Clear Sky Science · ja
マルチロス逐次生成対抗ネットワークによるテキスト→動画生成
言葉を動く映像に変える
「公園をジョギングする人」のような短い記述を入力すると、それに合った小さな動画クリップが瞬時に得られると想像してみてください。本研究はまさにその課題に取り組み、日常の言葉を短く現実的な動画に変換し、テキストに忠実でフレーム間が滑らかに見えるようにコンピュータを訓練する方法を探ります。こうした技術は教育、エンターテインメント、デザイン、アクセシビリティの新しいツールを生み出す可能性がありますが、結果を信じられるものにし、時間的に一貫させるのは意外に難しいのです。
画像よりも難しい理由
テキストから単一の画像を生成すること自体も難しいですが、現代のシステムはかなりうまくこなしています。動画はハードルを上げます:各フレームは記述に合致するだけでなく、前後のフレームとも整合しなければなりません。背景が突然変わったり、人の形がフレーム間で歪んだりすると、動きの錯覚は壊れてしまいます。公開されている動画データセットは、カメラアングルや照明、動作のスタイルが混在しているためさらに難易度が上がります。その結果、以前の多くの手法はぼやけたシーン、途切れた動き、または入力テキストとしか大まかにしか一致しない動画を生むことがありました。
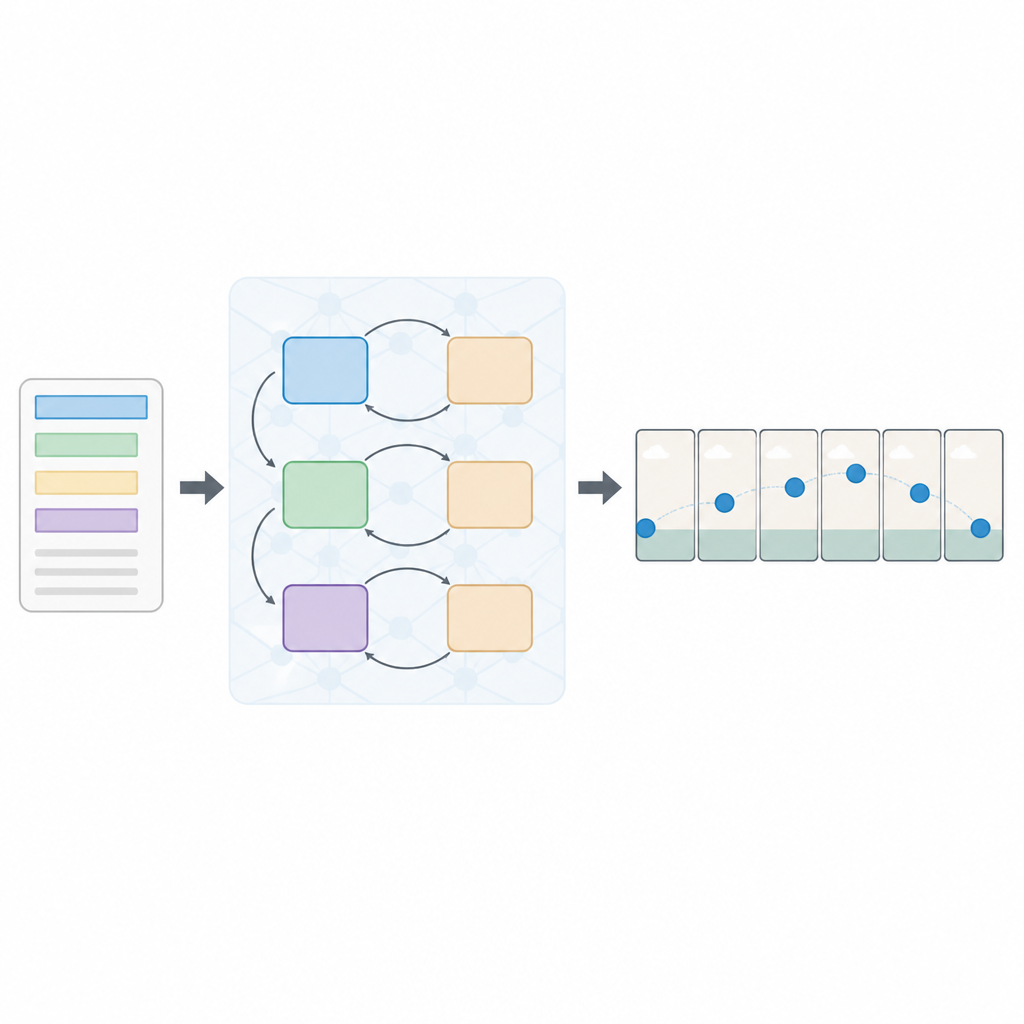
読み取りと視覚化の層状アプローチ
著者らはマルチロス逐次生成対抗ネットワーク、略してSeq-GANと呼ばれる新しい構成を提案します。まず、LSTMベースのテキストエンコーダが文を単語ごとに読み取り、意味を捉えたコンパクトな数値の「要約」に変換します。並行して、修正された変分オートエンコーダが最初のフレームから「概要」画像を構築し、細部ではなく全体的な背景色やレイアウトに焦点を当てます。この概要はシーンの大まかなスケッチのように働き、最終的な動画フレームの動きや外観を導きます。
