Clear Sky Science · pt
Modelo de rede neural profunda baseado em pseudo-profundidade para detecção de objetos
Por que ensinar câmeras sobre profundidade importa
Câmeras modernas e aplicativos de celular estão cada vez melhores em identificar pessoas, carros e outros objetos, mas em sua maioria analisam apenas imagens planas em cores. Este artigo coloca uma pergunta simples com grande impacto: e se pudéssemos dar a câmeras comuns uma noção de profundidade, uma sensação 3D aproximada, sem adicionar sensores extras ou hardware caro? Ao simular uma visão de profundidade a partir de uma única foto e alimentá-la em sistemas de IA existentes, os autores mostram que a detecção de objetos pode ficar visivelmente mais precisa em cenas do dia a dia.
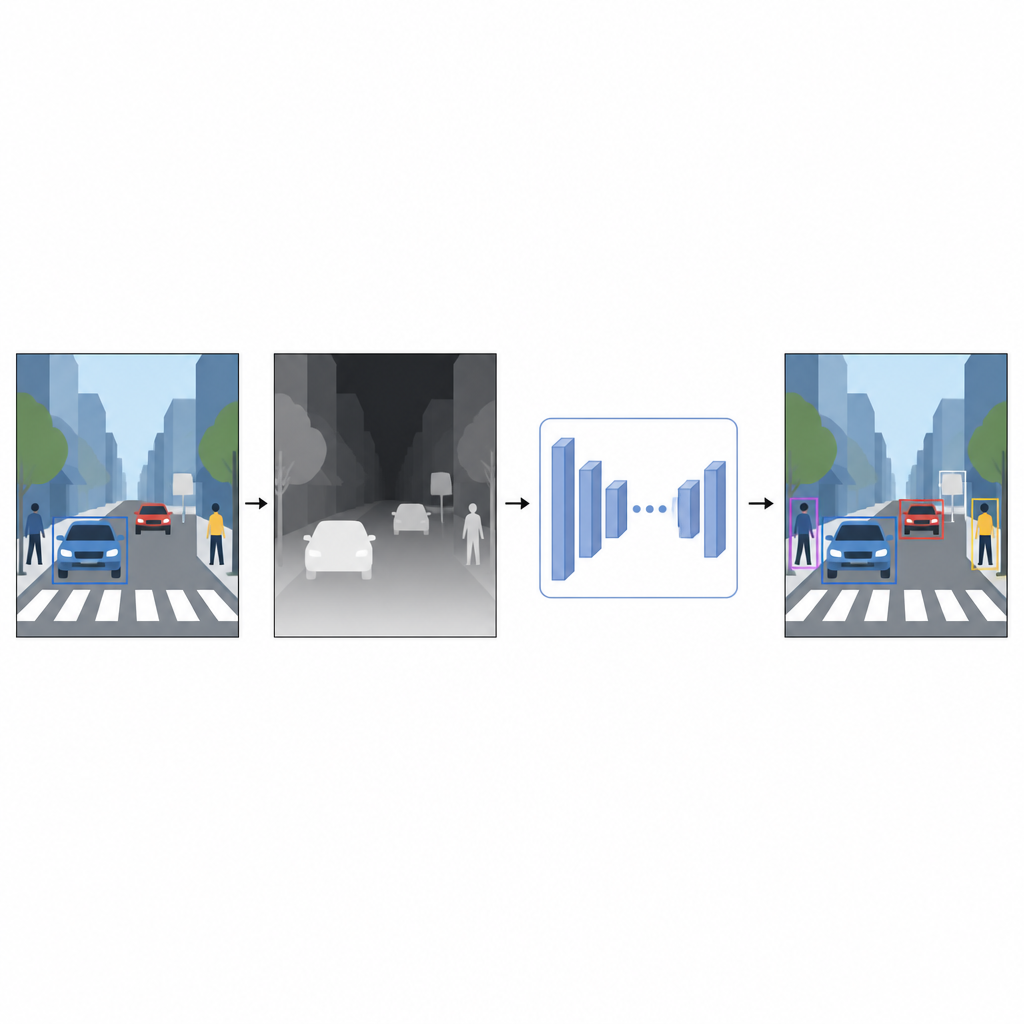
De imagens planas a uma noção de distância
Fotografias comuns registram cor e textura, mas não a distância dos elementos. Para um computador, um carro vermelho brilhante e uma parede vermelha podem parecer confusos quando se sobrepõem em uma imagem 2D. A informação de profundidade, mesmo que aproximada, ajuda a separar primeiro-plano de plano de fundo e a clarificar contornos de objetos. Em vez de depender de dispositivos especiais, como scanners a laser ou conjuntos de câmeras estéreo, os autores usam uma técnica chamada estimação monocular de profundidade. Um modelo de IA separado recebe uma imagem em cor única e prevê um mapa de profundidade denso, um padrão em tons de cinza no qual cada pixel indica quão perto ou longe aquele ponto da cena pode estar.
