Clear Sky Science · it
Modello di rete neurale profonda basato su pseudo-profondità per il rilevamento degli oggetti
Perché insegnare alle fotocamere a conoscere la profondità è importante
Le fotocamere moderne e le app per smartphone stanno migliorando nello individuare persone, automobili e altri oggetti, eppure osservano prevalentemente immagini bidimensionali a colori. Questo articolo pone una domanda semplice ma dall’impatto significativo: cosa succederebbe se potessimo dare alle fotocamere ordinarie un senso della profondità, una percezione 3D approssimativa, senza aggiungere sensori extra o hardware costoso? Generando artificialmente una vista di profondità a partire da una singola foto e fornendola ai sistemi di IA esistenti, gli autori mostrano che il rilevamento degli oggetti può diventare nettamente più accurato nelle scene di tutti i giorni.
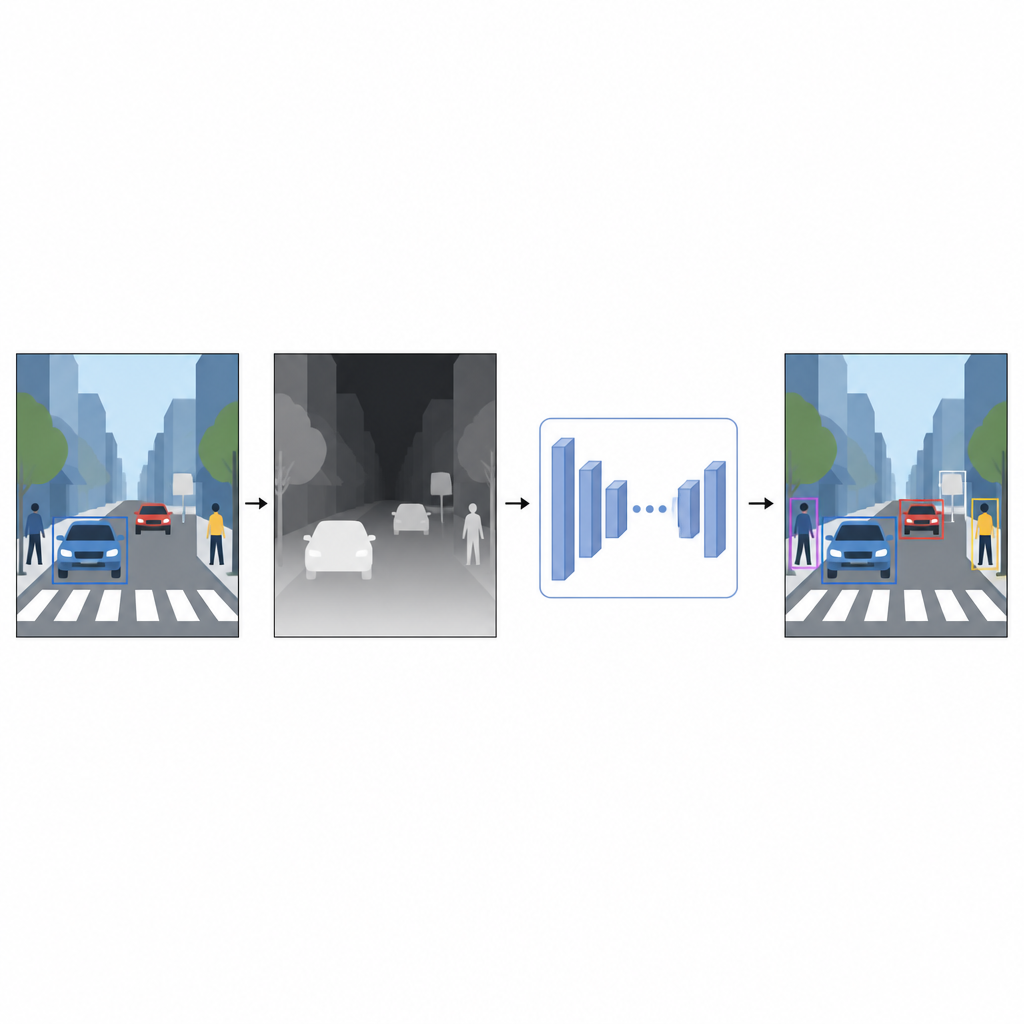
Dalle immagini piatte a una sensazione di distanza
Le fotografie quotidiane registrano colore e texture ma non quanto siano lontani gli oggetti. Per un computer, una macchina rossa brillante e un muro rosso possono sembrare confusamente simili quando si sovrappongono in un’immagine 2D. L’informazione di profondità, anche se approssimativa, aiuta a separare primo piano e sfondo e chiarisce i contorni degli oggetti. Invece di affidarsi a dispositivi speciali come scanner laser o sistemi stereo di telecamere, gli autori utilizzano una tecnica chiamata stima monoculare della profondità. Un modello di IA separato prende una singola immagine a colori e predice una mappa di profondità densa, un motivo in scala di grigi in cui ogni pixel suggerisce quanto vicino o lontano possa essere quel punto della scena.
