Clear Sky Science · pl
Pseudo-głębia w sieci neuronowej do wykrywania obiektów
Dlaczego nauczanie aparatów o głębi ma znaczenie
Nowoczesne aparaty i aplikacje w telefonach coraz lepiej rozpoznają ludzi, samochody i inne obiekty, ale w większości analizują wyłącznie płaskie obrazy kolorowe. Artykuł stawia proste pytanie o duże konsekwencje: co gdybyśmy mogli nadać zwykłym kamerom poczucie głębi, jakby przybliżony trójwymiarowy obraz, bez dodatkowych czujników czy drogiego sprzętu? Poprzez sfingowanie widoku głębi z pojedynczego zdjęcia i wprowadzenie go do istniejących systemów AI, autorzy pokazują, że wykrywanie obiektów może stać się zauważalnie dokładniejsze w codziennych scenach.
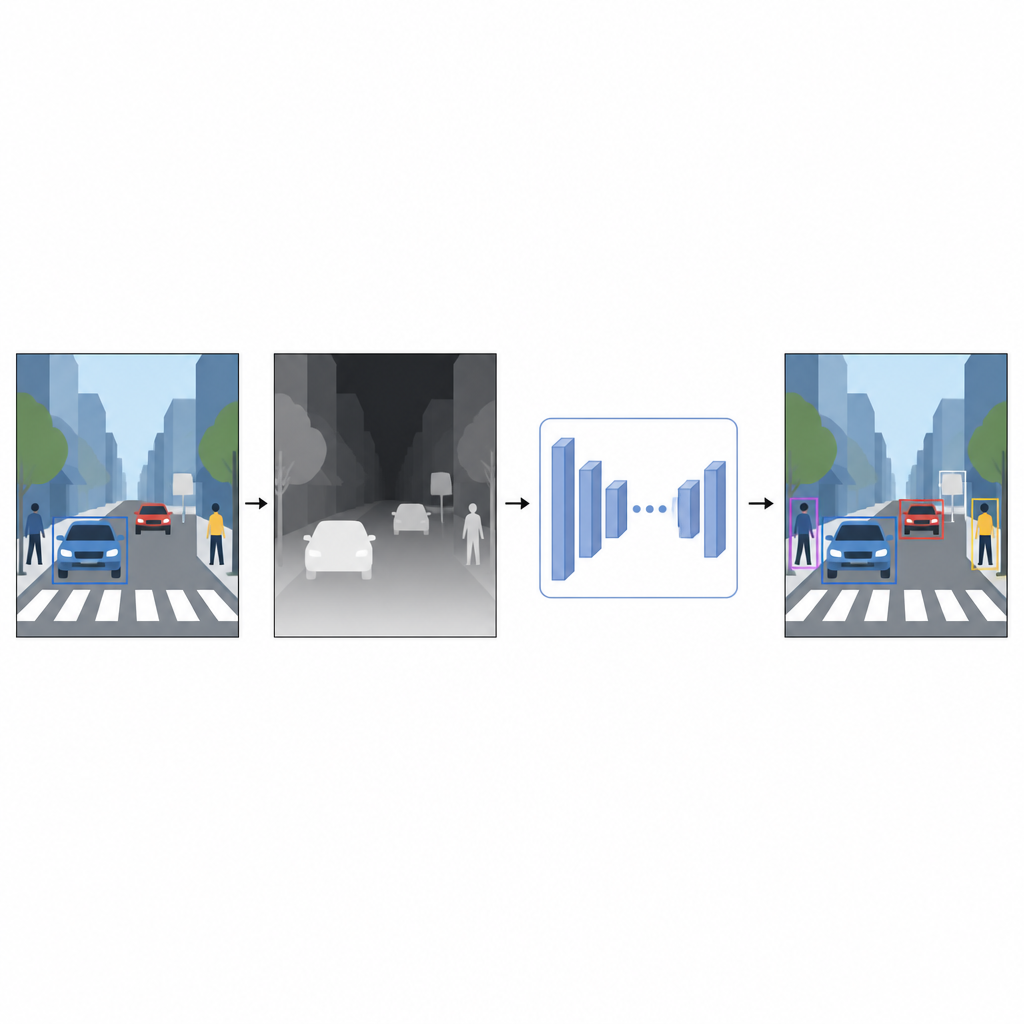
Z płaskich zdjęć do poczucia odległości
Codzienne fotografie rejestrują kolor i fakturę, ale nie informują, jak daleko znajdują się obiekty. Dla komputera jaskrawoczerwony samochód i czerwona ściana mogą wyglądać myląco podobnie, jeśli nakładają się na dwuwymiarowym obrazie. Informacja o głębi, nawet przybliżona, pomaga oddzielić pierwszy plan od tła i wyostrzyć granice obiektów. Zamiast polegać na specjalnych urządzeniach, takich jak skanery laserowe czy zestawy kamery stereo, autorzy wykorzystują technikę zwaną jednooką (monokularną) estymacją głębi. Osobny model AI przetwarza pojedynczy obraz kolorowy i przewiduje gęstą mapę głębi — szarą siatkę, w której każdy piksel wskazuje, jak blisko lub daleko może być dany punkt sceny.
