Clear Sky Science · ar
نموذج شبكة عصبية عميقة قائم على العمق الزائف لكشف الأشياء
لماذا يهم تعليم الكاميرات حول العمق
تحسنت الكاميرات وتطبيقات الهواتف الحديثة في تمييز الأشخاص والسيارات والأشياء الأخرى، لكنها في الغالب تنظر فقط إلى الصور اللونية المسطحة. تطرح هذه الورقة سؤالاً بسيطاً ذو أثر كبير: ماذا لو استطعنا أن نمنح الكاميرات العادية إحساساً بالعمق، كإحساس ثلاثي الأبعاد تقريبي، دون إضافة حسّاسات إضافية أو أجهزة مكلفة؟ من خلال توليد عرض عمق مُزيَّف من صورة واحدة وإدخاله إلى أنظمة الذكاء الاصطناعي الحالية، يبين المؤلفون أن اكتشاف الأشياء يمكن أن يصبح أكثر دقة بشكل ملحوظ في المشاهد اليومية.
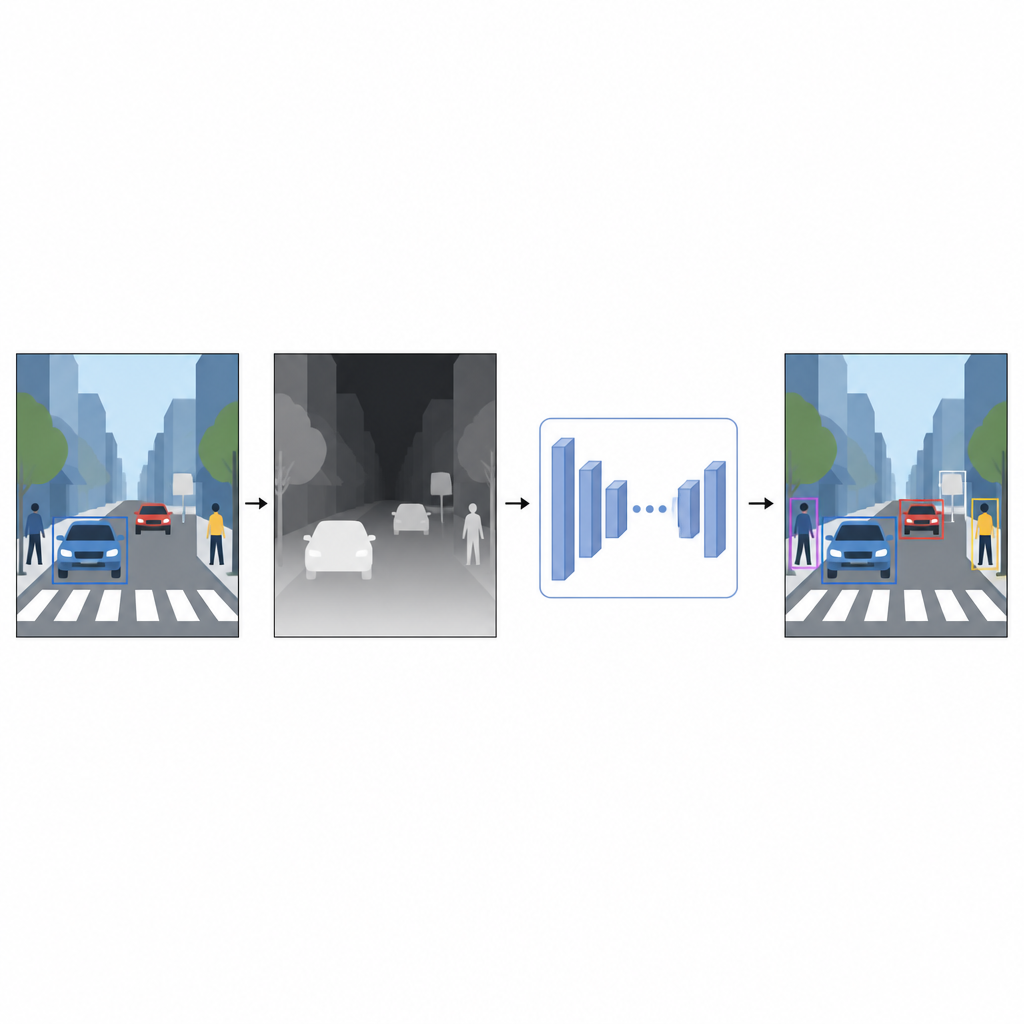
من الصور المسطحة إلى إحساس بالمسافة
تسجل الصور اليومية الألوان والملمس لكنها لا تسجل المسافة إلى الأشياء. بالنسبة للحاسوب، يمكن أن تبدو سيارة حمراء لامعة وجدار أحمر متشابهان بشكل مربك عندما يتراكبان في صورة ثنائية الأبعاد. تساعد معلومات العمق، حتى لو كانت تقريبية، على فصل المقدّمة عن الخلفية وتوضيح حدود الأشياء. بدلاً من الاعتماد على أجهزة متخصصة مثل الماسحات الليزرية أو أنظمة الكاميرات ستيريو، يستخدم المؤلفون تقنية تسمى تقدير العمق أحادي العين (monocular depth estimation). يأخذ نموذج ذكاء اصطناعي منفصل صورة لونية واحدة ويتنبأ بخريطة عمق كثيفة، نمط رمادي يقترح لكل بكسل مدى قرب أو بعد تلك النقطة في المشهد.
