Clear Sky Science · en
Pseudo-depth-based deep neural network model for object detection
Why teaching cameras about depth matters
Modern cameras and phone apps are getting better at spotting people, cars and other objects, yet they mostly look only at flat color images. This paper asks a simple question with big impact: what if we could give ordinary cameras a sense of depth, like a rough 3D feel, without adding extra sensors or expensive hardware? By faking a depth view from a single photo and feeding it into existing AI systems, the authors show that object detection can become noticeably more accurate in everyday scenes.
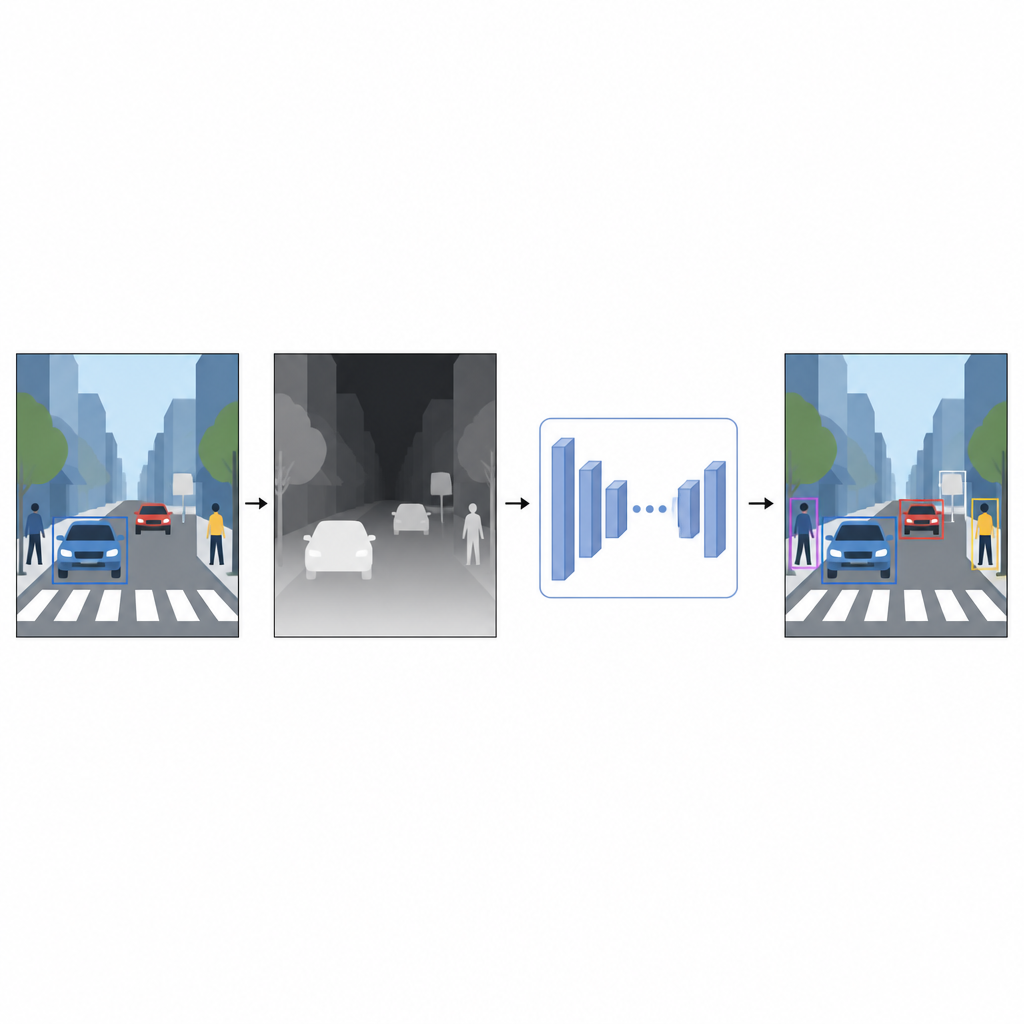
From flat pictures to a sense of distance
Everyday photographs record color and texture but not how far away things are. For a computer, a bright red car and a red wall can look confusingly similar when they overlap in a 2D image. Depth information, even if it is approximate, helps separate foreground from background and clarifies object boundaries. Instead of relying on special devices such as laser scanners or stereo camera rigs, the authors use a technique called monocular depth estimation. A separate AI model takes a single color image and predicts a dense depth map, a gray pattern in which each pixel suggests how near or far that point in the scene might be.
A virtual depth sensor made of software
To generate these pseudo-depth maps, the study uses a state-of-the-art depth estimation network trained in two stages. First, it learns from large collections of synthetic scenes, where perfect depth is easy to obtain. Then it refines its skills on real images that have been automatically labeled using a strong teacher model. This training strategy allows the depth network to handle tricky situations, including low light, transparent items like glass and thin structures such as poles or chair legs. The resulting pseudo-depth maps provide smooth, pixel-level hints about scene shape that complement the original color photo.
