Clear Sky Science · zh
基于伪深度的深度神经网络目标检测模型
让相机“懂得深度”为何重要
现代相机和手机应用在识别人、车辆及其他物体方面越来越成熟,但它们主要还是只看平面的彩色图像。本文提出了一个简单却影响深远的问题:如果我们能够在不增加额外传感器或昂贵硬件的情况下,赋予普通相机一种深度感(即粗略的三维信息),会怎样?作者通过从单张照片“伪造”出深度视图并将其输入现有 AI 系统,证明了在日常场景中目标检测的精度可以显著提高。
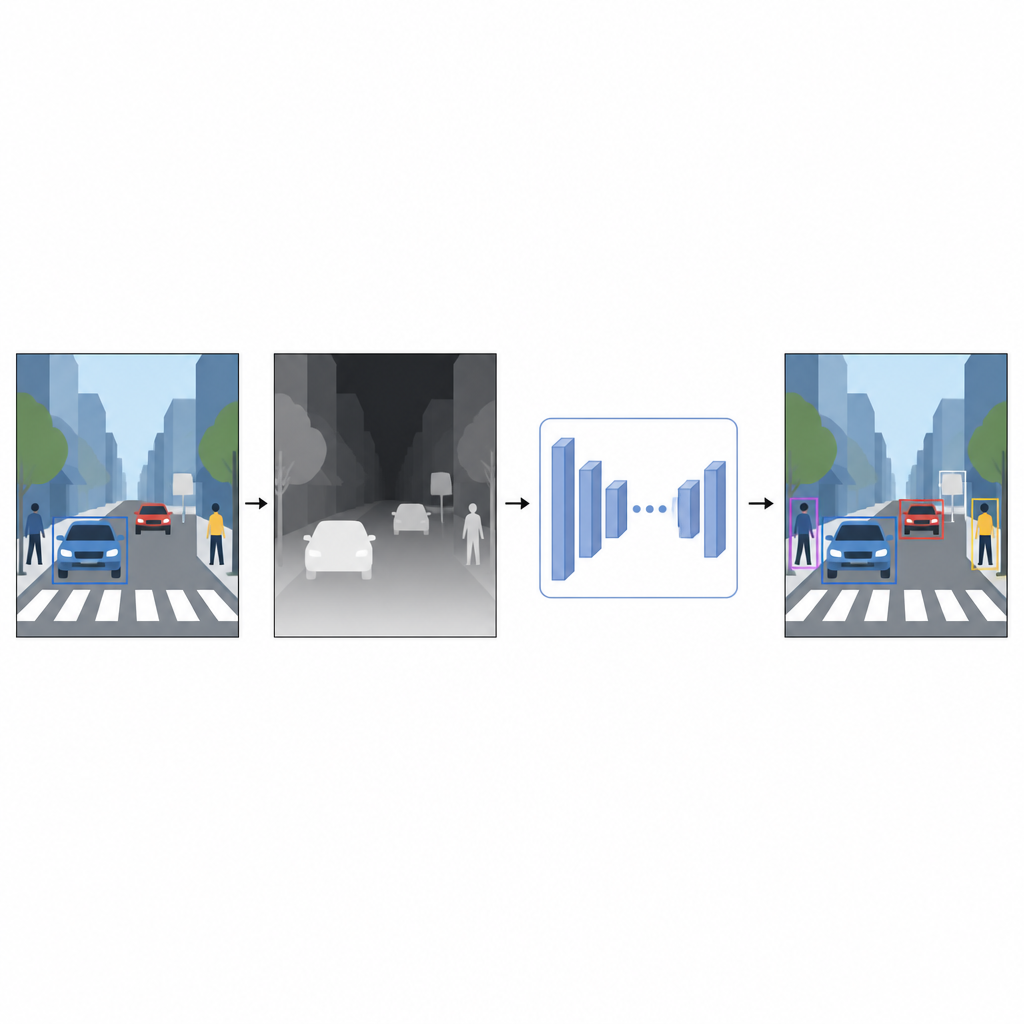
从平面图片到距离感
日常照片记录颜色与纹理,但不记录物体有多远。对于计算机来说,当红色汽车和红色墙面在二维图片中重叠时,可能会产生混淆。即便是近似的深度信息也能帮助将前景与背景分离,明确物体边界。作者没有依赖激光扫描仪或双目相机等特殊设备,而是使用了一种称为单目深度估计的技术。一个独立的 AI 模型从单张彩色图像预测出稠密深度图——一种每个像素都表示场景中该点远近程度的灰度图案。
由软件构成的虚拟深度传感器
为生成这些伪深度图,研究使用了一个在两阶段训练下的先进深度估计网络。首先,网络在大量合成场景上学习,因为合成数据中可以轻松获得完美深度。然后在通过强教师模型自动标注的真实图像上进一步微调。这样的训练策略使深度网络能应对棘手情况,包括低光照、玻璃等透明物体以及杆状或椅腿等细小结构。得到的伪深度图提供了平滑的像素级场景形状提示,能够补充原始彩色照片的信息。
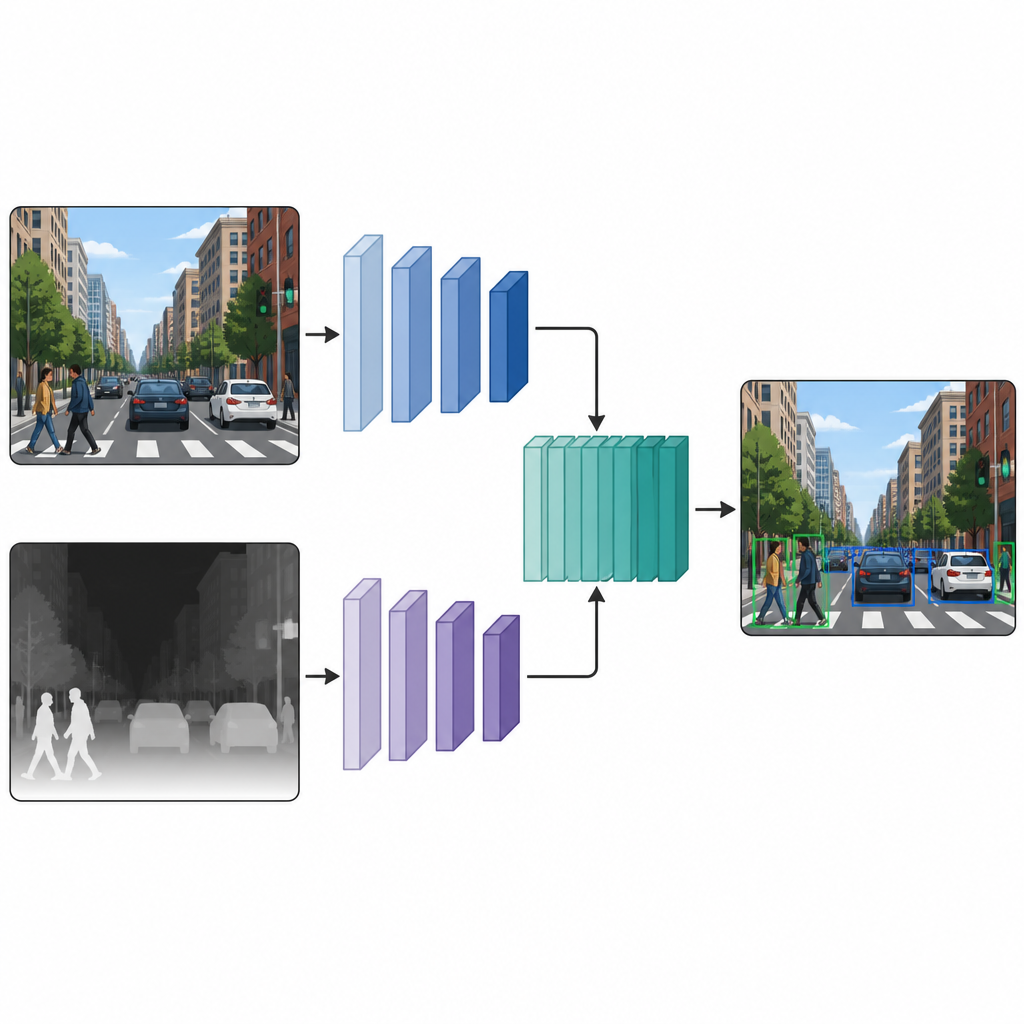
两条并行视图协同工作
