Clear Sky Science · fr
Modèle de réseau neuronal profond basé sur la pseudo-profondeur pour la détection d’objets
Pourquoi enseigner la profondeur aux caméras est important
Les appareils photo modernes et les applications pour smartphones s’améliorent pour repérer les personnes, les voitures et d’autres objets, mais ils se basent principalement sur des images en couleurs en deux dimensions. Cet article pose une question simple au fort impact : et si l’on pouvait donner aux caméras ordinaires une notion de profondeur, comme une sensation 3D approximative, sans ajouter de capteurs supplémentaires ni de matériel coûteux ? En simulant une vue de profondeur à partir d’une seule photo et en l’alimentant dans des systèmes d’IA existants, les auteurs montrent que la détection d’objets peut devenir nettement plus précise dans des scènes quotidiennes.
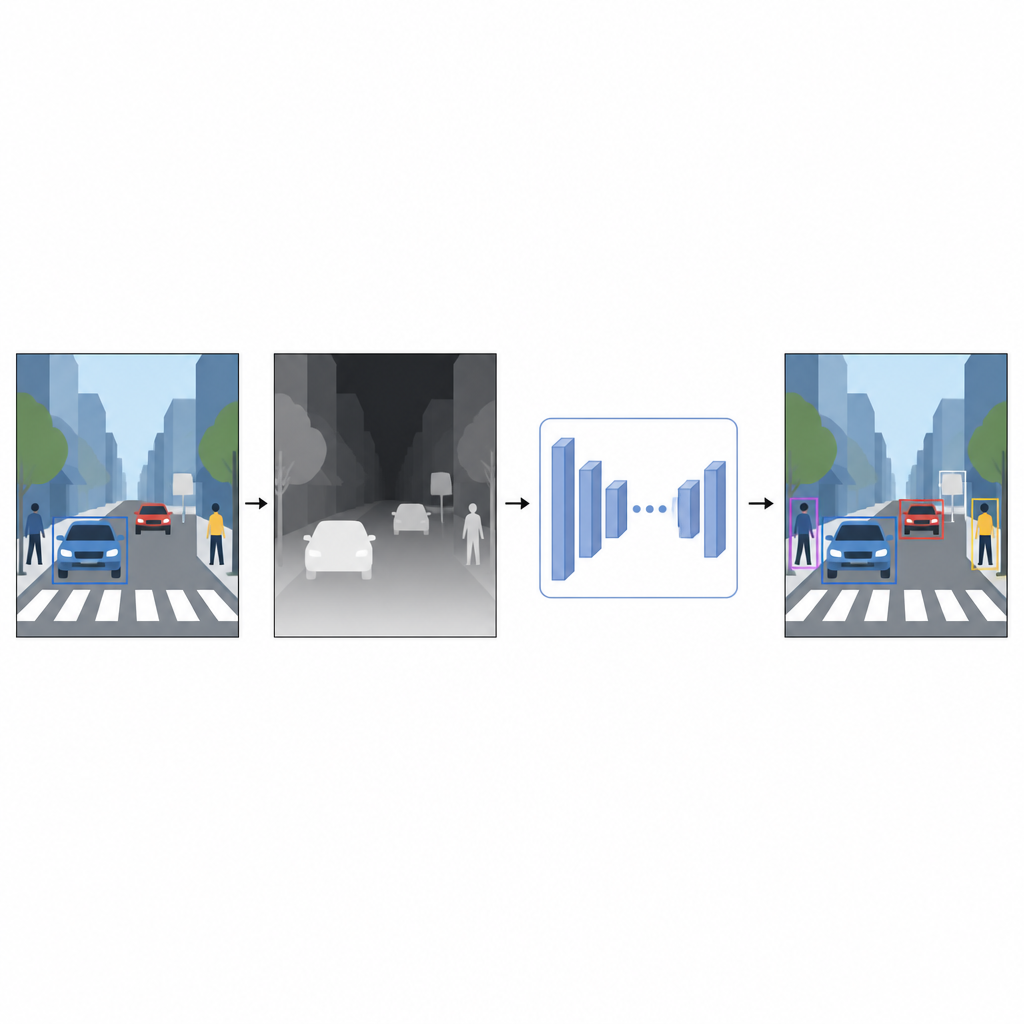
De l’image plate à une perception de la distance
Les photographies de tous les jours enregistrent la couleur et la texture mais pas la distance des éléments. Pour un ordinateur, une voiture rouge brillante et un mur rouge peuvent sembler confondants lorsqu’ils se chevauchent sur une image 2D. L’information de profondeur, même approximative, aide à séparer le premier plan de l’arrière-plan et à clarifier les contours des objets. Plutôt que de compter sur des dispositifs spéciaux comme des scanners laser ou des ensembles de caméras stéréo, les auteurs utilisent une technique appelée estimation monoculaire de la profondeur. Un modèle d’IA distinct prend une image couleur unique et prédit une carte de profondeur dense, une trame en niveaux de gris où chaque pixel suggère à quelle distance se trouve le point correspondant dans la scène.
