Clear Sky Science · de
Pseudo-Tiefen-basierter Deep-Neural-Network-Ansatz zur Objekterkennung
Warum es wichtig ist, Kameras Tiefenwissen beizubringen
Moderne Kameras und Smartphone-Apps werden immer besser darin, Menschen, Autos und andere Objekte zu erkennen, betrachten dabei aber meist nur flache Farbbilder. Diese Arbeit stellt eine einfache Frage mit großer Wirkung: Was wäre, wenn wir gewöhnlichen Kameras ein Gefühl für Tiefe geben könnten, quasi ein grobes 3D-Verständnis, ohne zusätzliche Sensoren oder teure Hardware? Indem man aus einem einzelnen Foto eine simulierte Tiefenansicht erzeugt und sie in bestehende KI-Systeme einspeist, zeigen die Autoren, dass die Objekterkennung in Alltagsszenen deutlich genauer werden kann.
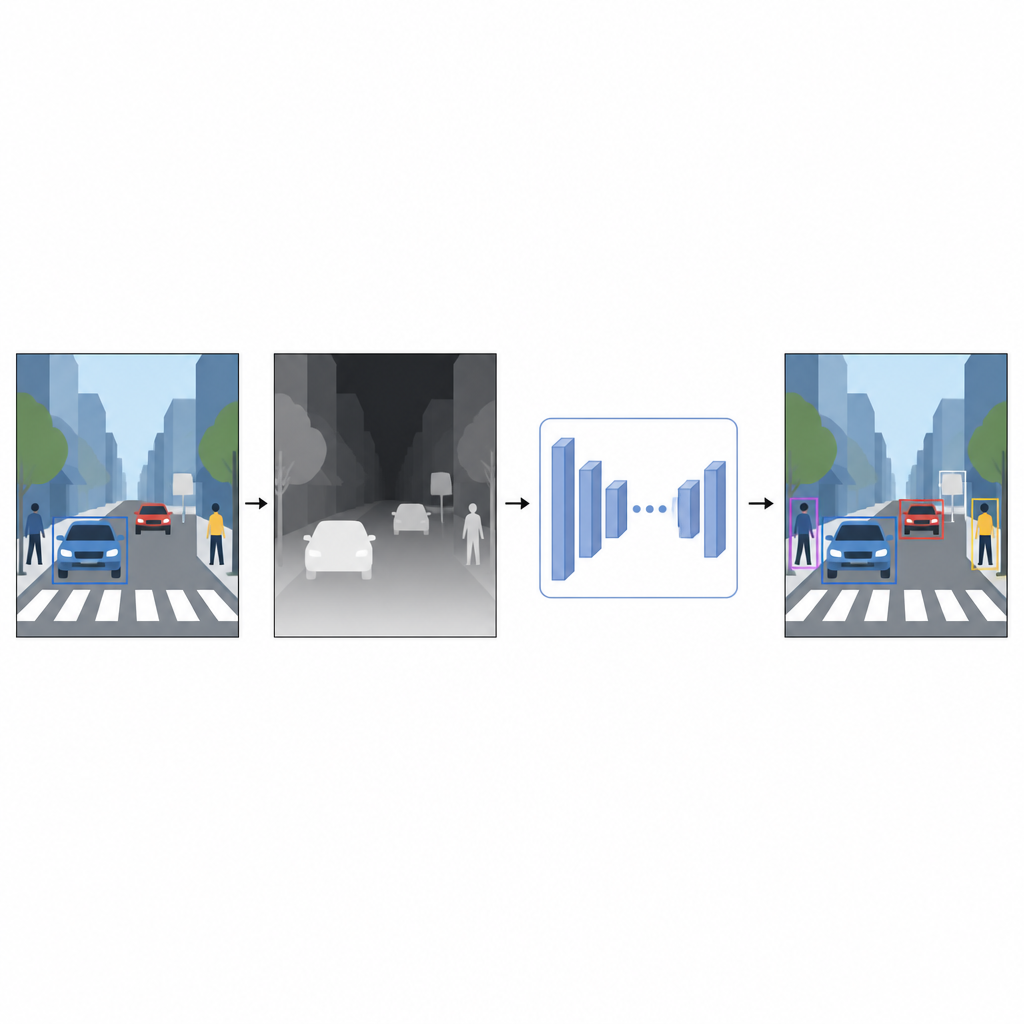
Von flachen Bildern zu einem Gefühl für Entfernung
Alltägliche Fotografien erfassen Farbe und Textur, nicht jedoch die Entfernung von Objekten. Für einen Computer können sich ein hellrotes Auto und eine rote Wand im zweidimensionalen Bild verwirrend ähnlich sehen, wenn sie sich überlappen. Tiefeninformationen, selbst wenn sie nur ungefähre sind, helfen, Vorder- und Hintergrund zu trennen und Objektgrenzen zu klären. Anstatt auf spezielle Geräte wie Laserscanner oder Stereo-Kamerakonfigurationen zu setzen, nutzen die Autoren eine Technik namens monokulare Tiefenschätzung. Ein separates KI-Modell nimmt ein einzelnes Farbbild und sagt eine dichte Tiefenkarte vorher, ein Graubild, in dem jedes Pixel andeutet, wie nah oder fern der entsprechende Punkt in der Szene sein könnte.
