Clear Sky Science · ru
Модель глубинно-нейронной сети с псевдоглубиной для обнаружения объектов
Почему важно научить камеры видеть глубину
Современные камеры и мобильные приложения становятся лучше в распознавании людей, автомобилей и других объектов, но в основном они анализируют только плоские цветные изображения. В этой работе поставлен простой, но важный вопрос: что, если мы могли бы дать обычным камерам ощущение глубины, не прибегая к дополнительным датчикам или дорогому оборудованию? Подделывая представление о глубине из одной фотографии и подавая его в существующие ИИ‑системы, авторы показывают, что обнаружение объектов в повседневных сценах может стать заметно точнее.
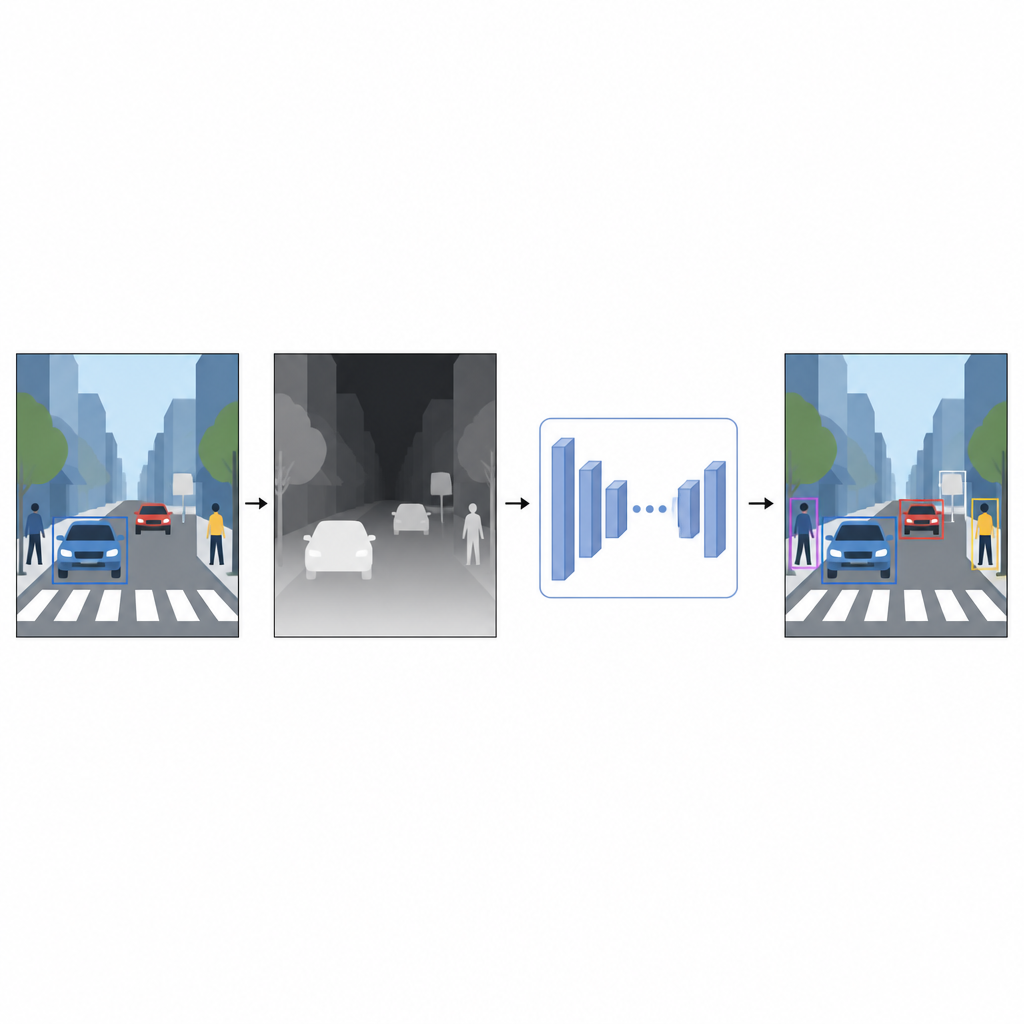
От плоских снимков к ощущению расстояния
Обычные фотографии фиксируют цвет и текстуру, но не то, на каком расстоянии находятся объекты. Для компьютера яркая красная машина и красная стена могут выглядеть путающе похоже, если они накладываются в 2D‑изображении. Информация о глубине, даже приблизительная, помогает отделить передний план от фона и уточнить границы объектов. Вместо опоры на специальные устройства, такие как лазерные сканеры или стереопары камер, авторы используют методику, называемую монокулярной оценкой глубины. Отдельная модель ИИ берёт одно цветное изображение и предсказывает плотную карту глубины — градации серого, где каждый пиксель указывает, насколько близко или далеко может быть соответствующая точка сцены.
Виртуальный датчик глубины, созданный программно
Для генерации этих псевдоглубинных карт в исследовании применяется передовая сеть оценки глубины, обученная в два этапа. Сначала она обучается на больших наборах синтетических сцен, где идеальная глубина легко доступна. Затем модель дообучается на реальных изображениях, автоматически размеченных с помощью сильной «учительской» модели. Такая стратегия обучения позволяет сети глубины справляться со сложными ситуациями, включая слабое освещение, прозрачные объекты (например, стекло) и тонкие структуры, такие как столбы или ножки стульев. Полученные псевдоглубинные карты дают плавные, поксельные подсказки о форме сцены, дополняя исходную цветную фотографию.