より鮮明な結果のための複数の批評者
システムの中心には、逐次に配置された3つの生成器ネットワークと3つの識別器(批評者)ネットワークがあります。各生成器はリアルでテキストに合った動画フレームを作ろうとし、各識別器は生成されたものと実際の動画を見分けようとします。異例なのは、すべての生成器–識別器ペアが異なる最適化戦略(RMSprop、Adam、確率的勾配降下法)で訓練される点です。これらの個別の「ロス」は各段階の専門化を促し、最初の段階は基本構造を構築し、二番目は明瞭さとタイミングを高め、三番目はクリップが記述された動作を本当に反映しているかに焦点を当てます。フレーム生成を段階的な意思決定プロセスとして扱うことで、時間を通した滑らかな動きをより維持できます。
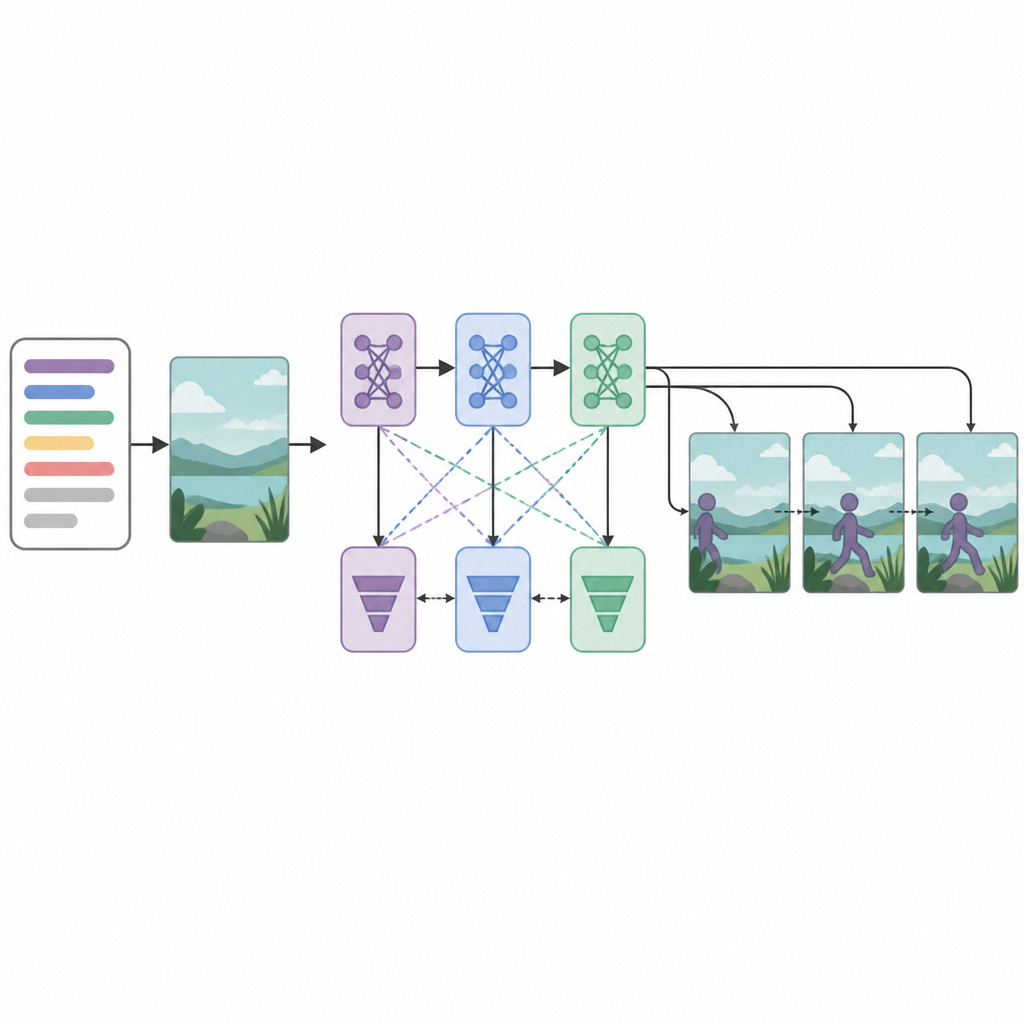
システムの性能
研究者らは、この手法を3つのデータセットで評価しました:1つは単純に数字が跳ね回る様子を示す小さなもの、残り2つは歩行、走行、ボクシングや各種スポーツなどの人間の動作を含む大規模なコレクション(KTH と UCF-101)です。評価にはよく知られた指標を用いました:フレームの多様性と鮮明さを測るInception Score、生成クリップが実物にどれだけ近いかを測るFréchet Video Distance、そして映像内容がテキストとどれだけ一致するかを測るCLIP類似度です。これらのテスト全体で、新しいSeq-GANは従来のGANベース手法を一貫して上回り、特に一貫した動きの維持とテキストとの整合性において、最近のテキスト→動画モデルと競合する結果を示しました。
