Clear Sky Science · sv
Text-till-video-generering med en sekventiell generativ adversariell nätverk med flera förluster
Att förvandla ord till rörliga bilder
Föreställ dig att du skriver en kort beskrivning som ”en person som joggar i en park” och direkt får en liten videosekvens som motsvarar den. Denna studie tar sig an just den utmaningen: att lära datorer att omvandla vardagsspråk till korta, realistiska videor som förblir trogna texten och ser jämna ut bildruta för bildruta. Sådan teknik kan driva nya verktyg för utbildning, underhållning, design och tillgänglighet, men det är förvånansvärt svårt att få resultaten att se både trovärdiga och temporalt konsekventa ut.
Varför video är svårare än bilder
Att generera en enda bild från text är redan svårt, men moderna system hanterar det ganska väl. Video höjer ribban: varje bildruta måste inte bara stämma med beskrivningen utan även med sina grannar över tiden. Om bakgrunden ändras plötsligt eller en persons form förvrängs mellan rutor, bryts illusionen av rörelse. Offentliga videodatamängder lägger till en extra svårighetsgrad eftersom de blandar olika kameravinklar, ljusförhållanden och rörelsestilar. Som en följd producerade många tidigare metoder suddiga scener, bruten rörelse eller videor som bara löst motsvarade inmatad text.
En lagerindelad metod för läsning och seende
Författarna föreslår en ny uppställning kallad ett multi-loss Sequential Generative Adversarial Network, eller Seq-GAN. Först läser en LSTM-baserad textkodare meningen ord för ord och omvandlar den till en kompakt numerisk ”sammanfattning” som fångar betydelsen. Parallellt bygger en modifierad variational autoencoder en ”gist”-bild från den första bilden, med fokus på övergripande bakgrundsfärg och layout snarare än fina detaljer. Denna gist fungerar som en grov skiss av scenen, som senare styr rörelsen och utseendet hos de slutliga bildrutorna i videon.
Flera kritiker för skarpare resultat
I systemets kärna sitter tre generatornätverk och tre discriminator- eller kritiker-nätverk ordnade i sekvens. Varje generator försöker skapa videorutor som ser realistiska ut och matchar texten, medan varje discriminator försöker skilja verkliga videor från de genererade. Ovanligt nog tränas varje generator–discriminator-par med en annan optimeringsstrategi: RMSprop, Adam eller stokastisk gradientnedstigning. Dessa separata ”förluster” uppmuntrar varje steg att specialisera sig: det första bygger grundstruktur, det andra förbättrar klarhet och timing, och det tredje fokuserar på om klippet verkligen återspeglar den beskrevna handlingen. Genom att behandla bildruteproduktion som en steg-för-steg-beslutsprocess kan modellen bättre bevara jämn rörelse över tid.
