Clear Sky Science · es
Generación de texto a vídeo con una red generativa adversarial secuencial de pérdidas múltiples
Convertir palabras en imágenes en movimiento
Imagínese escribir una breve descripción como “una persona trotando en un parque” y obtener al instante un pequeño clip de vídeo que coincida con ella. Este estudio aborda precisamente ese desafío: enseñar a los ordenadores a transformar el lenguaje cotidiano en vídeos cortos y realistas que se mantengan fieles al texto y se vean fluidos cuadro a cuadro. Esta tecnología podría impulsar nuevas herramientas para la educación, el entretenimiento, el diseño y la accesibilidad, pero resulta sorprendentemente difícil lograr que los resultados sean a la vez creíbles y consistentes en el tiempo.
Por qué el vídeo es más difícil que las imágenes
Generar una sola imagen a partir de texto ya es complejo, aunque los sistemas modernos lo manejan bastante bien. El vídeo eleva el listón: cada fotograma no solo debe coincidir con la descripción, sino también con sus vecinos en el tiempo. Si el fondo cambia de forma repentina o la silueta de una persona se deforma entre fotogramas, la ilusión de movimiento se rompe. Los conjuntos de datos públicos de vídeo añaden otra capa de dificultad porque mezclan diferentes ángulos de cámara, condiciones de iluminación y estilos de acción. Como resultado, muchos métodos anteriores producían escenas borrosas, movimientos rotos o vídeos que solo coincidían de manera laxa con el texto de entrada.
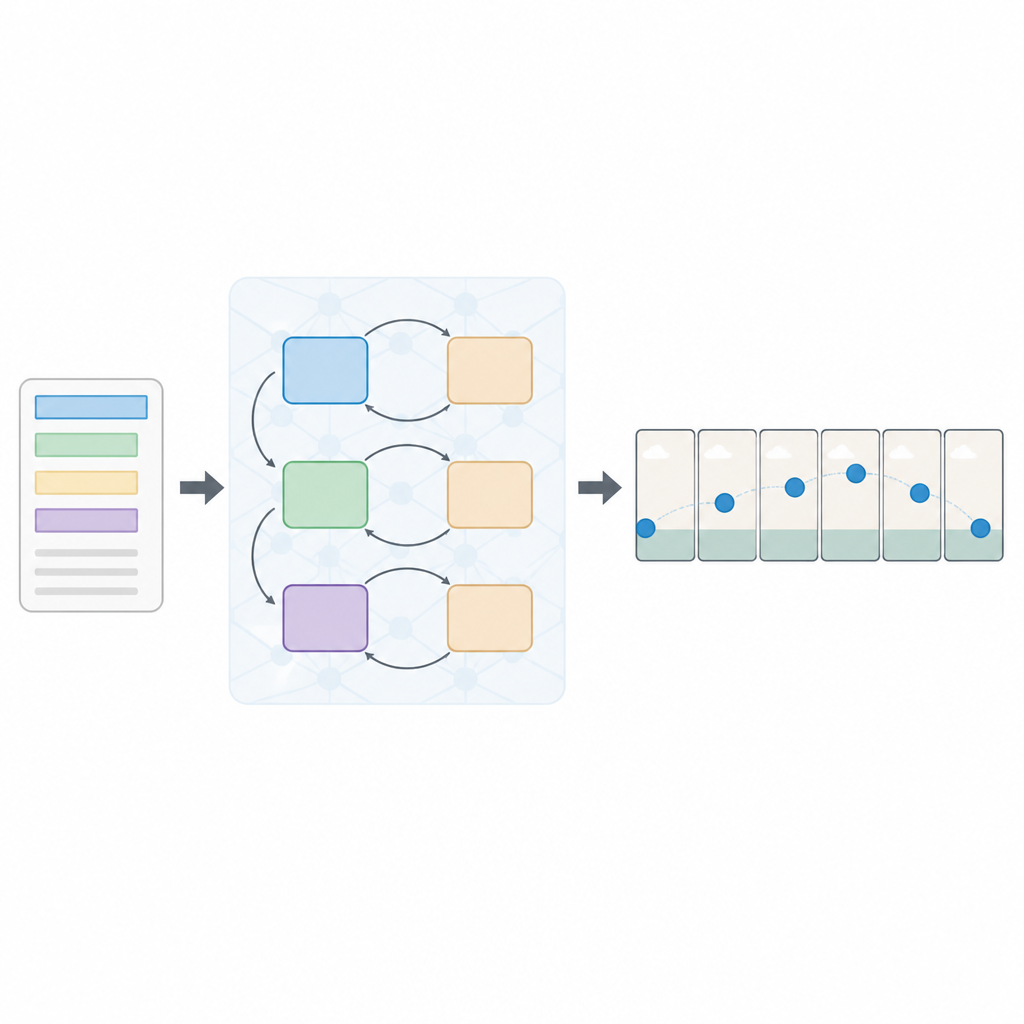
Un enfoque por capas para leer y ver
Los autores proponen una nueva arquitectura llamada Red Generativa Adversarial Secuencial de pérdidas múltiples, o Seq-GAN. Primero, un codificador de texto basado en LSTM lee la frase palabra por palabra y la convierte en un “resumen” numérico compacto que captura el significado. En