Un capteur de profondeur virtuel fait en logiciel
Pour générer ces cartes de pseudo-profondeur, l’étude utilise un réseau d’estimation de profondeur à la pointe, entraîné en deux étapes. D’abord, il apprend sur de vastes collections de scènes synthétiques, où la profondeur parfaite est facile à obtenir. Puis il affine ses compétences sur des images réelles automatiquement annotées à l’aide d’un modèle « enseignant » puissant. Cette stratégie d’entraînement permet au réseau de profondeur de gérer des situations difficiles, y compris les faibles éclairages, les éléments transparents comme le verre et les structures fines telles que des poteaux ou des pieds de chaise. Les cartes de pseudo-profondeur résultantes fournissent des indications lisses au niveau des pixels sur la forme de la scène qui complètent la photo couleur originale.
Deux vues parallèles qui fonctionnent ensemble
Une fois que chaque image dispose à la fois d’une version couleur et d’une version pseudo-profondeur, les auteurs les injectent dans un réseau de détection à double branche. Une branche traite l’image couleur habituelle, tandis que l’autre traite la carte de profondeur, utilisant le même type d’architecture de réseau de neurones dans les deux voies. À plusieurs couches intermédiaires, les cartes de caractéristiques des deux branches sont assemblées puis affinées. Cette fusion en milieu de réseau permet au modèle de préserver ce qui est propre aux indices de couleur et aux indices de profondeur, tout en apprenant comment ils interagissent. Les caractéristiques fusionnées sont ensuite transmises à une tête de détection standard qui produit des boîtes et des étiquettes pour les objets de la scène.
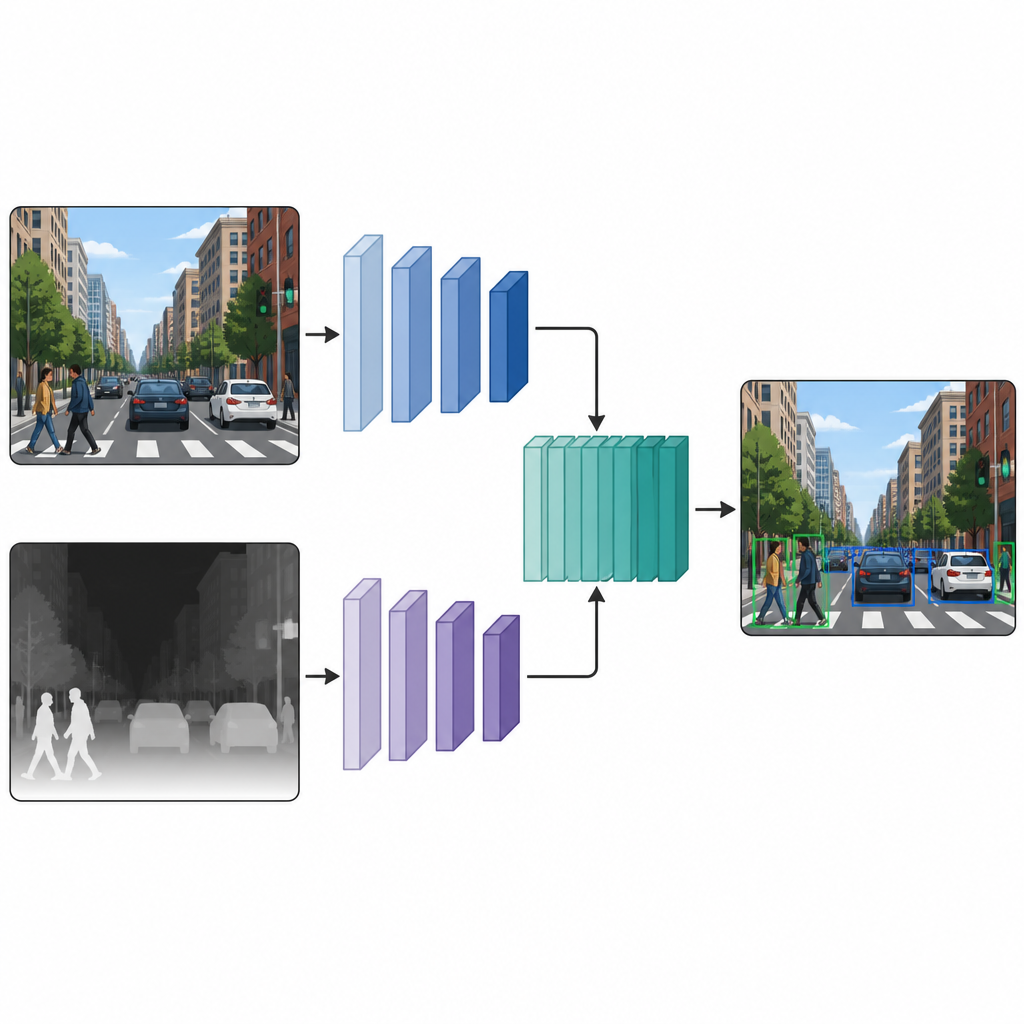
Ce que révèlent les expérimentations sur des scènes réelles
