Clear Sky Science · pt
Geração de texto para vídeo com rede generativa adversarial sequencial de perdas múltiplas
Transformando palavras em imagens em movimento
Imagine digitar uma curta descrição como “uma pessoa correndo em um parque” e receber instantaneamente um pequeno clipe de vídeo que corresponda a ela. Este estudo aborda exatamente esse desafio: ensinar computadores a transformar linguagem comum em vídeos curtos e realistas que permaneçam fiéis ao texto e tenham transições suaves de um quadro para outro. Essa tecnologia pode impulsionar novas ferramentas para educação, entretenimento, design e acessibilidade, mas é surpreendentemente difícil fazer com que os resultados pareçam tanto críveis quanto consistentes ao longo do tempo.
Por que vídeo é mais difícil que imagens
Gerar uma única imagem a partir de texto já é complicado, embora sistemas modernos o façam razoavelmente bem. Vídeo eleva o nível: cada quadro deve não só corresponder à descrição, mas também casar com seus vizinhos no tempo. Se o fundo muda de repente ou a forma de uma pessoa se deforma entre quadros, a ilusão de movimento se quebra. Bases de dados públicas de vídeo adicionam outra camada de dificuldade porque misturam diferentes ângulos de câmera, condições de iluminação e estilos de ação. Como resultado, muitos métodos anteriores produziam cenas borradas, movimentos quebrados ou vídeos que correspondiam apenas de forma vaga ao texto de entrada.
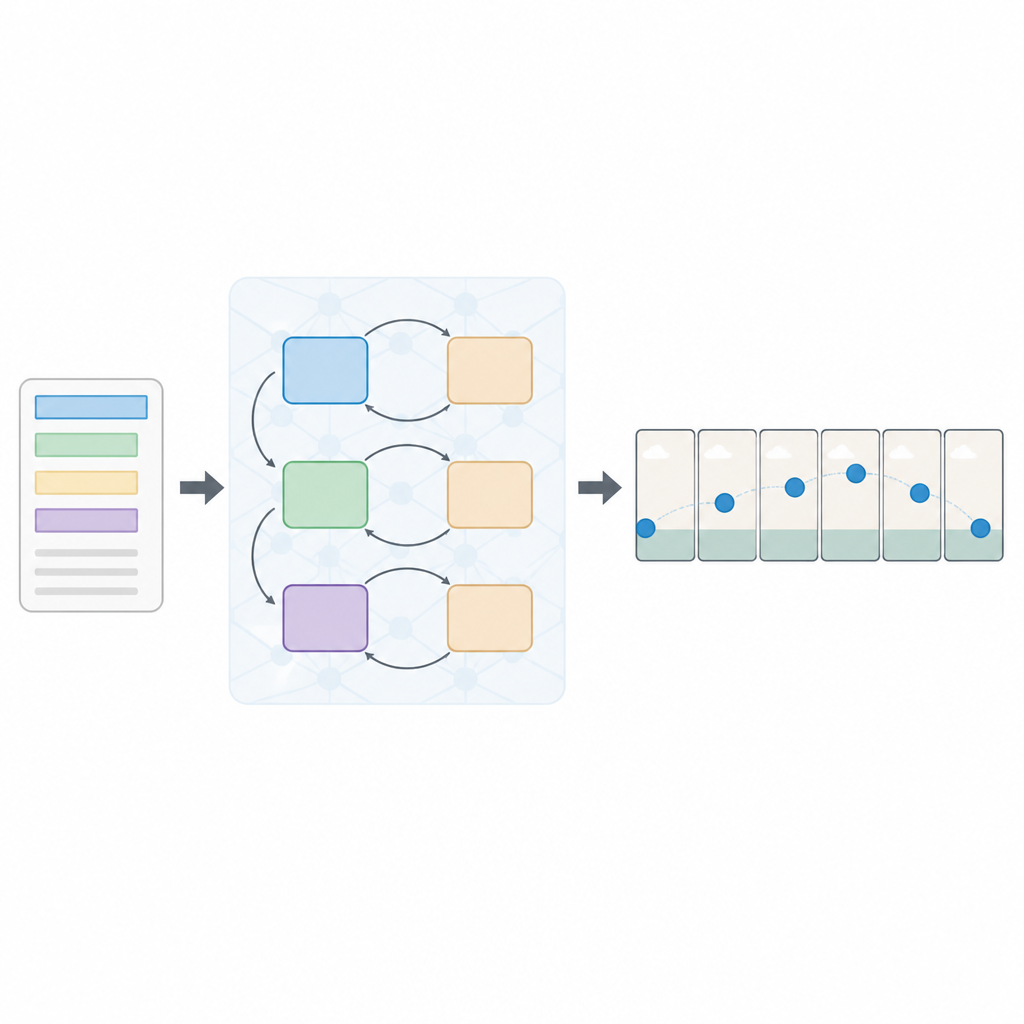
Uma abordagem em camadas para ler e ver