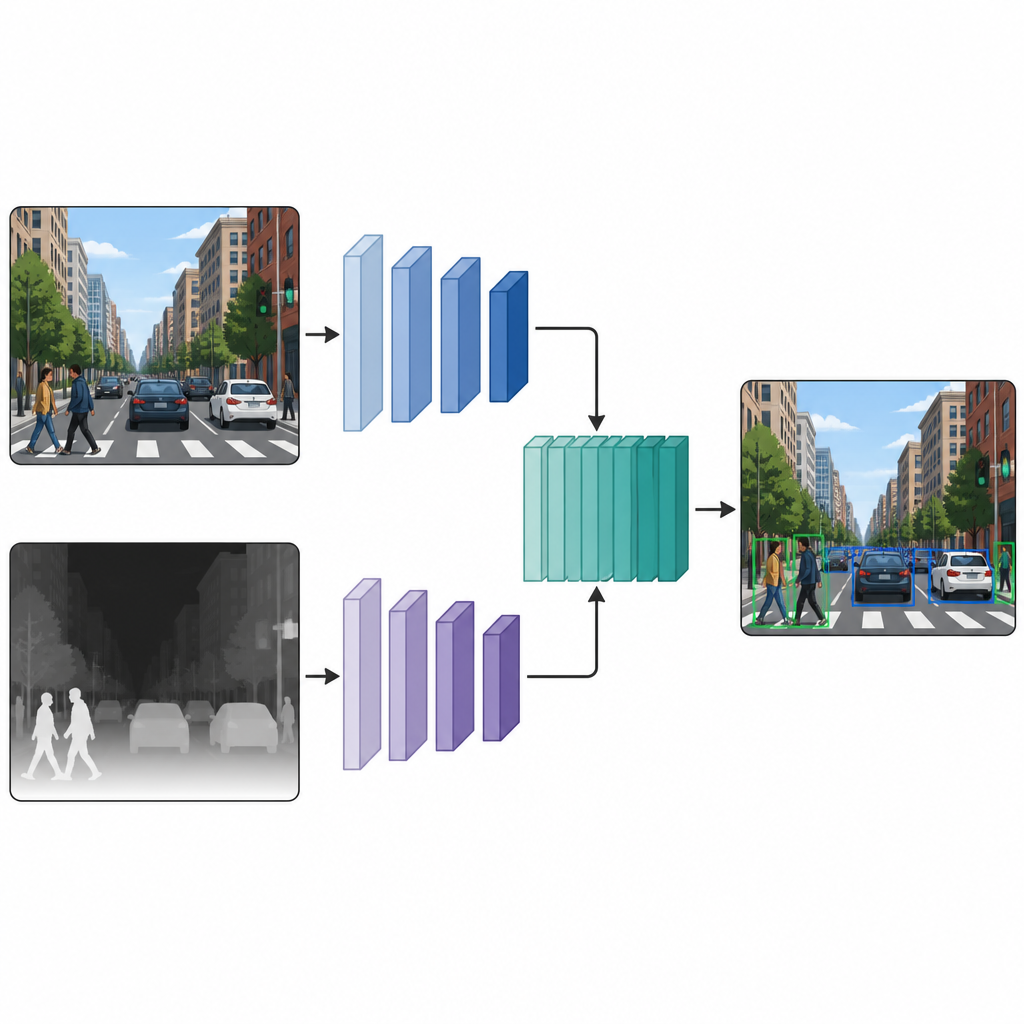
Два параллельных представления, работающие вместе
После того как каждое изображение получает и цветную версию, и псевдоглубинную карту, авторы подают их в сеть обнаружения с двумя ветвями. Одна ветвь обрабатывает обычное цветное изображение, а другая — карту глубины, при этом в обеих путях используется одинаковый тип нейронного бэкбона. На нескольких промежуточных уровнях карты признаков из двух ветвей сшиваются и дополнительно уточняются. Такое слияние на среднем этапе позволяет модели сохранить особенности цветовых сигналов и сигналов глубины, одновременно изучая их взаимодействие. Объединённые признаки затем поступают в стандартный модуль обнаружения, который выдаёт ограничивающие рамки и метки объектов на сцене.
Что показывают эксперименты на реальных сценах
Команда протестировала предложенный подход на двух хорошо известных наборах изображений. Один, называемый COCO, содержит переполненные повседневные фотографии людей, животных и предметов. Другой, M3FD, ориентирован на дорожные сцены, где используются как видимые, так и инфракрасные камеры. В различных популярных моделях обнаружения, включая облегчённые версии YOLO и детектор на базе трансформера, добавление псевдоглубинных признаков последовательно повышает точность. На COCO основной показатель правильных детекций улучшился до восьми процентных пунктов, в то время как в M3FD наблюдаются более скромные, но стабильные улучшения. Визуальные примеры показывают более чёткие контуры объектов, меньше пропущенных уличных фонарей в ночных сценах и лучшее отделение людей от загромождённого фона, особенно при плохом освещении.
Более ясное зрение без дополнительного оборудования
Для читателя ключевая мысль в том, что даже грубое ощущение расстояния, полученное из одной фотографии, может сделать восприятие мира ИИ острее. Создавая карты глубины программно и комбинируя их с обычными цветными изображениями внутри нейронной сети, этот метод помогает детекторам надёжнее находить объекты, не требуя новых датчиков или изменения камеры. Подход можно встроить во многие существующие модели как простой модуль, пожертвовав умеренным увеличением вычислений ради заметного улучшения работы в сложных реальных сценах.
Цитирование: Li, SQ., Feng, W., Liu, B. et al. Pseudo-depth-based deep neural network model for object detection. Sci Rep 16, 15120 (2026). https://doi.org/10.1038/s41598-026-45310-w
Ключевые слова: обнаружение объектов, оценка глубины, компьютерное зрение, псевдоглубина, RGB-изображения