Clear Sky Science · tr
Nesne algılama için sözde-derinlik tabanlı derin sinir ağı modeli
Neden kameraların derinliği öğrenmesi önemli
Modern kameralar ve telefon uygulamaları insanları, arabaları ve diğer nesneleri tespit etmede giderek daha iyi hale geliyor, ancak çoğunlukla sadece düz renkli görüntülere bakıyorlar. Bu makale, büyük etkiye sahip basit bir soruyu gündeme getiriyor: sıradan kameralara ekstra sensörler veya pahalı donanım eklemeden kaba bir 3B hissi gibi bir derinlik duygusu kazandırabilseydik ne olurdu? Tek bir fotoğraftan sahte bir derinlik görünümü üreterek ve bunu mevcut yapay zeka sistemlerine vererek, yazarlar günlük sahnelerde nesne algılamanın fark edilir biçimde daha doğru hale gelebileceğini gösteriyor.
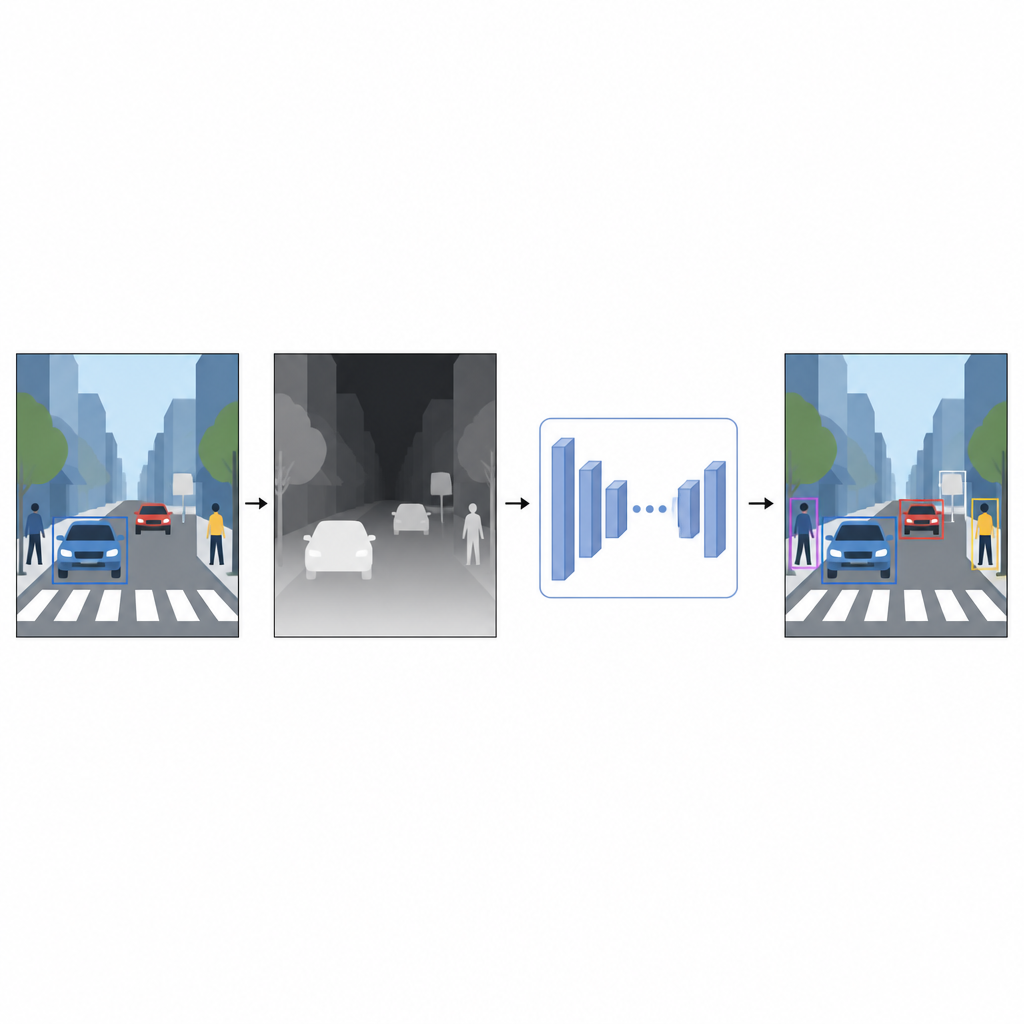
Düz resimlerden uzaklık hissine
Günlük fotoğraflar renk ve dokuyu kaydeder, ancak nesnelerin ne kadar uzakta olduğunu kaydetmez. Bir bilgisayar için parlak kırmızı bir araba ile kırmızı bir duvar, 2B görüntüde üst üste geldiklerinde kafa karıştırıcı derecede benzer görünebilir. Yaklaşık bile olsa derinlik bilgisi, ön planı arka plandan ayırmaya ve nesne sınırlarını netleştirmeye yardımcı olur. Lazer tarayıcılar veya stereo kamera düzenleri gibi özel cihazlara güvenmek yerine yazarlar tek kameralı (monoküler) derinlik tahmini adlı bir teknik kullanıyor. Ayrı bir yapay zeka modeli tek bir renkli görüntü alır ve her pikselin sahnedeki noktanın ne kadar yakın veya uzak olabileceğini önermesi için yoğun bir derinlik haritası tahmin eder.