Os autores propõem uma nova arquitetura chamada Rede Generativa Adversarial Sequencial de perdas múltiplas, ou Seq-GAN. Primeiro, um codificador de texto baseado em LSTM lê a sentença palavra por palavra e a converte em um “resumo” numérico compacto que captura o significado. Em paralelo, um autoencoder variacional modificado constrói uma imagem “essencial” a partir do primeiro quadro, focando na cor e na disposição geral do fundo em vez de detalhes finos. Essa essência atua como um esboço grosseiro da cena, que depois orienta o movimento e a aparência dos quadros finais do vídeo.
Vários críticos para resultados mais nítidos
No núcleo do sistema estão três redes geradoras e três discriminadores, ou críticos, organizados em sequência. Cada gerador tenta criar quadros de vídeo que pareçam realistas e correspondam ao texto, enquanto cada discriminador tenta distinguir vídeos reais dos gerados. De forma incomum, cada par gerador–discriminador é treinado com uma estratégia de otimização diferente: RMSprop, Adam ou gradiente estocástico descendente. Essas “perdas” separadas incentivam cada estágio a se especializar: o primeiro constrói a estrutura básica, o segundo melhora a clareza e o sincronismo, e o terceiro foca em saber se o clipe realmente reflete a ação descrita. Ao tratar a criação dos quadros como um processo de decisão passo a passo, o modelo consegue manter melhor o movimento suave ao longo do tempo.
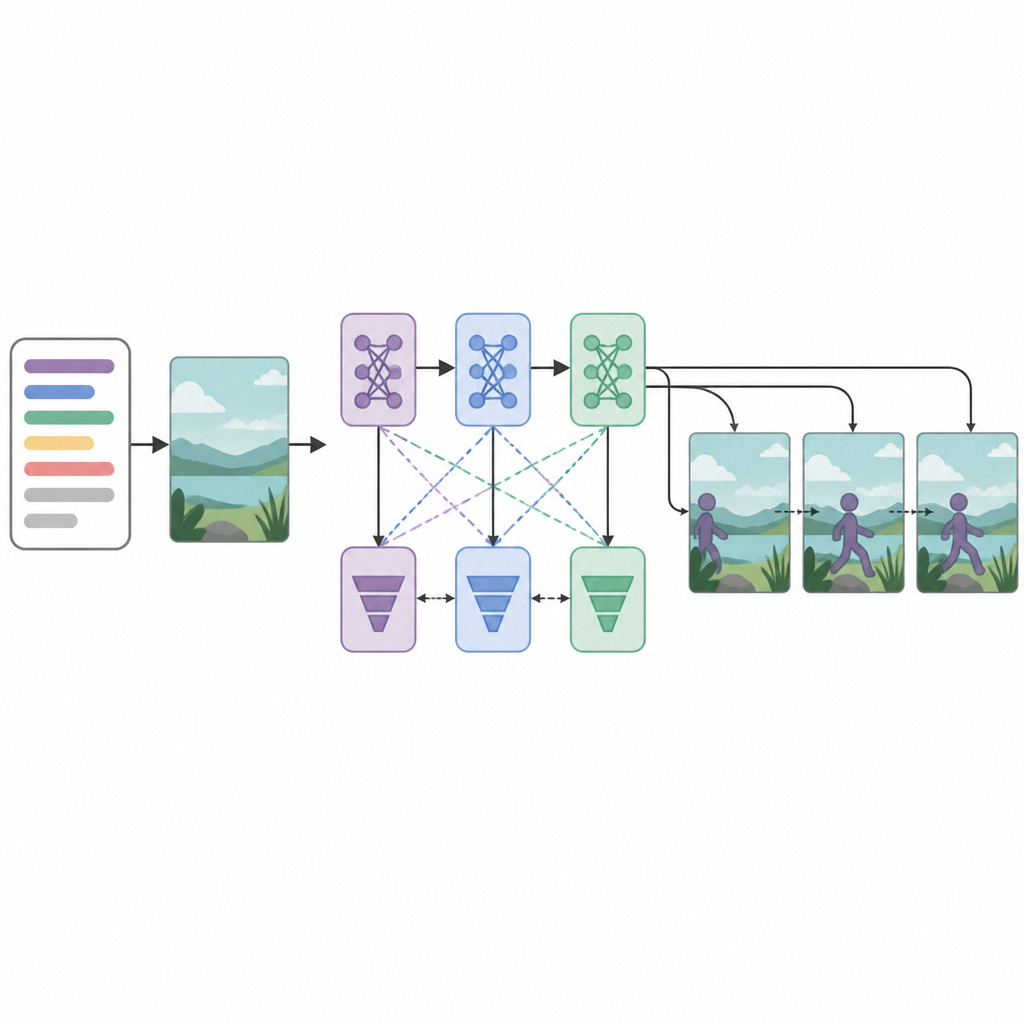
Como o sistema se sai
Os pesquisadores testaram seu método em três conjuntos de dados: um simples que mostra dígitos únicos quicando, e duas grandes coleções de ações humanas (KTH e UCF-101) cobrindo atividades como caminhar, correr, boxe e vários esportes. Eles usaram medidas conhecidas para avaliar o sucesso: o Inception Score para variedade e clareza dos quadros, Fréchet Video Distance para o quão próximos os clipes gerados estão dos reais, e CLIP-similarity para o quanto o conteúdo do vídeo corresponde ao texto. Nesses testes, o novo Seq-GAN superou consistentemente sistemas anteriores baseados em GANs e foi competitivo com modelos mais recentes de texto-para-vídeo, especialmente na manutenção de movimento coerente e na conservação do alinhamento entre conteúdo e descrição escrita.