在每张图像同时拥有彩色版本和伪深度版本后,作者将它们送入一个双分支的检测网络。一个分支处理常规彩色图像,另一个分支处理深度图,两条路径都采用相同风格的神经网络骨干。在若干中间层,来自两条分支的特征图会被拼接并进一步精炼。这种中期融合让模型既保留颜色线索与深度线索各自的特性,又能学习它们之间的交互。融合后的特征随后输入标准的检测头,输出场景中物体的边框和标签。
在真实场景中的实验结果
团队在两个知名图像集合上测试了他们的方法。其一为 COCO,包含拥挤的日常人物、动物和物品照片;另一个 M3FD 聚焦道路场景,使用可见光和红外相机。跨越包括轻量级 YOLO 版本和基于变换器的检测器在内的多种流行检测模型,加入伪深度特征均能持续提升精度。在 COCO 上,用于衡量正确检测的主评分最高提高了约八个百分点,而在 M3FD 上则见到更为稳健但幅度较小的提升。可视化示例显示了更清晰的物体轮廓、夜间场景中更少漏检的路灯,以及在光线差时更好地将人物与杂乱背景区分开来。
无需额外硬件即可更清晰的视野
给读者的核心信息是:即便只有单张照片,赋予 AI 粗略的距离感也能使其对世界的理解更准确。通过在软件中生成深度图并在神经网络内部将其与常规彩色图像结合,这种方法帮助检测器在不增加新传感器或更换相机的情况下更可靠地发现物体。该方法可以作为简单的附加模块接入许多现有模型,以付出适度计算开销换取在复杂真实场景中显著更好的性能。
引用: Li, SQ., Feng, W., Liu, B. et al. Pseudo-depth-based deep neural network model for object detection. Sci Rep 16, 15120 (2026). https://doi.org/10.1038/s41598-026-45310-w
关键词: 目标检测, 深度估计, 计算机视觉, 伪深度, RGB 图像