حسّاس عمق افتراضي مصنوع برمجياً
لإنتاج هذه الخرائط الزائفة للعمق، يستخدم البحث شبكة تقدير عمق متطورة تُدرَّب على مرحلتين. أولاً، تتعلم من مجموعات كبيرة من المشاهد الاصطناعية حيث يكون الحصول على عمق مثالي سهلاً. ثم تُحسّن مهاراتها على صور حقيقية تمت وسماً تلقائياً باستخدام نموذج قوي كمعلم. تتيح هذه الاستراتيجية التدريبية لشبكة العمق التعامل مع المواقف المعقدة، بما في ذلك الإضاءة المنخفضة، والأشياء الشفافة مثل الزجاج، والهياكل الرفيعة مثل الأعمدة أو أرجل الكراسي. توفر خرائط العمق الزائفة الناتجة تلميحات ناعمة عند مستوى البكسل حول شكل المشهد تُكمل الصورة اللونية الأصلية.
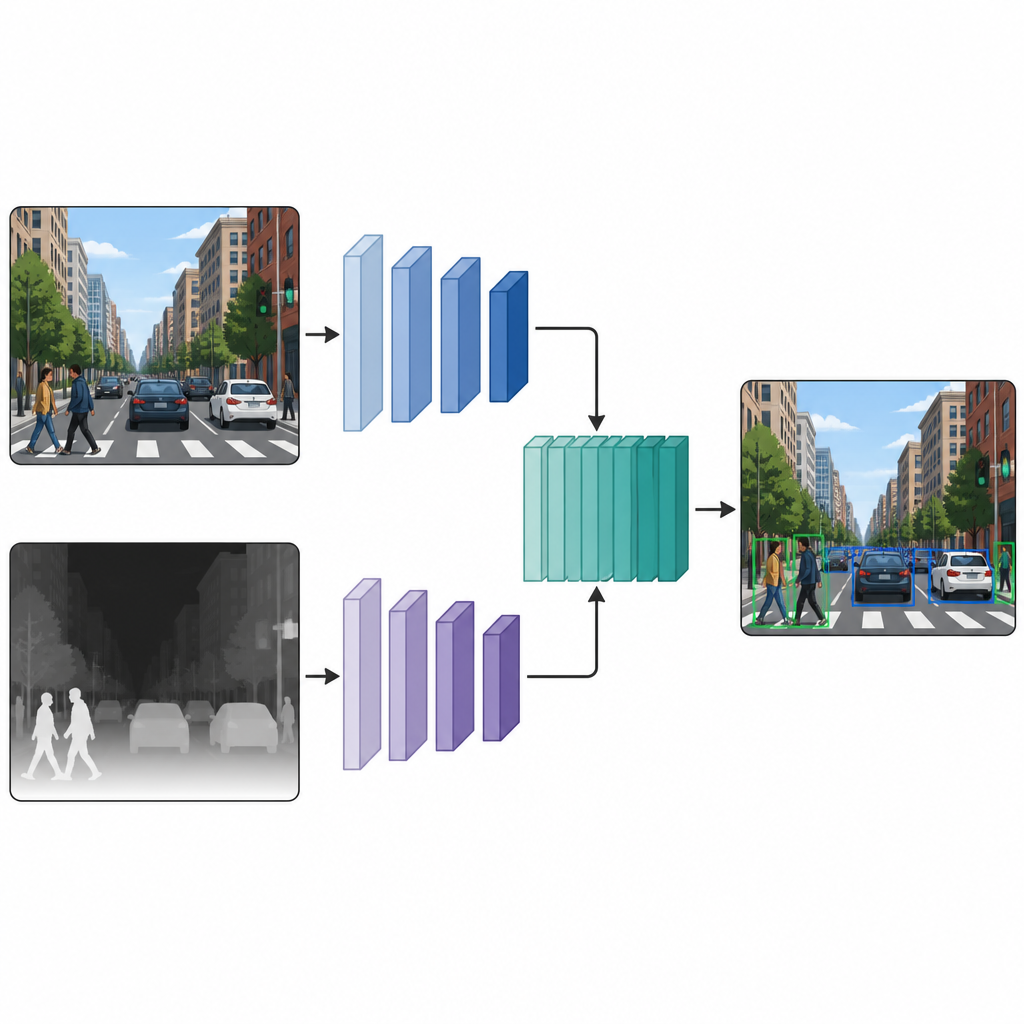
رؤيتان متوازيتان تعملان معاً
بمجرد أن تحتوي كل صورة على نسخة لونية ونسخة عمق زائفة، يزوّد المؤلفون الشبكة بكليهما عبر فرعين مزدوجين للكشف. يعالج أحد الفروع الصورة اللونية الاعتيادية، بينما يعالج الفرع الآخر خريطة العمق، مستخدماً نفس نوع بنية الشبكة العصبية الأساسية في المسارين. في عدة طبقات وسطية، تُدَمَج خرائط الميزات من الفرعين معاً وتُصَقَّل أكثر. تتيح عملية الدمج هذه في منتصف الشبكة للنموذج الاحتفاظ بما يميّز دلائل الألوان ودلائل العمق، وفي الوقت نفسه تعلّم كيفية تفاعلها. ثم تنتقل الميزات المدموجة إلى رأس كشف قياسي يُخرِج مربعات وتسميات للأشياء في المشهد.
ما تكشفه التجارب في المشاهد الحقيقية