paralelo, un autoencoder variacional modificado construye una imagen «esencial» a partir del primer fotograma, centrada en el color y la composición generales del fondo más que en los detalles finos. Esta esencia actúa como un boceto aproximado de la escena, que posteriormente guía el movimiento y la apariencia de los fotogramas finales del vídeo.
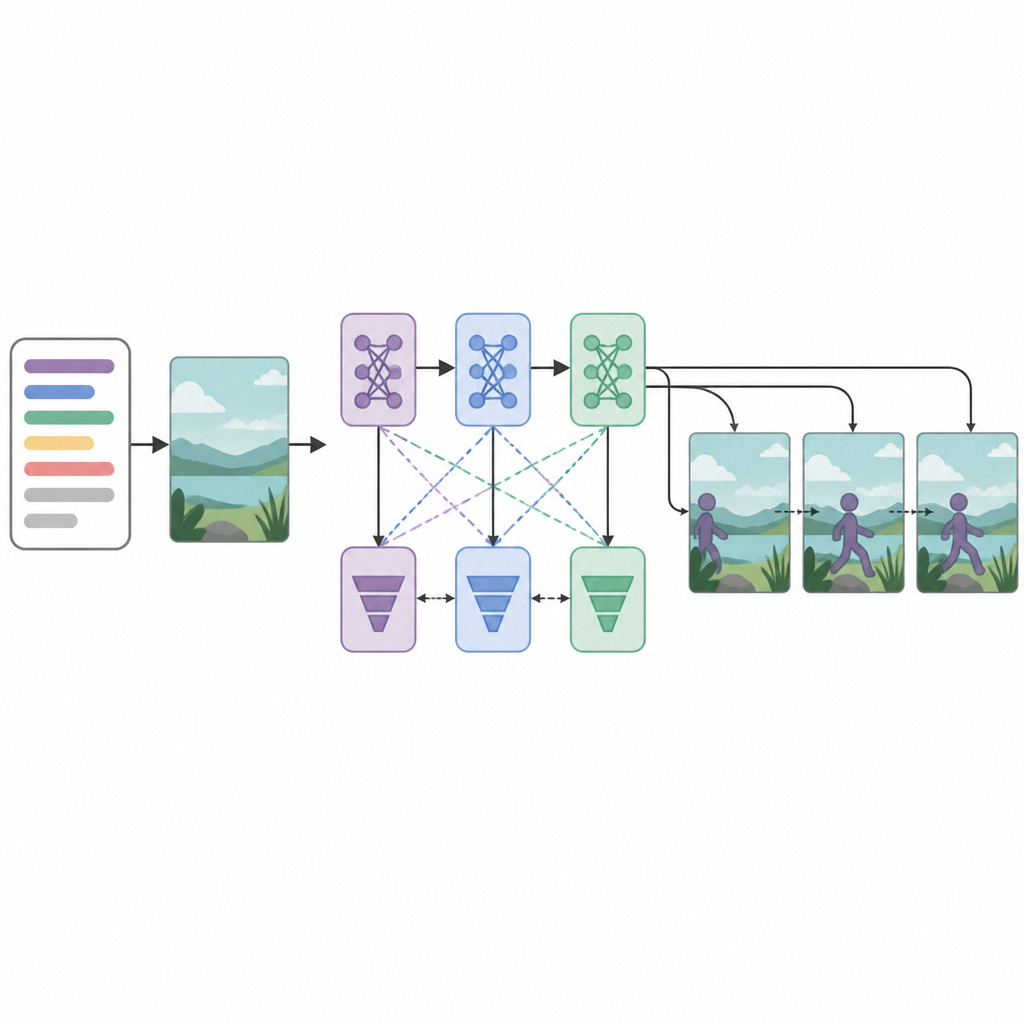
Múltiples críticos para resultados más nítidos
En el núcleo del sistema se encuentran tres redes generadoras y tres redes discriminadoras, o críticas, dispuestas en secuencia. Cada generador intenta crear fotogramas de vídeo que parezcan realistas y coincidan con el texto, mientras que cada discriminador trata de distinguir los vídeos reales de los generados. De forma inusual, cada par generador–discriminador se entrena con una estrategia de optimización distinta: RMSprop, Adam o descenso por gradiente estocástico. Estas «pérdidas» separadas fomentan que cada etapa se especialice: la primera construye la estructura básica, la segunda mejora la claridad y la sincronización, y la tercera se centra en si el clip refleja verdaderamente la acción descrita. Al tratar la creación de fotogramas como un proceso de decisión paso a paso, el modelo puede mantener mejor el movimiento suave a lo largo del tiempo.
Cómo rinde el sistema
Los investigadores probaron su método en tres conjuntos de datos: uno simple que muestra dígitos individuales rebotando y dos grandes colecciones de acciones humanas (KTH y UCF-101) que abarcan actividades como caminar, correr, boxeo y varios deportes. Usaron medidas conocidas para evaluar el éxito: la Inception Score para la variedad y claridad de los fotogramas, la Fréchet Video Distance para cuánto se parecen los clips generados a los reales, y la similitud CLIP para qué tan bien el contenido del vídeo coincide con el texto. En estas pruebas, el nuevo Seq-GAN superó de forma consistente a sistemas basados en GAN anteriores y fue competitivo frente a modelos de texto a vídeo más recientes, especialmente en mantener un movimiento coherente y mantener el contenido alineado con la descripción escrita.
