Clear Sky Science · es
Modelo de red neuronal profunda basado en pseudo-profundidad para detección de objetos
Por qué importa enseñar a las cámaras sobre la profundidad
Las cámaras modernas y las aplicaciones de teléfono están mejorando en detectar personas, coches y otros objetos, pero en su mayoría solo analizan imágenes planas en color. Este artículo plantea una pregunta sencilla con gran impacto: ¿qué pasaría si pudiéramos dar a las cámaras ordinarias una sensación de profundidad, como una percepción 3D aproximada, sin añadir sensores extra ni hardware caro? Simulando una vista de profundidad a partir de una sola foto y alimentándola a los sistemas de IA existentes, los autores muestran que la detección de objetos puede volverse notablemente más precisa en escenas cotidianas.
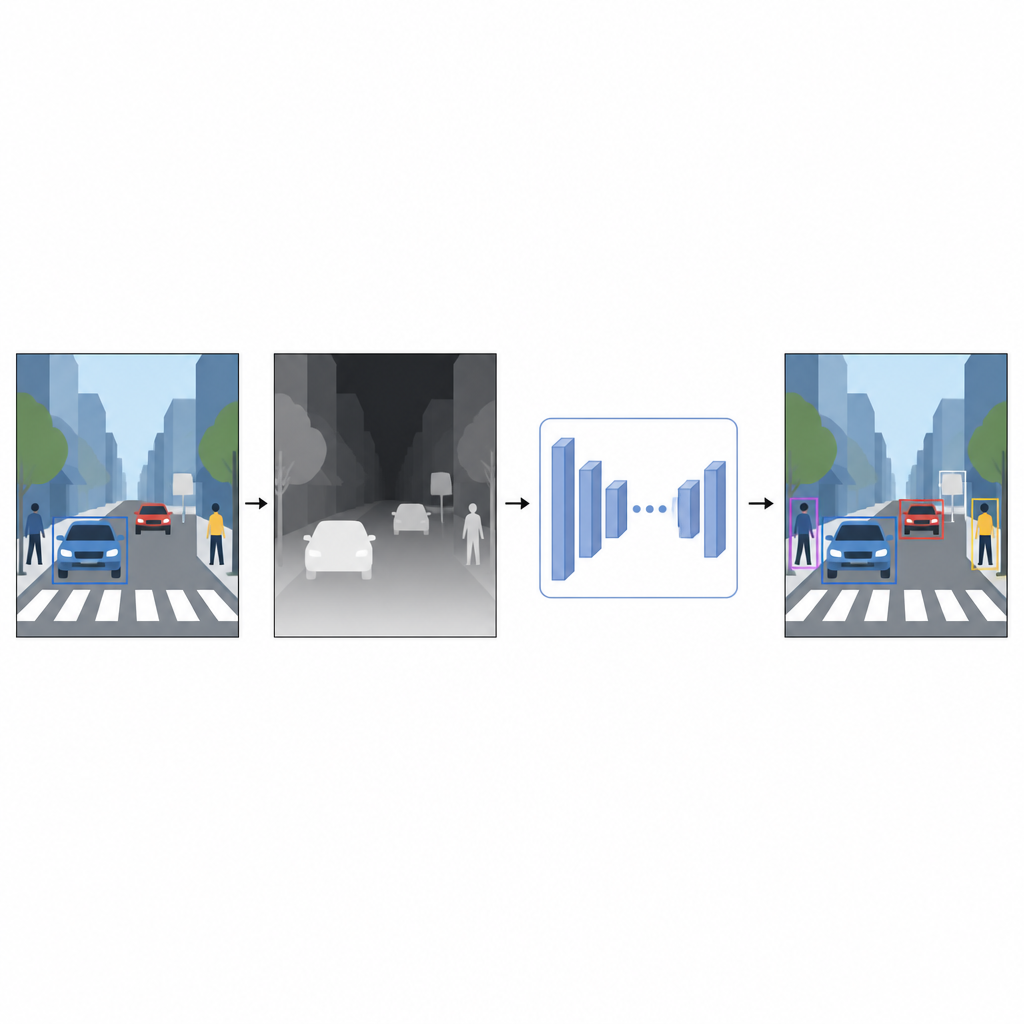
De imágenes planas a una sensación de distancia
Las fotografías habituales registran color y textura pero no la distancia a los objetos. Para un ordenador, un coche rojo brillante y una pared roja pueden parecer confusos cuando se superponen en una imagen 2D. La información de profundidad, aunque sea aproximada, ayuda a separar primer plano y fondo y aclara los contornos de los objetos. En lugar de recurrir a dispositivos especiales como escáneres láser o sistemas estéreo, los autores usan una técnica llamada estimación de profundidad monocular. Un modelo de IA independiente toma una sola imagen en color y predice un mapa de profundidad denso, un patrón en tonos grises en el que cada píxel sugiere qué tan cerca o lejos puede estar ese punto de la escena.