Limites e o que vem a seguir
Apesar de suas qualidades, o método ainda tem dificuldades com cenas longas ou complexas, altas resoluções e textos muito detalhados envolvendo múltiplas pessoas ou objetos. À medida que o número de quadros ou o tamanho do vídeo cresce, pequenos defeitos e borrões podem surgir, e o sistema pode deixar passar partes mais sutis da descrição. Os autores sugerem trabalhos futuros que comparem sua abordagem mais diretamente com grandes modelos de vídeo baseados em difusão e explorem projetos híbridos que combinem a velocidade do treinamento adversarial com o alto nível de detalhe dos métodos de difusão.
O que isso significa para usuários comuns
Para não especialistas, a mensagem principal é que este trabalho nos aproxima de ferramentas em que prompts curtos em linguagem natural podem gerar clipes de vídeo curtos e críveis. Ao combinar compreensão de linguagem, um esboço visual rudimentar e várias etapas de controle de qualidade, a estrutura Seq-GAN proposta mostra que é possível gerar vídeos que não só parecem realistas, mas também permanecem em sintonia com o que pedimos, apontando para modos mais intuitivos de criar e editar histórias visuais no futuro.
Citação: Ullah, A., Xing, Z., Tasir, M.A.M. et al. Text-to-video generation with multi-loss sequential generative adversarial network. Sci Rep 16, 14966 (2026). https://doi.org/10.1038/s41598-026-45313-7
Palavras-chave: texto-para-vídeo, rede generativa adversarial, geração de vídeo, aprendizado profundo, coerência temporal