Clear Sky Science · ja
物体検出のための擬似深度ベース深層ニューラルネットワークモデル
カメラに深度を教えることが重要な理由
現代のカメラやスマートフォンのアプリは人や車などの物体を認識する能力が向上していますが、それらは主に平面のカラー画像だけを見ています。本論文は、追加のセンサーや高価なハードウェアを導入せずに、普通のカメラに大まかな3D感覚のような深度認識を与えられたらどうなるかという単純だが影響の大きい疑問を投げかけます。単一の写真から深度ビューを擬似的に生成して既存のAIシステムに入力することで、日常のシーンで物体検出が顕著に精度向上することを著者らは示します。
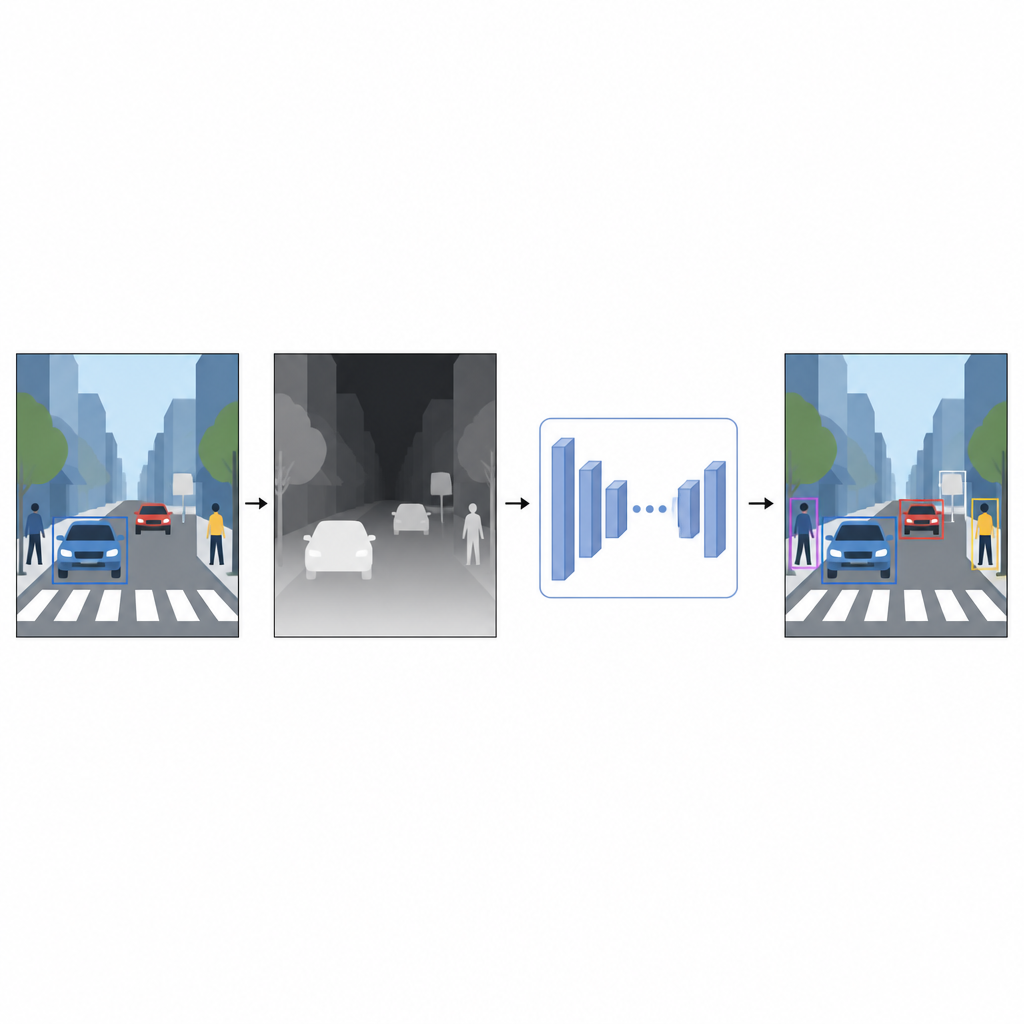
平面写真から距離の感覚へ
日常の写真は色や質感を記録しますが、物体までの距離は記録しません。コンピュータにとって、明るい赤い車と赤い壁は2D画像で重なっていると混同しやすいことがあります。たとえ概算でも深度情報があれば前景と背景を分け、物体の境界を明確にします。レーザー測距器やステレオカメラのような専用機器に頼る代わりに、著者らは単眼深度推定と呼ばれる手法を用います。別のAIモデルが単一のカラー画像から密な深度マップを予測し、各ピクセルがシーン内のその点がどれほど近いか遠いかを示す灰色のパターンを生成します。
ソフトウェアで作る仮想深度センサー
これらの擬似深度マップを生成するために、本研究は二段階で学習した最先端の深度推定ネットワークを用います。まず、完全な深度情報が容易に得られる大規模な合成シーンのコレクションで学習します。次に、強力な教師モデルを使って自動ラベリングされた実画像でスキルを洗練します。この学習戦略により、低照度、ガラスのような透明物体、ポールや椅子の脚などの細い構造物といった難しい状況に対処できます。得られた擬似深度マップは元のカラーフォトを補完する、シーンの形状に関する滑らかなピクセルレベルの手がかりを提供します。
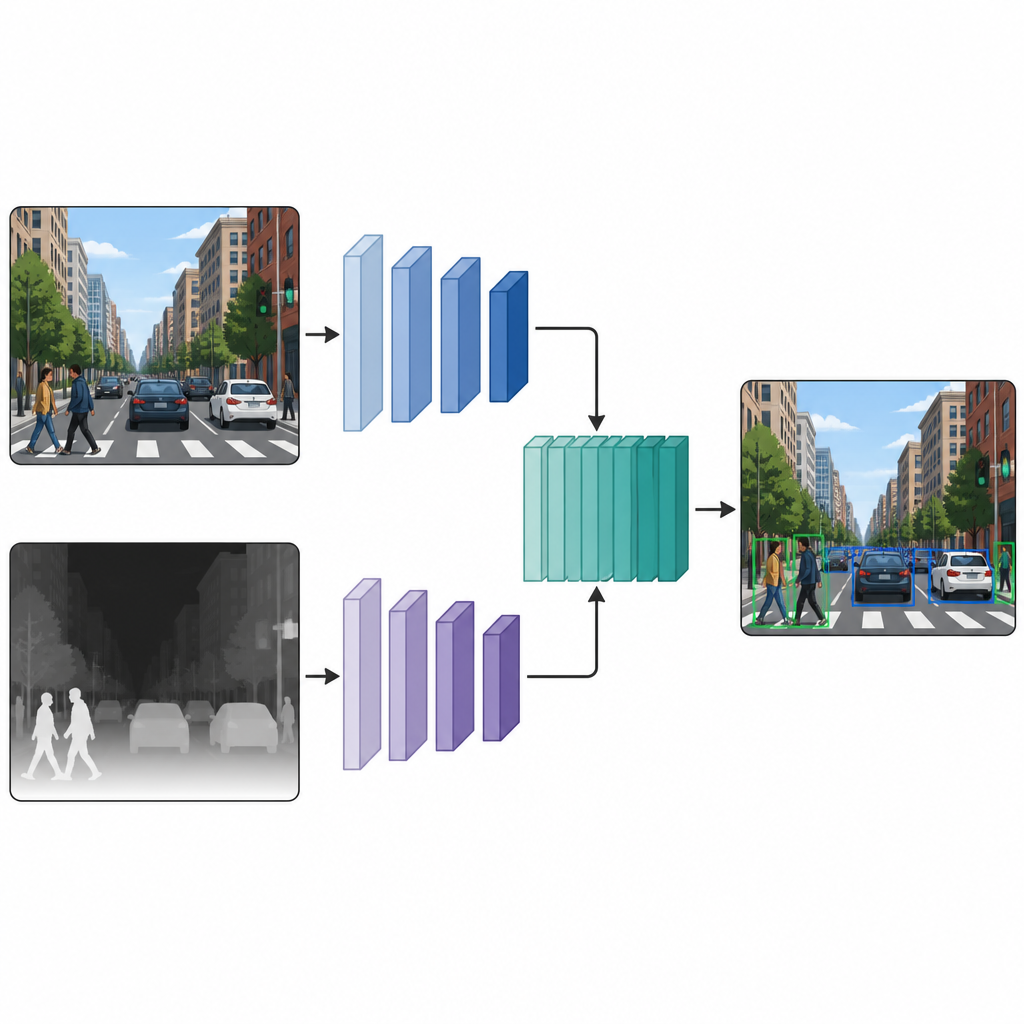
連携して機能する二つの並列ビュー