Un sensore di profondità virtuale fatto in software
Per generare queste mappe di pseudo-profondità, lo studio impiega una rete di stima della profondità all’avanguardia addestrata in due fasi. Prima apprende da ampie raccolte di scene sintetiche, dove la profondità perfetta è facile da ottenere. Poi affina le proprie capacità su immagini reali che sono state etichettate automaticamente usando un modello insegnante potente. Questa strategia di addestramento consente alla rete di profondità di gestire situazioni complesse, inclusa scarsa illuminazione, oggetti trasparenti come il vetro e strutture sottili come pali o gambe di sedie. Le mappe di pseudo-profondità risultanti forniscono suggerimenti lisci a livello di pixel sulla forma della scena che completano la foto a colori originale.
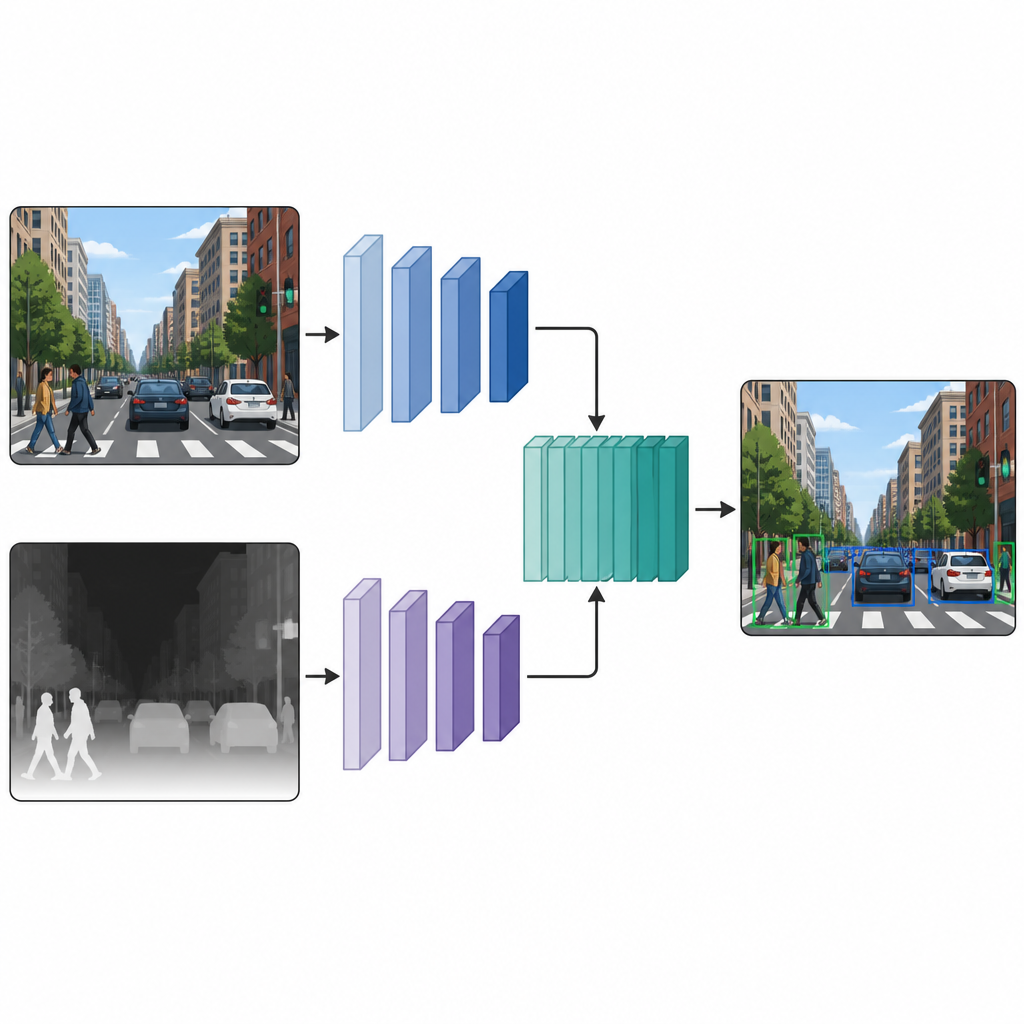
Due viste parallele che lavorano insieme
Una volta che ogni immagine dispone sia di una versione a colori sia di una versione pseudo-profondità, gli autori le immettono in una rete di rilevamento a doppio ramo. Un ramo elabora l’immagine a colori abituale, mentre l’altro elabora la mappa di profondità, usando lo stesso tipo di backbone neurale in entrambi i percorsi. A diversi strati intermedi, le mappe di caratteristiche dei due rami vengono cucite insieme e ulteriormente affinate. Questa fusione a metà percorso permette al modello di preservare ciò che è specifico dei segnali cromatici e di quelli di profondità, apprendendo al contempo come interagiscono. Le caratteristiche fuse poi passano a una testa di rilevamento standard che produce riquadri e etichette per gli oggetti presenti nella scena.
Cosa rivelano gli esperimenti nelle scene reali