Wirtualny czujnik głębi wykonany w oprogramowaniu
Aby wygenerować te pseudo-map głębi, badanie wykorzystuje nowoczesną sieć do estymacji głębi trenowaną w dwóch etapach. Najpierw uczy się na dużych zbiorach syntetycznych scen, gdzie idealna głębia jest łatwa do uzyskania. Następnie doskonali umiejętności na rzeczywistych zdjęciach automatycznie oznaczonych przez silny model-nauczyciela. Taka strategia treningowa pozwala sieci głębi radzić sobie w trudnych warunkach, w tym przy słabym oświetleniu, przezroczystych przedmiotach jak szkło oraz cienkich strukturach, takich jak słupy czy nogi krzeseł. Otrzymane pseudo-mapyt głębi dostarczają gładkich, pikselowych wskazówek o kształcie sceny, które uzupełniają oryginalne zdjęcie kolorowe.
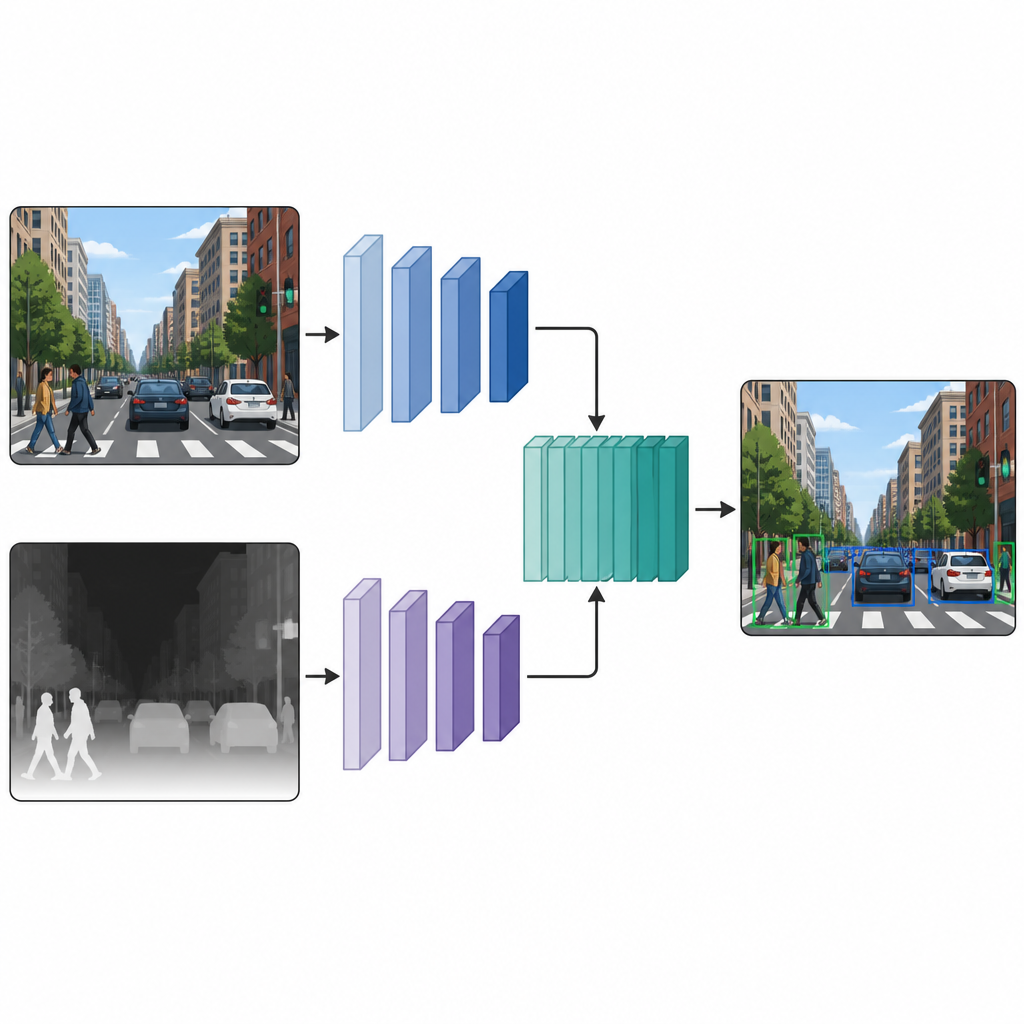
Dwa równoległe widoki pracujące razem
Gdy każde zdjęcie ma wersję kolorową i pseudo-mapę głębi, autorzy podają je do sieci detekcyjnej z dwiema gałęziami. Jedna gałąź przetwarza standardowy obraz kolorowy, podczas gdy druga przetwarza mapę głębi, używając tego samego typu architektury sieciowej w obu ścieżkach. Na kilku pośrednich warstwach mapy cech z obu gałęzi są zszywane i dalej udoskonalane. Ta fuzja w środku sieci pozwala modelowi zachować specyfikę wskazówek kolorystycznych i głębiowych, a jednocześnie nauczyć się ich wzajemnych interakcji. Zintegrowane cechy przechodzą następnie do standardowego modułu detekcji, który wypuszcza ramki i etykiety dla obiektów na scenie.
Co eksperymenty ujawniają na rzeczywistych scenach
