Clear Sky Science · sv
Pseudo-djupbaserad djup neuralt nätverksmodell för objektupptäckt
Varför det spelar roll att lära kameror om djup
Moderna kameror och mobilappar blir bättre på att hitta människor, bilar och andra objekt, men de tittar oftast bara på platta färgbilder. Denna artikel ställer en enkel fråga med stor betydelse: vad händer om vi kan ge vanliga kameror en känsla för djup, som en grov 3D-uppfattning, utan att lägga till extra sensorer eller dyr hårdvara? Genom att simulera en djupvy från ett enda foto och mata in den i befintliga AI-system visar författarna att objektupptäckt kan bli märkbart mer exakt i vardagliga scener.
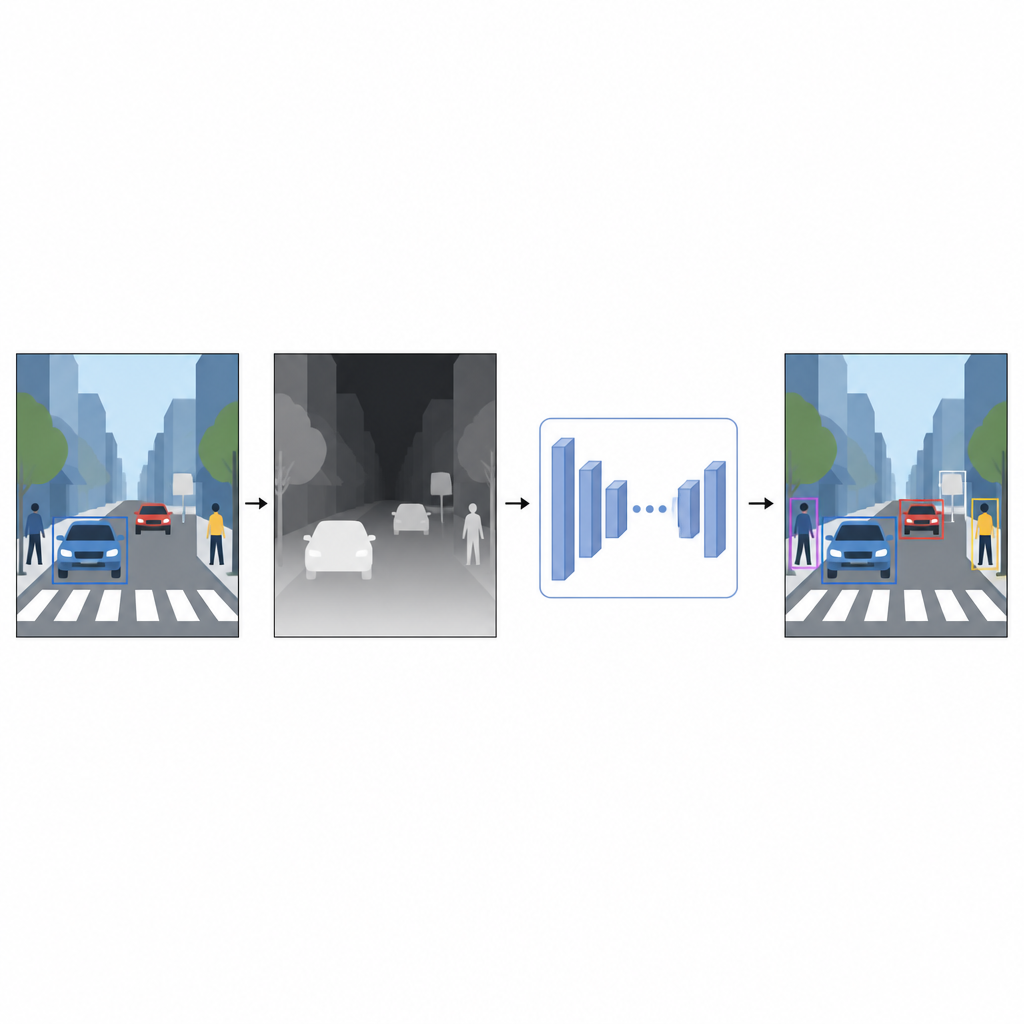
Från platta bilder till en känsla för avstånd
Vardagsfotografier registrerar färg och textur men inte hur långt bort saker är. För en dator kan en starkt röd bil och en röd vägg se förvillande lika ut när de överlappar i en 2D-bild. Djupinformation, även om den är ungefärlig, hjälper till att skilja förgrund från bakgrund och klargör objektgränser. Istället för att förlita sig på specialenheter som laserskannrar eller stereokameror använder författarna en teknik som kallas monokulär djupuppskattning. En separat AI-modell tar en enda färgbild och förutsäger en tät djupkarta, ett grått mönster där varje pixel antyder hur nära eller långt bort den punkten i scenen kan vara.
En virtuell djupsensor gjord av mjukvara
För att generera dessa pseudo-djupkartor använder studien ett topprankat djupuppskattningsnätverk som tränas i två steg. Först lär det sig från stora samlingar av syntetiska scener, där perfekt djup är lätt att få fram. Därefter förfinar det sina färdigheter på verkliga bilder som automatiskt har märkts med en kraftfull lärarmodell. Denna träningsstrategi gör att djupnätverket kan hantera svåra situationer, inklusive svagt ljus, transparenta objekt som glas och tunna strukturer såsom stolpar eller stolsben. De resulterande pseudo-djupkartorna ger mjuka, pixelnivåhintar om scenens form som kompletterar det ursprungliga färgfotot.