Yazılımdan yapılmış sanal bir derinlik sensörü
Bu sözde-derinlik haritalarını üretmek için çalışma, iki aşamada eğitilen son teknoloji bir derinlik tahmin ağı kullanıyor. İlk olarak, mükemmel derinliğin kolayca elde edilebildiği büyük sentetik sahne koleksiyonlarından öğreniyor. Ardından güçlü bir öğretmen model kullanılarak otomatik etiketlenmiş gerçek görüntüler üzerinde becerilerini rafine ediyor. Bu eğitim stratejisi, derinlik ağının düşük ışık, cam gibi saydam nesneler ve direkler veya sandalye ayakları gibi ince yapılar dahil olmak üzere zor durumlarla başa çıkmasını sağlıyor. Ortaya çıkan sözde-derinlik haritaları, orijinal renk fotoğrafını tamamlayan sahne şekli hakkında düzgün, piksel düzeyinde ipuçları sağlıyor.
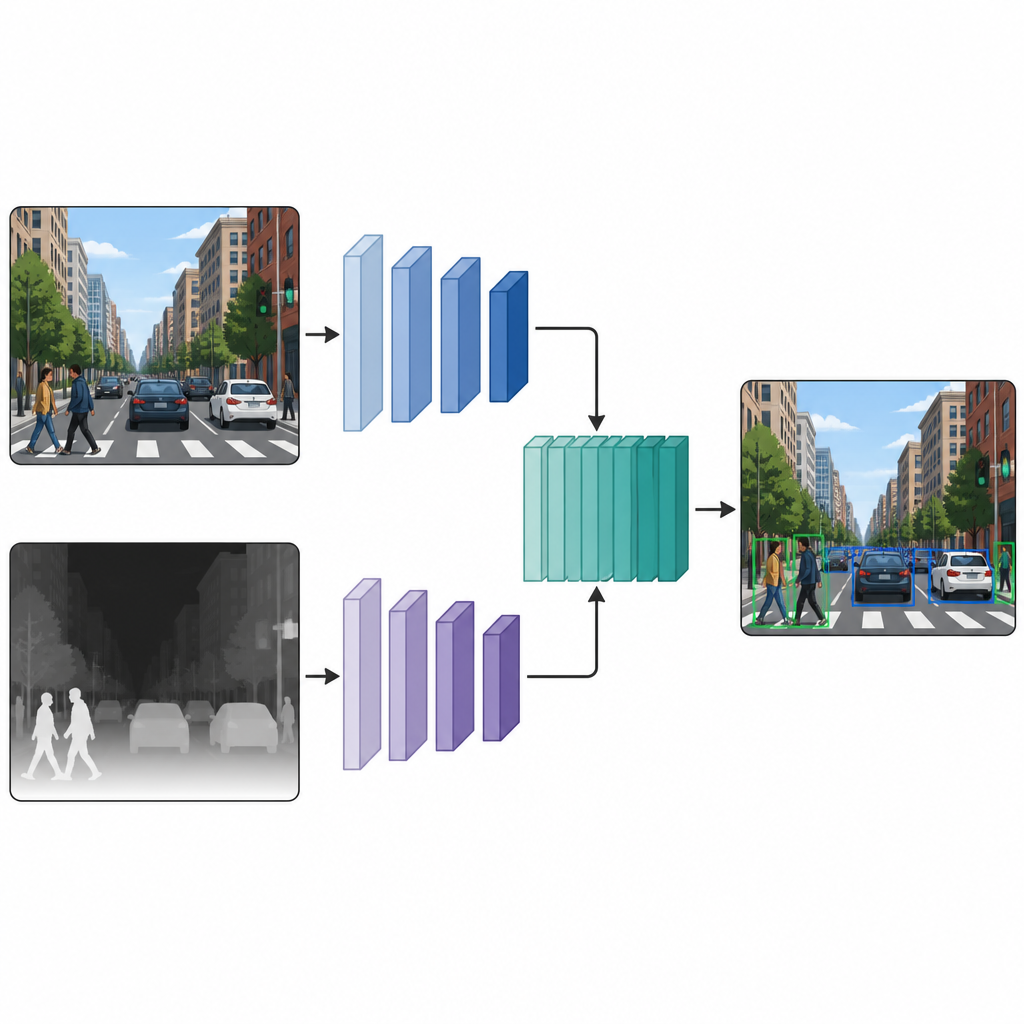
Birlikte çalışan iki paralel görüntü
Her görüntü hem renkli hem de sözde-derinlik versiyonuna sahip olduğunda, yazarlar bunları çift dallı bir algılama ağına besliyor. Bir dal tipik renkli görüntüyü işlerken, diğer dal derinlik haritasını işliyor ve her iki yol da aynı tarzda bir sinir ağı omurgası kullanıyor. Birkaç ara katmanda, iki daldan gelen özellik haritaları birleştirilip daha fazla rafine ediliyor. Bu orta aşama füzyonu modelin renk ipuçlarının ve derinlik ipuçlarının kendine özgü özelliklerini korumasına ve aynı zamanda bunların nasıl etkileştiğini öğrenmesine olanak tanıyor. Birleştirilmiş özellikler daha sonra sahnedeki nesneler için kutular ve etiketler üreten standart bir algılama başlığına aktarılıyor.
Gerçek sahnelerde deneylerin ortaya koydukları