Um sensor de profundidade virtual feito em software
Para gerar esses mapas de pseudo-profundidade, o estudo utiliza uma rede de estimação de profundidade de última geração treinada em duas etapas. Primeiro, ela aprende com grandes coleções de cenas sintéticas, onde a profundidade perfeita é fácil de obter. Em seguida, refina suas habilidades em imagens reais que foram rotuladas automaticamente usando um modelo professor robusto. Essa estratégia de treinamento permite à rede de profundidade lidar com situações difíceis, incluindo pouca luz, objetos transparentes como vidro e estruturas finas como postes ou pés de cadeira. Os mapas de pseudo-profundidade resultantes fornecem pistas suaves ao nível de pixel sobre a forma da cena que complementam a foto colorida original.
Duas vistas paralelas que funcionam em conjunto
Uma vez que cada imagem tenha tanto uma versão em cores quanto uma versão de pseudo-profundidade, os autores as inserem em uma rede de detecção com dois ramos. Um ramo processa a imagem colorida habitual, enquanto o outro processa o mapa de profundidade, usando o mesmo tipo de backbone neural em ambos os caminhos. Em várias camadas intermediárias, os mapas de características dos dois ramos são costurados e refinados. Essa fusão em estágio médio permite que o modelo mantenha o que há de particular nas pistas de cor e de profundidade, ao mesmo tempo em que aprende como elas interagem. As características fundidas então passam para uma cabeça de detecção padrão que produz caixas e rótulos para os objetos na cena.
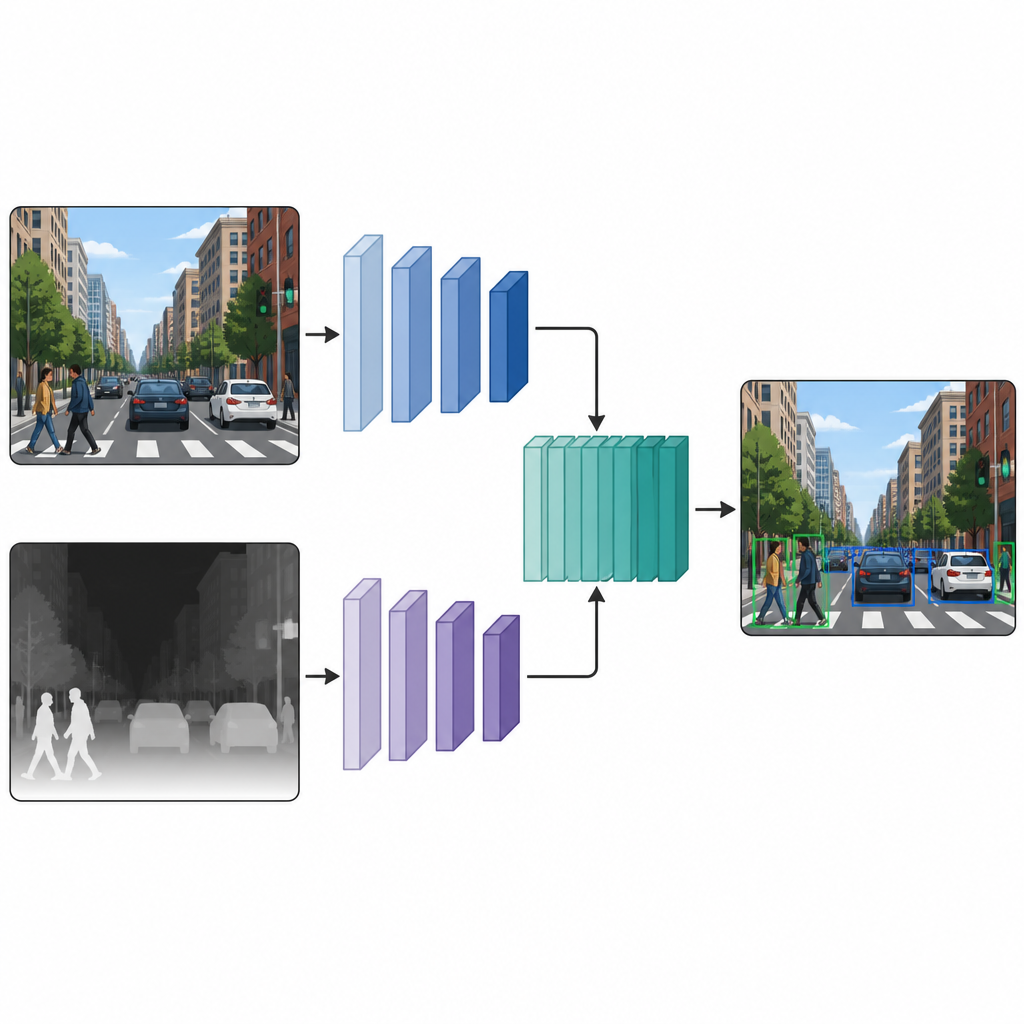
O que os experimentos revelam em cenas reais