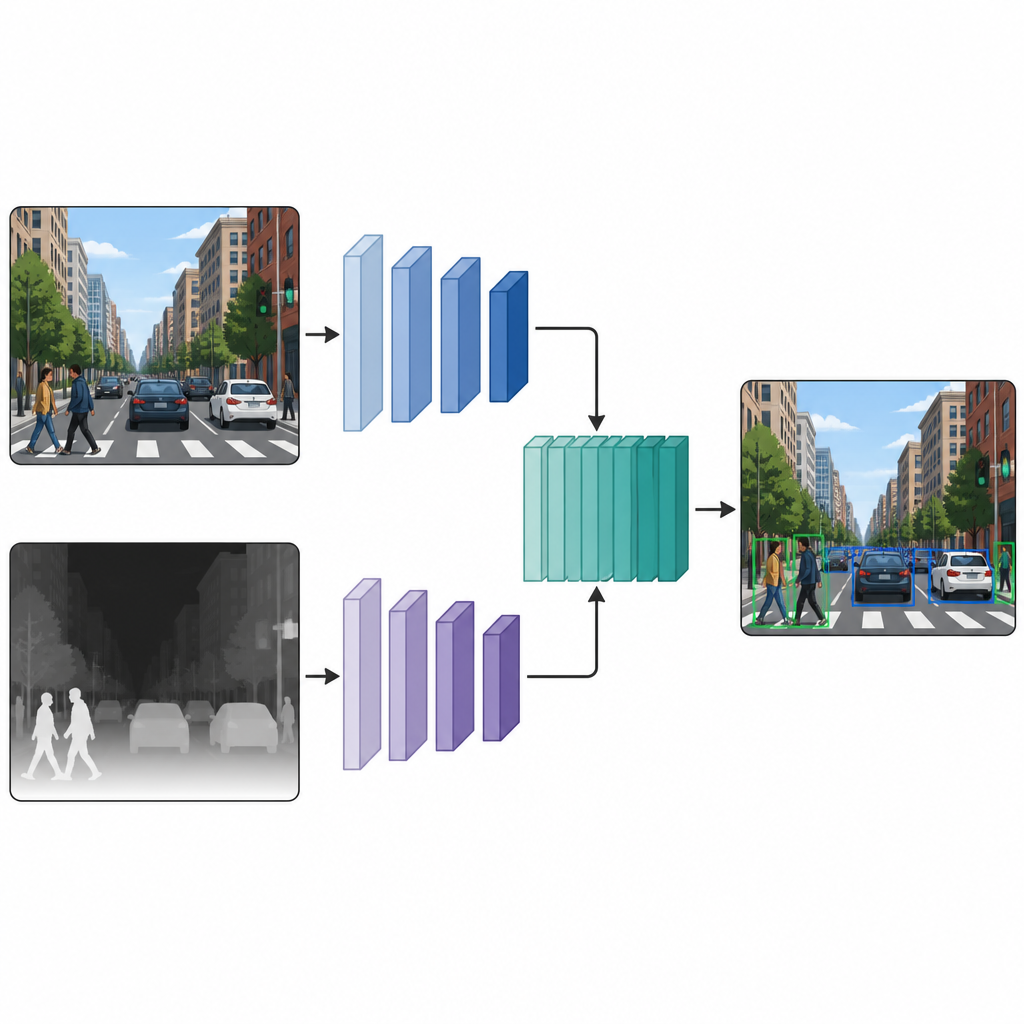
Två parallella vyer som samarbetar
När varje bild har både en färgversion och en pseudo-djupversion matar författarna in dem i ett detektionsnätverk med två grenar. En gren bearbetar den vanliga färgbilden, medan den andra bearbetar djupkartan, med samma typ av neuralt nätverksryggrad i båda vägarna. Vid flera mellanliggande lager sys funktionskartorna från de två grenarna ihop och förfinas vidare. Denna fusion i mellanstadiet låter modellen behålla vad som är unikt för färgleder och djupleder, samtidigt som den lär sig hur de interagerar. De sammansmälta funktionerna går sedan in i ett standarddetektionshuvud som ger rutor och etiketter för objekten i scenen.
Vad experimenten visar i verkliga scener
Teamet testar sin metod på två välkända bildsamlingar. Den ena, kallad COCO, innehåller trånga vardagsfoton av människor, djur och föremål. Den andra, M3FD, fokuserar på vägscener där både synliga och infraröda kameror används. Över flera populära detektionsmodeller, inklusive lätta varianter av YOLO och en transformerbaserad detektor, ökar tillägget av pseudo-djupfunktioner konsekvent noggrannheten. På COCO förbättras huvudpoängen som mäter korrekta detektioner med upp till åtta procentenheter, medan M3FD visar mer måttliga men stadiga vinster. Visuella exempel visar tydligare objektkonturer, färre missade gatlyktor i nattbilder och bättre separering av människor från röriga bakgrunder, särskilt när belysningen är dålig.
Tydligare sikt utan extra hårdvara
Huvudbudskapet för läsaren är att ge en AI en grov känsla för avstånd, även när den bara har ett enda foto, kan göra dess förståelse av världen skarpare. Genom att skapa djupkartor i mjukvara och kombinera dem med vanliga färgbilder inne i det neurala nätverket hjälper denna metod detektorer att hitta objekt mer pålitligt utan att lägga till nya sensorer eller ändra kameran. Metoden kan kopplas in i många befintliga modeller som ett enkelt tillägg och byter en måttlig ökning i beräkning mot märkbart bättre prestanda i komplexa, verkliga scener.
Citering: Li, SQ., Feng, W., Liu, B. et al. Pseudo-depth-based deep neural network model for object detection. Sci Rep 16, 15120 (2026). https://doi.org/10.1038/s41598-026-45310-w
Nyckelord: objektupptäckt, djupuppskattning, datorseende, pseudo-djup, RGB-bilder