Clear Sky Science · he
יצירת טקסט לווידאו עם רשת אדברסארית סכמתית רצףית בעלת איבודי-רב
להפוך מילים לתמונות נעות
דמיינו שאתם מקלידים תיאור קצר כמו “אדם מרכיב ריצה בפארק” ומקבלים מיד קליפ וידאו קטן שמתאים לו. המחקר הזה עוסק בדיוק באתגר הזה: ללמד מחשבים להמיר שפה יומיומית לווידאו קצר ומציאותי שנשאר נאמן לטקסט ונראה חלק ממסגרת למסגרת. טכנולוגיה כזו יכולה להניע כלים חדשים בחינוך, בבידור, בעיצוב ובנגישות, אך קשה להוציא לפועל תוצאות שנראות גם אמינות וגם עקביות לאורך זמן.
מדוע וידאו קשה יותר מתמונות
לייצר תמונה יחידה מטקסט הוא כבר משימה מאתגרת, אך מערכות מודרניות מתמודדות איתה יחסית טוב. וידאו מעלה את הרף: כל פריים לא רק צריך להתאים לתיאור אלא גם להתאים לפריימים הסמוכים בזמן. אם הרקע משתנה בבת אחת או צורת האדם מעוותת בין פריימים, האשליה של התנועה מתפוררת. מאגרי וידאו ציבוריים מוסיפים עוד שכבת קושי כי הם מערבבים זוויות מצלמה, תנאי תאורה וסגנונות פעולה שונים. כתוצאה מכך, שיטות מוקדמות רבות הנפיקו סצינות מטושטשות, תנועות שבורות או וידאו שתואם באופן רופף בלבד לטקסט הקלט.
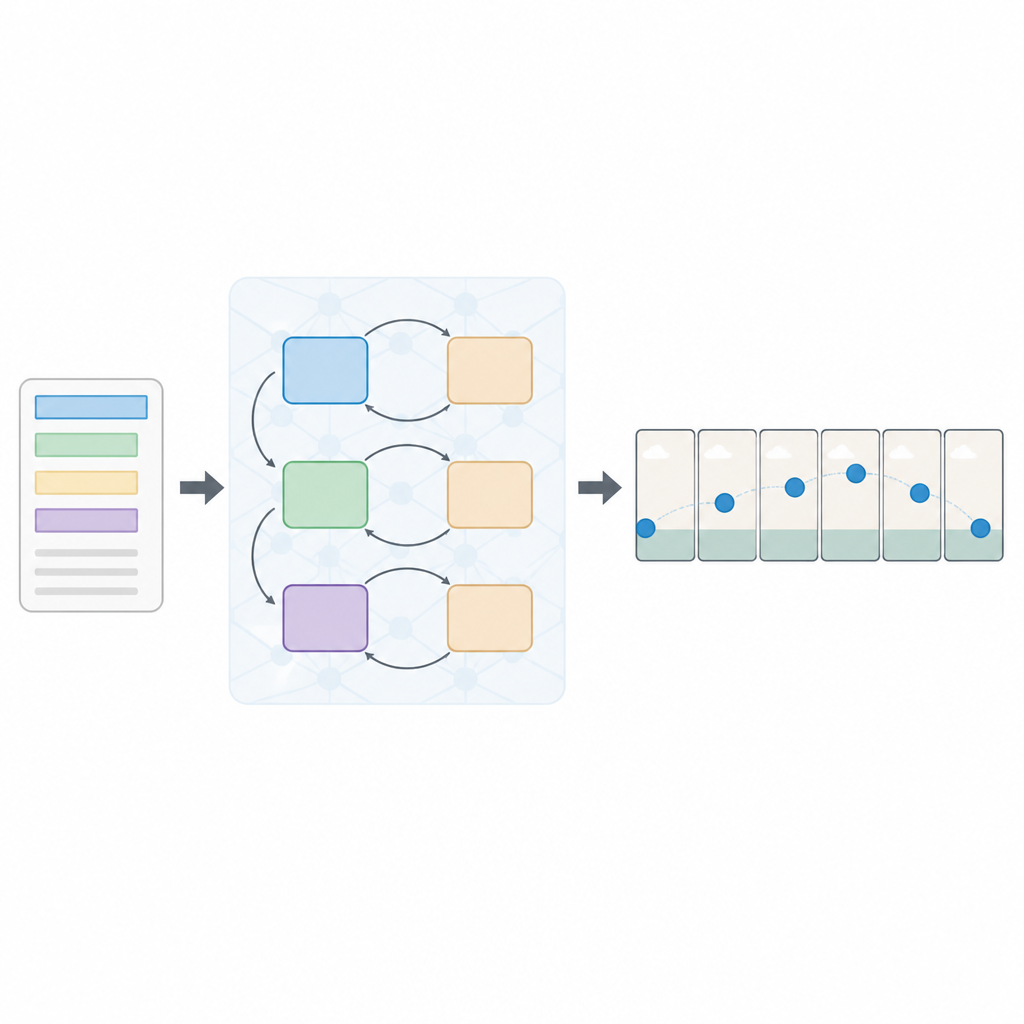
גישה שכבתית של קריאה וראייה
המחברים מציעים ארכיטקטורה חדשה הנקראת רשת אדברסארית רצףית רב-איבוד, או Seq-GAN בקיצור. ראשית, מקודד טקסט מבוסס LSTM קורא את המשפט מילה-מילה והופך אותו "לסיכום" מספרי קומפקטי שתופס את המשמעות. במקביל, авто-אנקודר ואריאציונלי מותאם בונה תמונת "גייסט" מהפריים הראשון, המתמקד בצבע והרכב הרקע הכללי במקום בפרטים עדינים. הגייסט הזה מתפקד כשרטוט גס של הסצנה, שמדריך מאוחר יותר את התנועה והמראה של פריימי הווידאו הסופיים.