限界と今後の展望
強みはあるものの、この手法は長尺や複雑なシーン、高解像度、複数の人物や物体を含む詳細なテキストには依然として苦戦します。フレーム数や動画サイズが増えると小さな不具合やぼやけが入り込みやすく、微妙な記述を見落とすことがあります。著者らは、より大規模な拡散ベースの動画モデルと直接比較する研究や、敵対的学習の速さと拡散法の高いディテールを組み合わせたハイブリッド設計の検討を今後の課題として挙げています。
一般ユーザーにとっての意味
非専門家向けの重要なメッセージは、本研究が短く自然な言葉のプロンプトで短い信じられる動画クリップを作れるツールに近づけたことです。言語理解、大まかな視覚スケッチ、複数段階の品質管理を組み合わせることで、提案されたSeq-GANフレームワークは、見た目がリアルでなおかつ要求した内容と同期した動画を生成できる可能性を示しており、将来的に視覚ストーリーを直感的に作成・編集する新たな手段を指し示しています。
引用: Ullah, A., Xing, Z., Tasir, M.A.M. et al. Text-to-video generation with multi-loss sequential generative adversarial network. Sci Rep 16, 14966 (2026). https://doi.org/10.1038/s41598-026-45313-7
キーワード: テキストから動画へ, 生成的敵対ネットワーク, 動画生成, ディープラーニング, 時間的一貫性