Ein virtueller Tiefensensor aus Software
Zur Erzeugung dieser Pseudo-Tiefenkarten verwendet die Studie ein modernes Tiefenschätzungsnetzwerk, das in zwei Stufen trainiert wird. Zuerst lernt es aus großen Sammlungen synthetischer Szenen, bei denen perfekte Tiefen leicht verfügbar sind. Dann verfeinert es seine Fähigkeiten an realen Bildern, die mithilfe eines starken Lehrermodells automatisch etikettiert wurden. Diese Trainingsstrategie ermöglicht es dem Tiefennetzwerk, mit schwierigen Situationen umzugehen, darunter schwaches Licht, transparente Objekte wie Glas und dünne Strukturen wie Pfosten oder Stuhlbeine. Die resultierenden Pseudo-Tiefenkarten liefern glatte, pixelgenaue Hinweise zur Form der Szene, die das ursprüngliche Farbphoto ergänzen.
Zwei parallele Ansichten, die zusammenwirken
Sobald jedes Bild sowohl eine Farbversion als auch eine Pseudo-Tiefenversion hat, führen die Autoren beides in ein dual-zweigiges Erkennungsnetzwerk ein. Ein Zweig verarbeitet das übliche Farbbild, der andere verarbeitet die Tiefenkarte und verwendet in beiden Pfaden denselben Stil des neuronalen Netzwerk-Backbones. In mehreren Zwischenebenen werden die Merkmalskarten beider Zweige zusammengeführt und weiter verfeinert. Diese Fusion in der Mitte erlaubt dem Modell, Besonderheiten der Farb- und der Tiefenhinweise zu bewahren und zugleich zu lernen, wie sie interagieren. Die verschmolzenen Merkmale gelangen dann in einen standardmäßigen Erkennungs-Head, der für die Objekte in der Szene Boxen und Labels ausgibt.
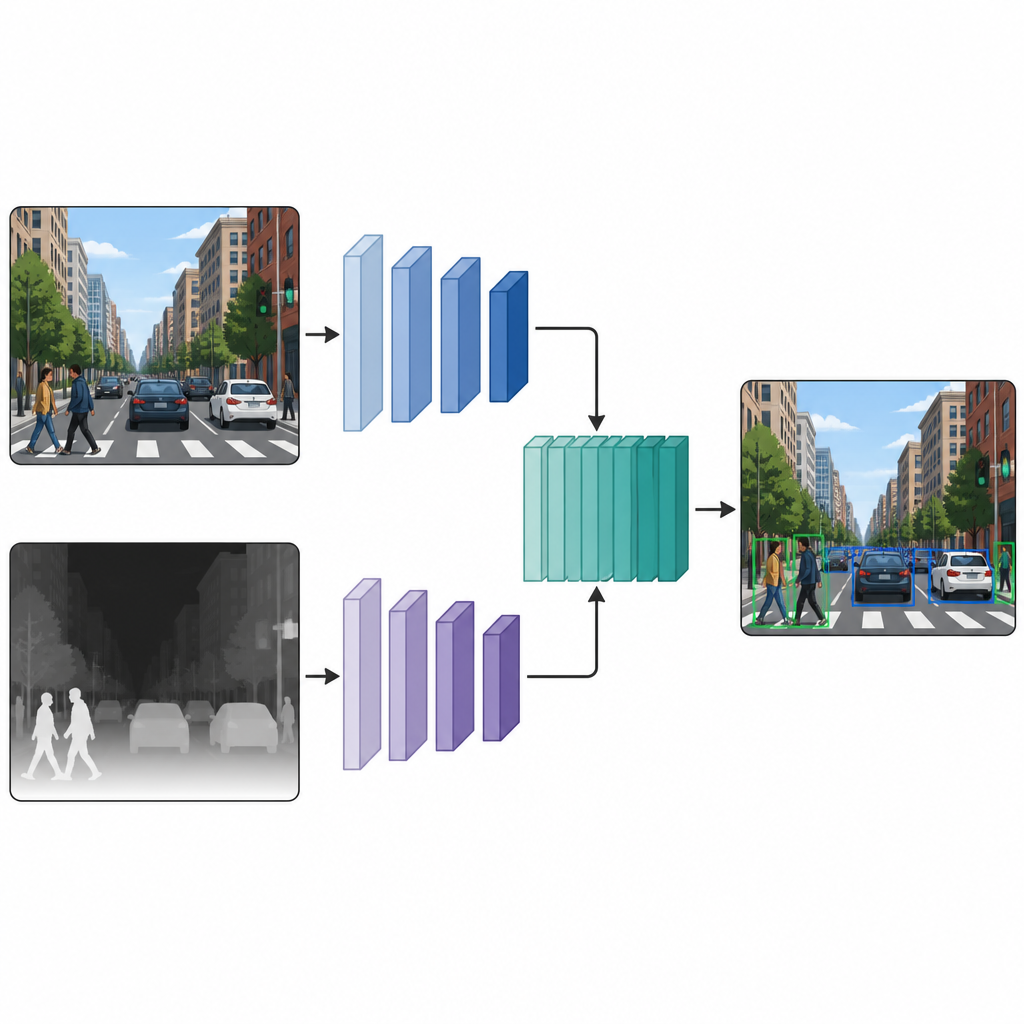
Was die Experimente in realen Szenen zeigen