各画像にカラー版と擬似深度版が揃うと、著者らはそれらを二枝構成の検出ネットワークに入力します。片方の枝は通常のカラー画像を処理し、もう片方の枝は深度マップを処理します。両経路とも同じスタイルのニューラルネットワークのバックボーンを使います。いくつかの中間層で、二つの枝の特徴マップを縫い合わせてさらに洗練します。この中間段階での融合により、色の手がかりと深度の手がかりそれぞれの特性を保持しつつ、両者の相互作用を学習できます。融合された特徴はその後、通常の検出ヘッドに渡され、シーン中の物体のバウンディングボックスとラベルを出力します。
実世界シーンでの実験結果
研究チームはこの手法を二つのよく知られた画像データセットで評価します。ひとつはCOCOと呼ばれ、人や動物、物体が混在する日常の混雑した写真を含みます。もうひとつM3FDは、可視カメラと赤外線カメラの両方が使われる道路シーンに焦点を当てています。YOLOの軽量版やトランスフォーマーベースの検出器を含む複数の人気のある検出モデルにおいて、擬似深度特徴を追加することで一貫して精度が向上しました。COCOでは正しい検出を測る主要なスコアが最大で8ポイント改善し、M3FDでも穏やかながら着実な向上が見られました。可視化例では物体の輪郭が明瞭になり、夜間シーンで見落とされがちな街灯が減り、照明が悪い状況で特に人と雑然とした背景の分離が改善しています。
追加ハードウェアなしで視界を明瞭に
読者にとっての重要なメッセージは、たとえ単一の写真しかなくてもAIに大まかな距離感を与えることで、その世界の理解がより鋭くなるということです。ソフトウェアで深度マップを作成し、それをニューラルネットワーク内で通常のカラー画像と組み合わせることで、この手法は新たなセンサーを追加したりカメラを変更したりすることなく、検出器が物体をより確実に見つけるのを助けます。このアプローチは多くの既存モデルにシンプルな追加機能として組み込め、計算コストが中程度増える代わりに複雑な実世界シーンでの性能が目に見えて向上します。
引用: Li, SQ., Feng, W., Liu, B. et al. Pseudo-depth-based deep neural network model for object detection. Sci Rep 16, 15120 (2026). https://doi.org/10.1038/s41598-026-45310-w
キーワード: 物体検出, 深度推定, コンピュータビジョン, 擬似深度, RGB画像