ביקורות מרובות לתוצאות חדות יותר
בלב המערכת יושבים שלושה רשתות יוצר ושלושה רשתות מפלגות (דיסקרימינטור), מסודרות ברצף. כל יוצר מנסה ליצור פריימים שנראים מציאותיים ומתאימים לטקסט, בעוד שכל מפלג ניסה להבחין בין וידאו אמיתי לבין המיוצר. באופן לא שגרתי, כל זוג יוצר–מפלג מאומן עם אסטרטגיית אופטימיזציה שונה: RMSprop, Adam או ירידת גרדיאנט סטוכסטית. ה"איבודים" הנפרדים האלה מעודדים כל שלב להתמחות: הראשון בונה מבנה בסיסי, השני משפר בהירות ותזמון, והשלישי מתמקד בשאלה האם הקליפ משקף באמת את הפעולה המתוארת. באמצעות התייחסות ליצירת פריימים כתהליך החלטתי שלב־אחר־שלב, המודל שומר טוב יותר על תנועה חלקה לאורך זמן.
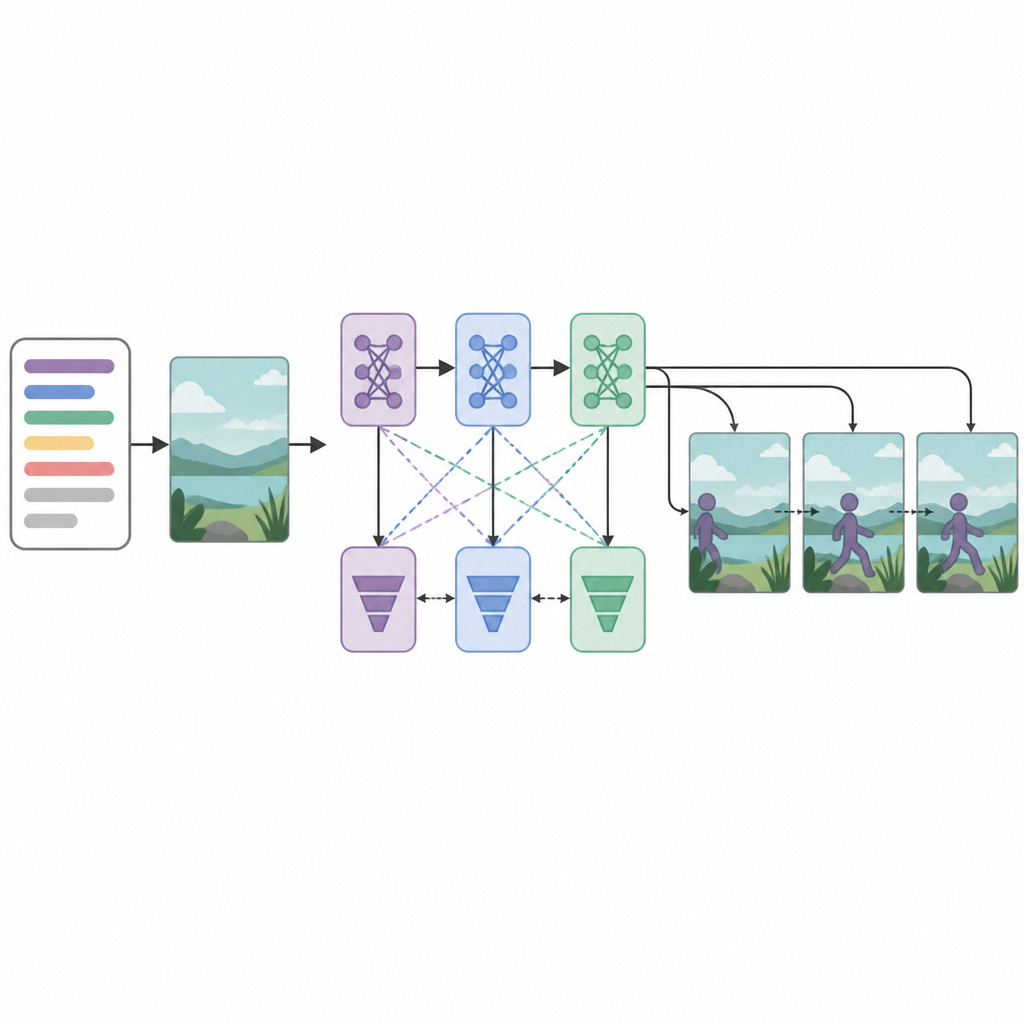
כמה המערכת מצליחה
החוקרים בחנו את השיטה על שלושה מאגרים: אחד פשוט המציג ספרות בודדות הקופצות סביב, ושני אוספים גדולים של פעולות אנושיות (KTH ו-UCF-101) המכסים פעילויות כמו הליכה, ריצה, איגרוף וספורט שונים. הם השתמשו במדדים ידועים להערכת ההצלחה: Inception Score לגיוון ובהירות הפריימים, Fréchet Video Distance לקרבה בין הקליפים המיוצרים לאמיתיים, ו-CLIP-similarity למדידת התאמת התוכן של הווידאו לטקסט. במרבית המבחנים, ה-Seq-GAN החדש גבר בעקביות על מערכות GAN מוקדמות והתמודד היטב מול דגמי טקסט-לווידאו עדכניים יותר, במיוחד בשמירה על תנועה קוהרנטית ובהתאמת התוכן לתיאור הכתוב.