Takım yaklaşımlarını iki iyi bilinen görüntü koleksiyonunda test ediyor. Biri COCO adlı, kalabalık günlük fotoğraflarda insanlar, hayvanlar ve nesneler içeriyor. Diğeri M3FD ise hem görünür hem de kızılötesi kameraların kullanıldığı yol sahnelerine odaklanıyor. YOLO'nun hafif versiyonları ve bir dönüştürücü tabanlı dedektör dahil olmak üzere birkaç popüler algılama modeli genelinde, sözde-derinlik özellikleri eklemek tutarlı bir şekilde doğruluğu artırıyor. COCO'da doğru algılamaları ölçen ana puan sekiz yüzdelik puana kadar iyileşirken, M3FD daha mütevazı ama istikrarlı kazanımlar görüyor. Görsel örnekler daha net nesne konturları, gece sahnelerinde daha az kaçırılmış sokak lambası ve özellikle kötü aydınlatmada kalabalık arka planlardan insanların daha iyi ayrılmasını gösteriyor.
Ek donanım olmadan daha net görüş
Okuyucular için temel mesaj, AI'ya tek bir fotoğraflık veride bile kaba bir uzaklık hissi vermenin, dünyayı anlama yetisini keskinleştirebileceği. Derinlik haritalarını yazılımla oluşturup bunları sinir ağı içinde normal renkli görüntülerle birleştirerek, bu yöntem detektörlerin yeni sensörler eklemeden veya kamerayı değiştirmeden nesneleri daha güvenilir bulmasına yardımcı oluyor. Yaklaşım, orta düzeyde bir hesaplama artışı karşılığında karmaşık gerçek dünya sahnelerinde belirgin şekilde daha iyi performans sağlayan basit bir eklenti olarak birçok mevcut modele takılabilir.
Atıf: Li, SQ., Feng, W., Liu, B. et al. Pseudo-depth-based deep neural network model for object detection. Sci Rep 16, 15120 (2026). https://doi.org/10.1038/s41598-026-45310-w
Anahtar kelimeler: nesne algılama, derinlik tahmini, bilgisayarlı görü, sözde derinlik, RGB görüntüler