A equipe testa sua abordagem em duas coleções de imagens bem conhecidas. Uma, chamada COCO, contém fotos cotidianas lotadas de pessoas, animais e objetos. A outra, M3FD, foca em cenas de estrada onde são usadas câmeras visíveis e infravermelhas. Em diversos modelos populares de detecção, incluindo versões leves do YOLO e um detector baseado em transformer, adicionar recursos de pseudo-profundidade aumenta consistentemente a precisão. No COCO, a principal métrica que mede detecções corretas melhora em até oito pontos percentuais, enquanto na M3FD os ganhos são mais modestos, porém constantes. Exemplos visuais mostram contornos de objetos mais nítidos, menos postes de iluminação perdidos em cenas noturnas e melhor separação de pessoas de fundos desordenados, especialmente quando a iluminação é ruim.
Visão mais clara sem hardware extra
Para o leitor, a mensagem chave é que dar à IA uma noção aproximada de distância, mesmo quando ela dispõe apenas de uma foto única, pode afiar sua compreensão do mundo. Ao criar mapas de profundidade em software e combiná-los com imagens coloridas regulares dentro da rede neural, esse método ajuda detectores a localizar objetos com mais confiabilidade sem acrescentar novos sensores ou alterar a câmera. A abordagem pode ser integrada a muitos modelos existentes como um complemento simples, trocando um aumento moderado no processamento por desempenho visivelmente melhor em cenas reais e complexas.
Citação: Li, SQ., Feng, W., Liu, B. et al. Pseudo-depth-based deep neural network model for object detection. Sci Rep 16, 15120 (2026). https://doi.org/10.1038/s41598-026-45310-w
Palavras-chave: detecção de objetos, estimação de profundidade, visão computacional, pseudo profundidade, imagens RGB