzenine odaklanır. Bu öz, sahnenin kaba bir taslağı gibi davranır ve daha sonra nihai video karelerinin hareketini ve görünümünü yönlendirir.
Daha keskin sonuçlar için birden çok eleştirmen
Sistemin kalbinde sıralı olarak düzenlenmiş üç üretici ağı ve üç ayrımcı ya da eleştirmen ağı bulunur. Her üretici, metne uyan ve gerçekçi görünen video kareleri üretmeye çalışırken, her ayrımcı gerçek videoları üretilmiş olanlardan ayırmaya çalışır. Alışılmadık şekilde, her üretici–ayrımcı çifti farklı bir optimizasyon stratejisiyle eğitilir: RMSprop, Adam veya stokastik gradyan inişi. Bu ayrı “kayıplar” her aşamanın uzmanlaşmasını teşvik eder: ilk aşama temel yapıyı inşa eder, ikinci aşama netlik ve zamanlamayı geliştirir, üçüncüsü ise klibin gerçekten tanımlanan hareketi yansıtıp yansıtmadığına odaklanır. Kare oluşturmayı adım adım bir karar süreci olarak ele alarak model, zaman içinde daha düzgün hareketi daha iyi koruyabilir.
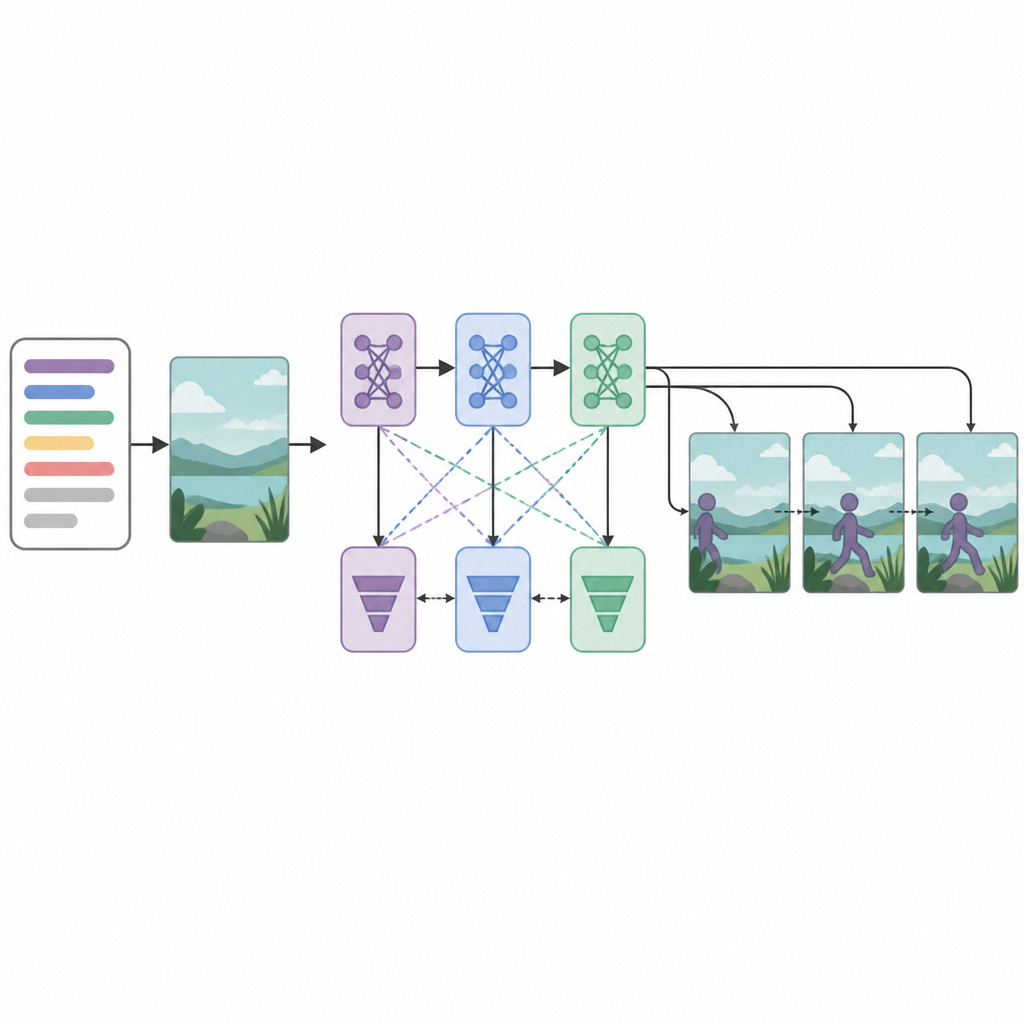
Sistemin ne kadar iyi performans gösterdiği
Araştırmacılar yöntemlerini üç veri setinde test ettiler: etrafta zıplayan tek basamaklı rakamları gösteren basit bir set ve yürüyüş, koşu, boks ve çeşitli sporlar gibi faaliyetleri içeren iki büyük insan hareketleri koleksiyonu (KTH ve UCF-101). Başarıyı değerlendirmek için bilinen ölçüler kullanıldı: karelerin çeşitliliği ve netliği için Inception Score, üretilen kliplerin gerçek olanlara ne kadar benzediği için Fréchet Video Distance ve video içeriğinin metne ne kadar iyi uyduğunu ölçmek için CLIP-benzerliği. Bu testlerin tamamında yeni Seq-GAN, önceki GAN tabanlı sistemleri tutarlı şekilde geride bıraktı ve özellikle tutarlı hareketi koruma ve içeriği yazılı açıklama ile hizalama konusunda daha yeni metinden-videoya modellerle rekabet edecek düzeyde performans gösterdi.
Sınırlamalar ve sonraki adımlar
Güçlü yönlerine rağmen yöntem hâlâ uzun veya karmaşık sahneler, yüksek çözünürlükler ve birden çok insan veya nesne içeren çok ayrıntılı metinlerle zorlanıyor. Kare sayısı veya video boyutu arttıkça küçük hatalar ve bulanıklık ortaya çıkabilir ve sistem açıklamanın daha ince parçalarını kaçırabilir. Yazarlar, yaklaşımlarını büyük difüzyon tabanlı video modelleriyle daha doğrudan karşılaştıran ve karşıt eğitim hızını difüzyon yöntemlerinin yüksek ayrıntısıyla harmanlayan hibrit tasarımları araştıran gelecekteki çalışmaları öneriyor.
Günlük kullanıcılar için anlamı
Uzman olmayanlar için temel mesaj şudur: bu çalışma, kısa, düz yazılı istemlerin kısa, inandırıcı video klipler üretmesini sağlayan araçlara bizi daha da yaklaştırıyor. Dil anlayışını, kaba bir görsel taslağı ve birkaç kalite kontrol aşamasını birleştirerek önerilen Seq-GAN çerçevesi, yalnızca gerçekçi görünen değil aynı zamanda talep ettiğimizle uyumlu kalan videolar üretmenin mümkün olduğunu gösteriyor; bu da gelecekte görsel hikâyeleri oluşturmak ve düzenlemek için daha sezgisel yolların işaretini veriyor.
Atıf: Ullah, A., Xing, Z., Tasir, M.A.M. et al. Text-to-video generation with multi-loss sequential generative adversarial network. Sci Rep 16, 14966 (2026). https://doi.org/10.1038/s41598-026-45313-7
Anahtar kelimeler: metinden-videoya, üretici karşıt ağ, video üretimi, derin öğrenme, zamansal tutarlılık