מגבלות ומה הלאה
למרות חוזקותיו, השיטה עדיין מתקשה בסצנות ארוכות או מורכבות, ברזולוציות גבוהות ובטקסטים מפורטים מאוד הכוללים אנשים או אובייקטים מרובים. כאשר מספר הפריימים או גודל הווידאו גדלים, יכולים להופיע תקלות קטנות וטשטוש, והמערכת עלולה לפספס חלקים עדינים יותר של התיאור. המחברים מציעים עבודות עתידיות שיכללו השוואה ישירה יותר לגביי דגמי וידאו מבוססי דיפוזיה גדולים ובחינת תכנונים היברידיים המשלבים את המהירות של אימון אדברסארי עם רמת הפרטנות הגבוהה של שיטות דיפוזיה.
מה זה אומר למשתמשים יומיומיים
ללא-מומחים, המסר המרכזי הוא שהעבודה הזאת מקרבת אותנו לכלים שבהם בקשות קצרות בפשטות שפה יכולות להניע יצירה של קליפים וידאו קצרים ומשכנעים. באמצעות שילוב של הבנת שפה, שרטוט ויזואלי גס ורב שלבי בקרת איכות, מסגרת ה-Seq-GAN המוצעת מראה שאפשר ליצור וידאו שנראה לא רק מציאותי אלא גם נשאר מסונכרן עם מה שביקשנו, ומצביעה על דרכים אינטואיטיביות יותר ליצור ולערוך סיפורים חזותיים בעתיד.
ציטוט: Ullah, A., Xing, Z., Tasir, M.A.M. et al. Text-to-video generation with multi-loss sequential generative adversarial network. Sci Rep 16, 14966 (2026). https://doi.org/10.1038/s41598-026-45313-7
מילות מפתח: טקסט-לווידאו, רשת אדברסארית מחוללת, יצירת וידאו, למידה עמוקה, עקיבות זמנית