Das Team testet seinen Ansatz an zwei bekannten Bildsammlungen. Die eine, genannt COCO, enthält überfüllte Alltagsfotos von Menschen, Tieren und Gegenständen. Die andere, M3FD, konzentriert sich auf Straßenszenen, in denen sowohl sichtbare als auch Infrarotkameras eingesetzt werden. Über mehrere populäre Erkennungsmodelle hinweg, einschließlich leichter Versionen von YOLO und einem transformatorbasierten Detektor, steigert das Hinzufügen von Pseudo-Tiefenmerkmalen konstant die Genauigkeit. Auf COCO verbessert sich die Hauptmetrik für korrekte Erkennungen um bis zu acht Prozentpunkte, während M3FD moderatere, aber beständige Zuwächse zeigt. Visuelle Beispiele zeigen klarere Objektkonturen, weniger übersehene Straßenlaternen in Nachtszenen und bessere Trennung von Personen vom unruhigen Hintergrund, besonders bei schlechtem Licht.
Klareres Sehen ganz ohne zusätzliche Hardware
Die Kernbotschaft für Leser ist, dass ein grobes Entfernungsgefühl, selbst aus nur einem Foto, das Verständnis einer KI von der Welt schärfen kann. Durch das Erzeugen von Tiefenkarten in Software und deren Kombination mit normalen Farbbildern innerhalb des neuronalen Netzes hilft diese Methode Detektoren, Objekte zuverlässiger zu finden, ohne neue Sensoren oder Veränderungen an der Kamera. Der Ansatz lässt sich als einfaches Add-on in viele bestehende Modelle einbinden und tauscht einen moderaten Anstieg des Rechenaufwands gegen spürbar bessere Leistung in komplexen, realen Szenen.
Zitation: Li, SQ., Feng, W., Liu, B. et al. Pseudo-depth-based deep neural network model for object detection. Sci Rep 16, 15120 (2026). https://doi.org/10.1038/s41598-026-45310-w
Schlüsselwörter: Objekterkennung, Tiefenschätzung, Computer Vision, Pseudo-Tiefe, RGB-Bilder