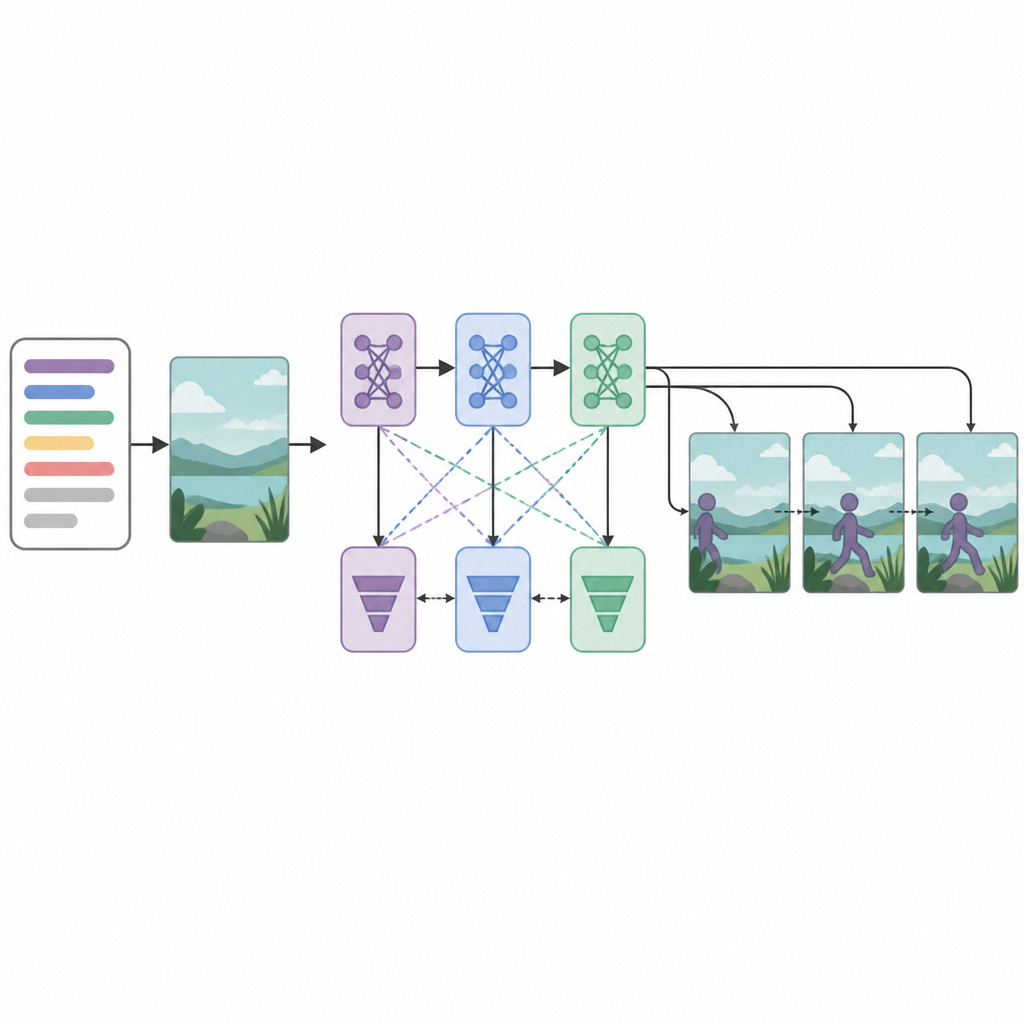
Hur väl systemet presterar
Forskarlaget testade sin metod på tre datamängder: en enkel som visar enskilda siffror som studsar runt, och två stora samlingar av människors handlingar (KTH och UCF-101) som täcker aktiviteter som att gå, springa, boxas och olika sporter. De använde väletablerade mått för att bedöma framgång: Inception Score för variation och klarhet i bildrutorna, Fréchet Video Distance för hur nära de genererade klippen liknar riktiga, och CLIP-similaritet för hur väl videoinnehållet matchar texten. I dessa tester överträffade den nya Seq-GAN konsekvent tidigare GAN-baserade system och var konkurrenskraftig med nyare text-till-video-modeller, särskilt vad gäller att bibehålla koherent rörelse och hålla innehållet i linje med den skrivna beskrivningen.
Begränsningar och vad som kommer härnäst
Trots sina styrkor har metoden fortfarande problem med långa eller komplexa scener, hög upplösning och mycket detaljerad text som involverar flera personer eller objekt. När antalet bildrutor eller videons storlek ökar kan små fel och oskärpa smyga sig in, och systemet kan missa mer subtila delar av beskrivningen. Författarna föreslår framtida arbete som jämför deras angreppssätt mer direkt med stora diffusionsbaserade videomodeller och utforskar hybriddesigner som blandar den adversariella träningens snabbhet med diffusionsmetoders höga detaljrikedom.
Vad detta innebär för vanliga användare
För icke-experter är huvudbudskapet att detta arbete för oss närmare verktyg där korta, vardagliga textpromptar kan driva skapandet av korta, trovärdiga videoklipp. Genom att kombinera språkförståelse, en grov visuell skiss och flera steg av kvalitetskontroll visar det föreslagna Seq-GAN-ramverket att det är möjligt att generera videor som inte bara ser realistiska ut utan också förblir i takt med vad vi bad om, vilket pekar mot mer intuitiva sätt att skapa och redigera visuella berättelser i framtiden.
Citering: Ullah, A., Xing, Z., Tasir, M.A.M. et al. Text-to-video generation with multi-loss sequential generative adversarial network. Sci Rep 16, 14966 (2026). https://doi.org/10.1038/s41598-026-45313-7
Nyckelord: text-till-video, generativt adversariellt nätverk, videogenerering, djupinlärning, temporal koherens