Límites y próximos pasos
A pesar de sus puntos fuertes, el método aún tiene dificultades con escenas largas o complejas, altas resoluciones y textos muy detallados que involucren a varias personas u objetos. A medida que aumenta el número de fotogramas o el tamaño del vídeo, pueden aparecer pequeños fallos y borrosidad, y el sistema puede pasar por alto matices de la descripción. Los autores sugieren trabajos futuros que comparen su enfoque más directamente con grandes modelos de vídeo basados en difusión y que exploren diseños híbridos que combinen la velocidad del entrenamiento adversarial con el alto nivel de detalle de los métodos de difusión.
Qué significa esto para los usuarios cotidianos
Para los no expertos, el mensaje clave es que este trabajo nos acerca a herramientas en las que indicaciones breves en lenguaje natural puedan impulsar la creación de clips de vídeo cortos y creíbles. Al combinar comprensión del lenguaje, un boceto visual aproximado y varias etapas de control de calidad, el marco Seq-GAN propuesto demuestra que es posible generar vídeos que no solo parecen realistas, sino que también se mantienen sincronizados con lo que pedimos, abriendo paso a formas más intuitivas de crear y editar historias visuales en el futuro.
Cita: Ullah, A., Xing, Z., Tasir, M.A.M. et al. Text-to-video generation with multi-loss sequential generative adversarial network. Sci Rep 16, 14966 (2026). https://doi.org/10.1038/s41598-026-45313-7
Palabras clave: texto-a-vídeo, red generativa adversarial, generación de vídeo, aprendizaje profundo, coherencia temporal