اختبر الفريق منهجه على مجموعتين معروفتين من الصور. الأولى، المسماة COCO، تحتوي صوراً يومية مزدحمة لأشخاص وحيوانات وأشياء. والثانية، M3FD، تركّز على مشاهد الطريق حيث تُستخدم كاميرات مرئية وتحت الحمراء. عبر عدة نماذج كشف شائعة، بما في ذلك نسخ خفيفة من YOLO وكاشف يعتمد على المحولات (transformer)، تعزز إضافة ميزات العمق الزائف الدقة باستمرار. على مجموعة COCO، يتحسن المقياس الرئيسي الذي يقيس الكشف الصحيح بما يصل إلى ثمانية نقاط مئوية، بينما تشهد M3FD زيادات أكثر تواضعاً لكن ثابتة. تُظهر الأمثلة المرئية حدوداً أوضح للأشياء، وعدداً أقل من أعمدة الإنارة المفقودة في مشاهد الليل، وفصل أفضل للأشخاص عن الخلفيات المزدحمة، خاصة عند ضعف الإضاءة.
رؤية أوضح دون أجهزة إضافية
الرسالة الأساسية للقُرّاء هي أن منح الذكاء الاصطناعي إحساساً تقريبياً بالمسافة، حتى عندما يقتصر على صورة واحدة، يمكن أن يجعل فهمه للعالم أكثر حدة. من خلال إنشاء خرائط عمق برمجياً ودمجها مع الصور اللونية داخل الشبكة العصبية، تساعد هذه الطريقة الكواشف على العثور على الأشياء بشكل أكثر موثوقية دون إضافة حسّاسات جديدة أو تغيير الكاميرا. يمكن توصيل النهج بالعديد من النماذج القائمة كإضافة بسيطة، مقابل زيادة معتدلة في الحسابات للحصول على أداء أفضل ملحوظ في المشاهد الواقعية المعقدة.
الاستشهاد: Li, SQ., Feng, W., Liu, B. et al. Pseudo-depth-based deep neural network model for object detection. Sci Rep 16, 15120 (2026). https://doi.org/10.1038/s41598-026-45310-w
الكلمات المفتاحية: كشف الأشياء, تقدير العمق, رؤية حاسوبية, العمق الزائف, صور RGB