L’équipe teste son approche sur deux ensembles d’images bien connus. Le premier, appelé COCO, contient des photos quotidiennes encombrées de personnes, d’animaux et d’objets. Le second, M3FD, se concentre sur des scènes routières où des caméras visibles et infrarouges sont utilisées. Sur plusieurs modèles de détection populaires, y compris des versions allégées de YOLO et un détecteur basé sur des transformers, l’ajout de caractéristiques de pseudo-profondeur améliore systématiquement la précision. Sur COCO, le score principal mesurant les détections correctes s’améliore jusqu’à huit points de pourcentage, tandis que M3FD montre des gains plus modestes mais constants. Des exemples visuels montrent des contours d’objets plus nets, moins de lampadaires manqués dans des scènes nocturnes et une meilleure séparation des personnes d’un arrière-plan encombré, en particulier lorsque l’éclairage est médiocre.
Une vision plus claire sans matériel supplémentaire
Pour le lecteur, le message clé est que donner à une IA une notion approximative de distance, même à partir d’une seule photo, peut affiner sa compréhension du monde. En créant des cartes de profondeur par logiciel et en les combinant aux images couleur à l’intérieur du réseau neuronal, cette méthode aide les détecteurs à repérer les objets plus fiablement sans ajouter de capteurs ni modifier la caméra. L’approche peut s’intégrer à de nombreux modèles existants comme un simple ajout, échangeant une augmentation modérée du calcul contre une amélioration notable des performances dans des scènes réelles complexes.
Citation: Li, SQ., Feng, W., Liu, B. et al. Pseudo-depth-based deep neural network model for object detection. Sci Rep 16, 15120 (2026). https://doi.org/10.1038/s41598-026-45310-w
Mots-clés: détection d’objets, estimation de profondeur, vision par ordinateur, pseudo-profondeur, images RVB