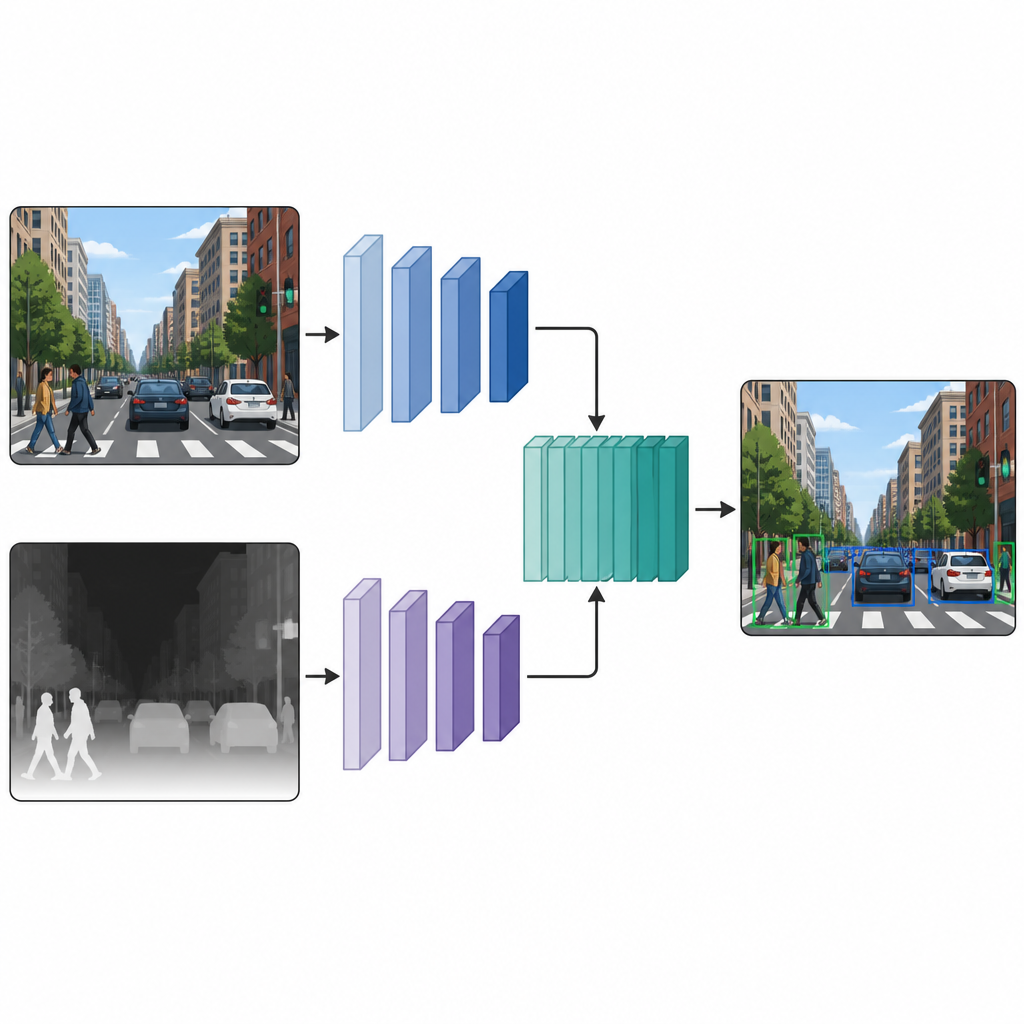
Two parallel views that work together
Once each image has both a color version and a pseudo-depth version, the authors feed them into a dual-branch detection network. One branch processes the usual color image, while the other branch processes the depth map, using the same style of neural network backbone in both paths. At several intermediate layers, the feature maps from the two branches are stitched together and further refined. This mid-stage fusion lets the model keep what is special about color cues and depth cues, while also learning how they interact. The fused features then pass into a standard detection head that outputs boxes and labels for the objects in the scene.
What the experiments reveal in real scenes
The team tests their approach on two well known image collections. One, called COCO, contains crowded everyday photos of people, animals and objects. The other, M3FD, focuses on road scenes where both visible and infrared cameras are used. Across several popular detection models, including light versions of YOLO and a transformer based detector, adding pseudo-depth features consistently boosts accuracy. On COCO, the main score that measures correct detections improves by up to eight percentage points, while M3FD sees more modest but steady gains. Visual examples show clearer object outlines, fewer missed street lamps in night scenes and better separation of people from cluttered backgrounds, especially when lighting is poor.
Clearer sight without extra hardware
For readers, the key message is that giving an AI a rough sense of distance, even when it only has a single photo, can make its understanding of the world sharper. By creating depth maps in software and combining them with regular color images inside the neural network, this method helps detectors find objects more reliably without adding new sensors or changing the camera. The approach can plug into many existing models as a simple add on, trading a moderate increase in computation for noticeably better performance in complex, real world scenes.
Citation: Li, SQ., Feng, W., Liu, B. et al. Pseudo-depth-based deep neural network model for object detection. Sci Rep 16, 15120 (2026). https://doi.org/10.1038/s41598-026-45310-w
Keywords: object detection, depth estimation, computer vision, pseudo depth, RGB images