Il team testa il loro approccio su due note collezioni di immagini. Una, chiamata COCO, contiene foto quotidiane affollate di persone, animali e oggetti. L’altra, M3FD, si concentra su scene stradali in cui vengono usate telecamere sia visibili sia all’infrarosso. Su diversi modelli di rilevamento popolari, incluse versioni leggere di YOLO e un rilevatore basato su transformer, l’aggiunta delle caratteristiche di pseudo-profondità incrementa costantemente l’accuratezza. Su COCO, il punteggio principale che misura i rilevamenti corretti migliora fino a otto punti percentuali, mentre su M3FD si osservano guadagni più modesti ma regolari. Esempi visivi mostrano contorni degli oggetti più netti, meno lampioni mancati nelle scene notturne e migliore separazione delle persone dallo sfondo ingombrato, specialmente con scarsa illuminazione.
Visione più chiara senza hardware aggiuntivo
Per il lettore, il messaggio chiave è che dare a un’IA un senso approssimativo della distanza, anche avendo solo una singola foto, può rendere più precisa la sua comprensione del mondo. Creando mappe di profondità via software e combinandole con le immagini a colori all’interno della rete neurale, questo metodo aiuta i rilevatori a trovare gli oggetti in modo più affidabile senza aggiungere nuovi sensori o modificare la fotocamera. L’approccio può essere integrato in molti modelli esistenti come semplice componente aggiuntivo, scambiando un aumento moderato del carico computazionale per prestazioni sensibilmente migliori in scene complesse del mondo reale.
Citazione: Li, SQ., Feng, W., Liu, B. et al. Pseudo-depth-based deep neural network model for object detection. Sci Rep 16, 15120 (2026). https://doi.org/10.1038/s41598-026-45310-w
Parole chiave: rilevamento oggetti, stima della profondità, visione artificiale, pseudo profondità, immagini RGB