Un sensor de profundidad virtual hecho por software
Para generar estos mapas de pseudo-profundidad, el estudio utiliza una red de estimación de profundidad de última generación entrenada en dos fases. Primero aprende a partir de grandes colecciones de escenas sintéticas, donde la profundidad perfecta es fácil de obtener. Luego perfecciona sus habilidades con imágenes reales que han sido etiquetadas automáticamente usando un modelo profesor potente. Esta estrategia de entrenamiento permite que la red de profundidad aborde situaciones difíciles, incluyendo poca luz, objetos transparentes como el vidrio y estructuras finas como postes o patas de sillas. Los mapas de pseudo-profundidad resultantes proporcionan indicios suaves a nivel de píxel sobre la forma de la escena que complementan la foto en color original.
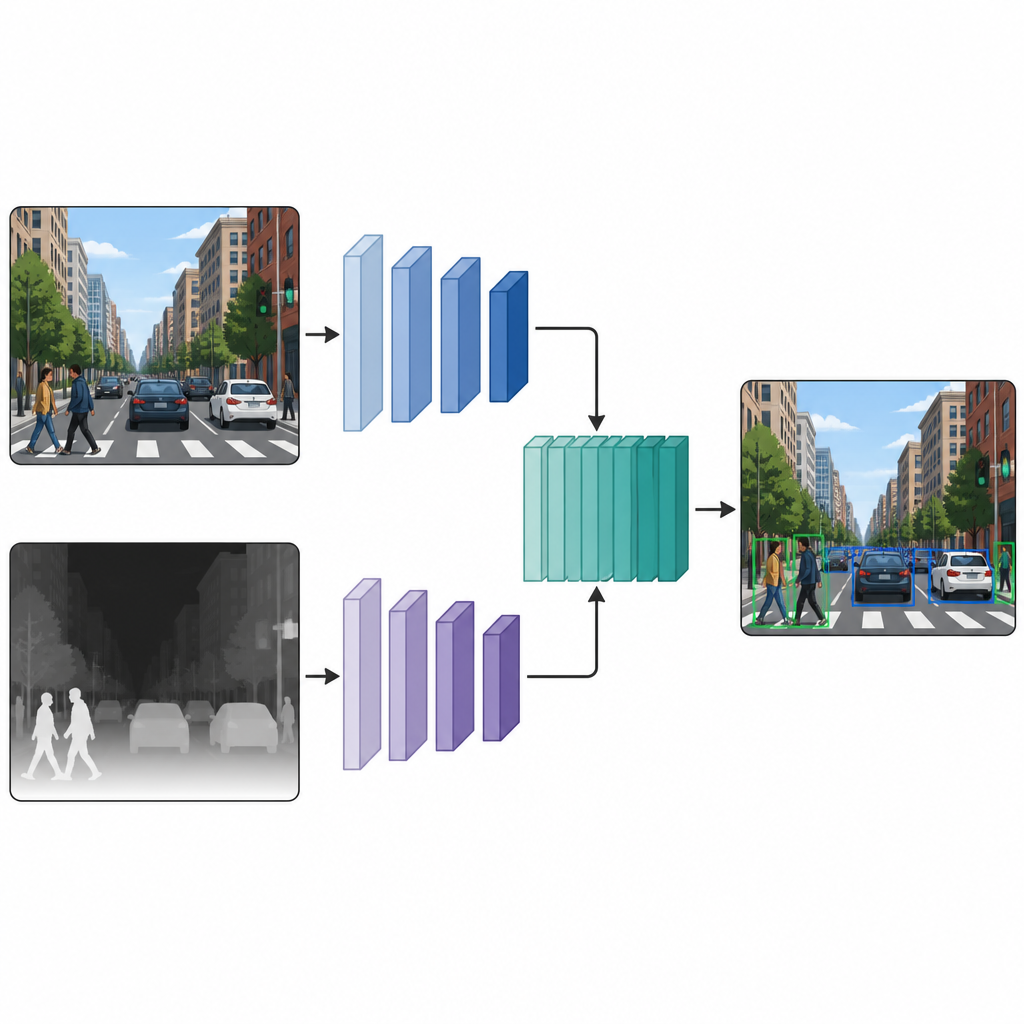
Dos vistas paralelas que trabajan juntas
Una vez que cada imagen tiene tanto una versión en color como una versión de pseudo-profundidad, los autores las introducen en una red de detección de doble rama. Una rama procesa la imagen en color habitual, mientras que la otra procesa el mapa de profundidad, usando el mismo tipo de backbone neuronal en ambos trayectos. En varias capas intermedias, los mapas de características de las dos ramas se cosen entre sí y se refinan más. Esta fusión en etapa media permite que el modelo conserve lo particular de las señales de color y de profundidad, al tiempo que aprende cómo interactúan. Las características fusionadas luego pasan a una cabeza de detección estándar que produce cajas y etiquetas para los objetos en la escena.
Qué revelan los experimentos en escenas reales