Zespół testuje swoje podejście na dwóch dobrze znanych zbiorach obrazów. Jeden, zwany COCO, zawiera zatłoczone, codzienne zdjęcia ludzi, zwierząt i przedmiotów. Drugi, M3FD, koncentruje się na scenach drogowych, gdzie używane są zarówno kamery widzialnego świata, jak i na podczerwień. W kilku popularnych modelach detekcyjnych, w tym w lekkich wersjach YOLO i detektorze opartym na transformatorze, dodanie cech pseudo-głębi konsekwentnie podnosi dokładność. W zbiorze COCO główny wynik mierzący poprawne wykrycia poprawia się nawet o osiem punktów procentowych, podczas gdy M3FD odnotowuje skromniejsze, lecz stałe zyski. Przykłady wizualne pokazują jaśniejsze kontury obiektów, mniej pominiętych lamp ulicznych w nocnych scenach oraz lepsze oddzielenie ludzi od zagraconych teł, zwłaszcza przy słabym oświetleniu.
Wyraźniejsze widzenie bez dodatkowego sprzętu
Dla czytelników kluczowe przesłanie jest takie, że nadanie SI przybliżonego poczucia odległości, nawet gdy ma tylko jedno zdjęcie, może sprawić, że jej rozumienie świata będzie ostrzejsze. Tworząc mapy głębi programowo i łącząc je z zwykłymi obrazami kolorowymi wewnątrz sieci neuronowej, metoda ta pomaga detektorom znajdować obiekty bardziej niezawodnie, bez dodawania nowych czujników czy modyfikowania kamery. Podejście można podłączyć do wielu istniejących modeli jako prosty dodatek, wymieniając umiarkowany wzrost obliczeń na zauważalnie lepsze wyniki w złożonych, rzeczywistych scenach.
Cytowanie: Li, SQ., Feng, W., Liu, B. et al. Pseudo-depth-based deep neural network model for object detection. Sci Rep 16, 15120 (2026). https://doi.org/10.1038/s41598-026-45310-w
Słowa kluczowe: wykrywanie obiektów, ocena głębi, widzenie komputerowe, pseudo-głębia, obrazy RGB