El equipo prueba su enfoque en dos colecciones de imágenes bien conocidas. Una, llamada COCO, contiene fotos cotidianas concurridas de personas, animales y objetos. La otra, M3FD, se centra en escenas viales donde se usan cámaras visibles e infrarrojas. En varios modelos de detección populares, incluidas versiones ligeras de YOLO y un detector basado en transformadores, añadir características de pseudo-profundidad aumenta la precisión de forma consistente. En COCO, la métrica principal que mide detecciones correctas mejora hasta en ocho puntos porcentuales, mientras que en M3FD se observan ganancias más modestas pero constantes. Los ejemplos visuales muestran contornos de objetos más nítidos, menos farolas perdidas en escenas nocturnas y mejor separación de personas frente a fondos abarrotados, especialmente cuando la iluminación es mala.
Una visión más clara sin hardware extra
Para el lector, el mensaje clave es que dar a una IA una sensación aproximada de distancia, incluso cuando solo dispone de una foto, puede afinar su comprensión del mundo. Al crear mapas de profundidad por software y combinarlos con imágenes en color dentro de la red neuronal, este método ayuda a los detectores a localizar objetos con mayor fiabilidad sin añadir nuevos sensores ni cambiar la cámara. El enfoque se puede integrar en muchos modelos existentes como un complemento simple, intercambiando un aumento moderado en el cálculo por un rendimiento visiblemente mejor en escenas reales complejas.
Cita: Li, SQ., Feng, W., Liu, B. et al. Pseudo-depth-based deep neural network model for object detection. Sci Rep 16, 15120 (2026). https://doi.org/10.1038/s41598-026-45310-w
Palabras clave: detección de objetos, estimación de profundidad, visión por computador, pseudo profundidad, imágenes RGB